理解逻辑回归:从函数设定到优化方法
需积分: 16 118 浏览量
更新于2024-07-17
收藏 1.55MB PDF 举报
"该资源是李宏毅关于逻辑回归的讲解,主要涵盖了逻辑回归的基本概念、函数设定、模型评估及优化方法。"
在机器学习领域,逻辑回归(Logistic Regression)是一种广泛使用的分类算法,尤其适用于处理二分类问题。虽然名字中含有“回归”,但它实际上是一种概率型的分类方法。逻辑回归通过将线性回归的结果输入到一个非线性的sigmoid函数中,将连续的实数值转换为介于0和1之间的概率值,从而实现对事件发生的概率预测。
**Step1: Function Set**
逻辑回归的核心在于其函数设定。模型假设输入特征`𝑥1, 𝑥2, ..., 𝑥𝑁`与输出类别`𝐶1`之间存在线性关系,用权重向量`𝑤 = [𝑤1, 𝑤2, ..., 𝑤𝑁]`和偏置项`𝑏`表示。线性部分可以表示为:`𝑧 = 𝑤∙𝑥 + 𝑏 = 𝑤1𝑥1 + 𝑤2𝑥2 + ... + 𝑤𝑁𝑥𝑁 + 𝑏`。然后,将这个线性组合输入到sigmoid函数`𝜎(𝑧)`中,得到输出概率:`𝑃𝑤,𝑏𝐶1|𝑥 = 𝜎(𝑧)`。sigmoid函数的定义为:`𝜎(𝑧) = 1 / (1 + 𝑒^(-𝑧))`,它将任何实数值映射到(0,1)区间,适合表示概率。
**Step2: Goodness of a Function**
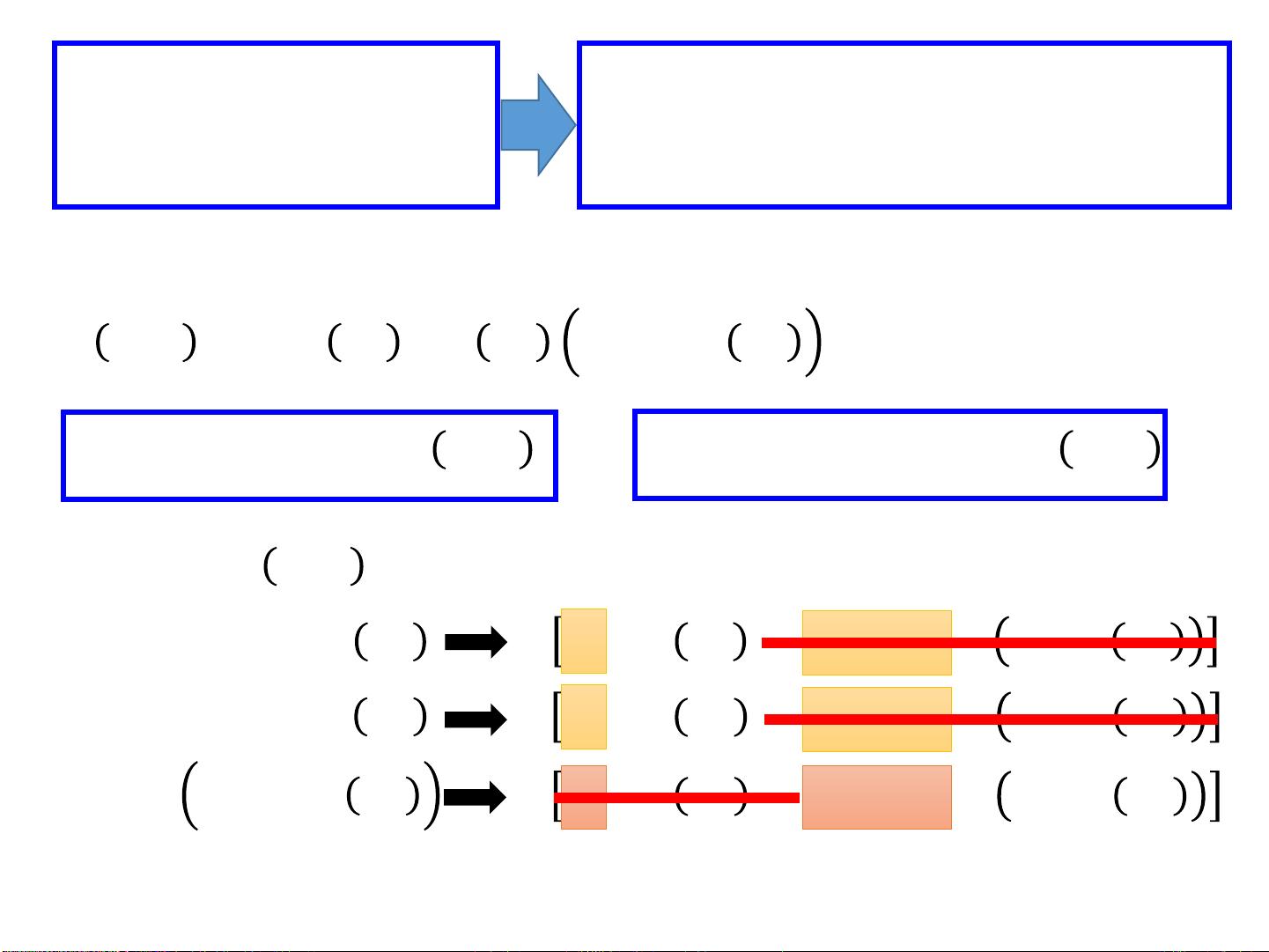
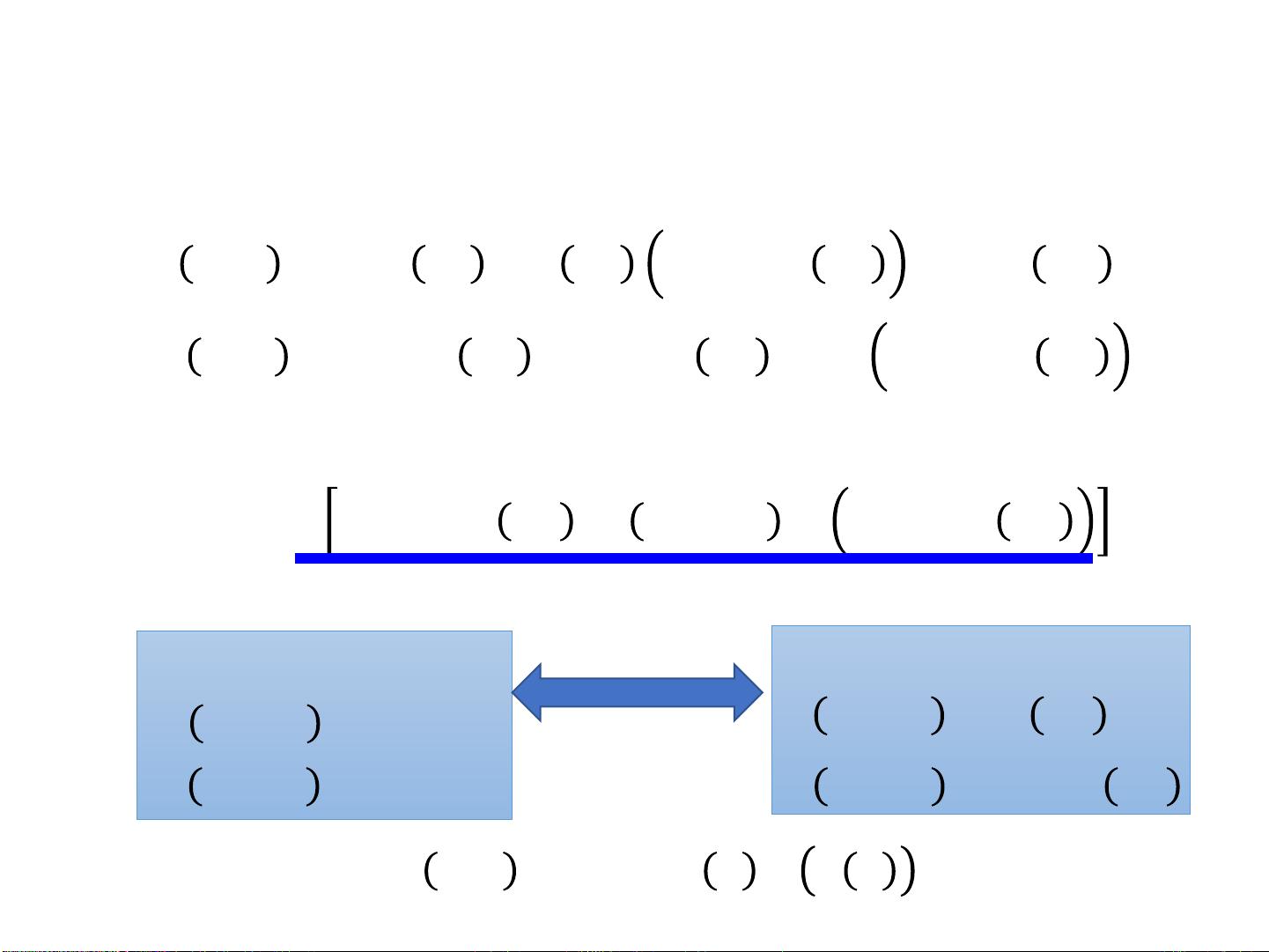
在训练逻辑回归模型时,我们需要找到一组权重和偏置,使得模型最有可能生成给定的训练数据。这通常通过最大化似然函数`𝐿𝑤,𝑏`来实现,即`𝐿𝑤,𝑏 = f(𝑤,𝑏,𝑥1) * f(𝑤,𝑏,𝑥2) * (1 - f(𝑤,𝑏,𝑥3)) * ... * f(𝑤,𝑏,𝑥𝑁)`,其中每个`𝑓(𝑤,𝑏,𝑥𝑖)`代表样本`𝑖`属于类别`𝐶1`的概率。由于似然函数通常是乘积形式,为了便于优化,我们通常取其对数似然的负值作为损失函数,即`−𝑙𝑛𝐿𝑤,𝑏`,并寻找使其最小的`(𝑤∗,𝑏∗)`。
**Step3: Optimization**
损失函数通常采用交叉熵损失(Cross-Entropy Loss),对于二分类问题,对于第`𝑖`个样本,如果其实际类别是`𝐶1`(记为`𝑦𝑖 = 1`),则损失项为`−𝑦𝑖𝑙𝑛𝑓(𝑥𝑖)`;如果是`𝐶2`(记为`𝑦𝑖 = 0`),则损失项为`−(1 − 𝑦𝑖)𝑙𝑛(1 − 𝑓(𝑥𝑖))`。整个损失函数的最小化过程可以通过梯度下降法或其他优化算法如牛顿法、拟牛顿法等进行。
在实际应用中,逻辑回归可以用于各种场景,如预测用户是否会购买某个产品、邮件是否为垃圾邮件等。它简单易用,计算效率高,但对数据的线性可分性有较高要求。当数据分布复杂时,可以考虑使用更复杂的模型,如神经网络。然而,逻辑回归仍然是理解和应用分类问题的一个重要起点。
……
: 1 for class 1, 0 for class 2
=
1
1
0
0
10
剩余30页未读,继续阅读
2023-04-17 上传
2021-09-24 上传
2021-05-07 上传
2022-07-02 上传
2023-05-25 上传
2017-11-22 上传

摩根0
- 粉丝: 8
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
