医疗云中的可搜索加密技术:一项调查
129 浏览量
更新于2024-07-15
收藏 1009KB PDF 举报
"本文是关于医疗云中可搜索加密技术的研究论文综述,探讨了如何在保护数据隐私和访问隐私的同时,实现对外包至第三方云端的医疗数据进行搜索服务。文章作者为Rui Zhang, Rui Xue和Ling Liu(IEEE会员)。"
在医疗领域,将电子健康记录(EHR)系统外包给第三方云服务已经成为一种趋势,因为它能降低前端拥有成本和IT维护负担。然而,这种外包模式也带来了数据隐私和访问隐私保护的问题。为了在云计算环境中确保医疗数据的安全,可搜索加密技术应运而生。该技术旨在使医疗服务提供者能够与授权用户共享加密数据,并允许对加密数据进行查询,同时保持数据的机密性。
可搜索加密技术的核心目标是让数据在加密状态下仍能进行有效搜索,而不泄露任何敏感信息。这涉及到两个关键能力:一是数据隐私保护,即只有授权用户可以解密并查看数据;二是访问隐私保护,这意味着云服务提供商无法获取查询的具体内容,只知道哪些数据匹配了查询条件。
文章可能深入讨论了以下几方面的内容:
1. **加密算法与数据结构**:为了实现可搜索加密,通常需要设计特定的加密算法和数据结构,如索引结构,以便在加密数据上执行高效的搜索操作。
2. **查询类型支持**:可搜索加密技术可能支持多种查询类型,包括精确匹配、范围查询、模糊查询等,以满足不同医疗应用的需求。
3. **效率与安全性权衡**:在保证安全性的前提下,如何提高查询效率是一大挑战。文章可能会分析各种技术的性能瓶颈和改进策略。
4. **隐私保护机制**:包括如何防止中间人攻击、重放攻击等,以及如何确保只有授权用户才能访问和解密数据。
5. **现有方案的优缺点**:文中可能对比分析了现有的可搜索加密方案,评估它们在实际医疗云环境中的适用性和局限性。
6. **未来研究方向**:最后,作者可能会讨论该领域的未来研究方向,如增强隐私保护、提高系统性能、适应更复杂的查询需求等。
这篇论文全面概述了医疗云中可搜索加密技术的现状、挑战和未来趋势,对于理解医疗数据安全保护的重要性,以及推动相关技术的发展具有重要意义。
1939-1374 (c) 2017 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TSC.2017.2762296, IEEE
Transactions on Services Computing
4
denote hospital 1 and h2 to denote hospital 2. The children
nodes of role nodes are medical diagnosis nodes and other
laboratory inspection and test nodes. Only these leaf nodes
contain EHR data, such as prescriptions and diagnosis and
so on. Thus, the tree has two types of nodes: leaf nodes
that contain real EHR data and the internal nodes of upper
levels that are actually indices for EHR data. The former
nodes are called data nodes, which are represented by the
rectangle, and the latter nodes are called index nodes, which
are represented by the oval. Obviously in this structure, all
data nodes are nested according to a role node, so that they
can be expediently retrieved by different roles of doctors.
In the preceding EHR data structure, the index nodes
in level 2 can be used as the keywords for search. When
the cloud finds the matched index nodes according to the
queried keywords, it returns the data nodes to the data
users. However, in such an inverted index-based structure,
not only the EHR data need to be encrypted when they
are stored in a remote healthcare cloud, but also the index
should be encrypted, since it is easy to infer sensitive
information about the patient from the index nodes. In this
paper, searchable encryption schemes are used to encrypt
the index and support search operations over encrypted da-
ta. The encryption scheme used to encrypt EHR data can be
any secure searchable encryption scheme. The data owner
can choose different encryption schemes based on different
healthcare application scenarios and their respective privacy
requirements.
In the rest of this paper, we let D = {d
1
, d
2
, · · · , d
m
}
denote the set of EHR data to be stored in a third party and
possibly untrusted healthcare cloud, where |D| = m is the
total number of EHR data. According to the preceding EHR
data structure, each EHR data d
i
is indexed by one or more
keywords. Let I = {w
1
, w
2
, · · · , w
n
} be the index in D,
where |I| = n is the total number of keywords. D
i∈[n]
⊆ D
denotes the set of EHR data are indexed by keyword w
i
.
The keywords and the sets of EHR data are respectively
encrypted by encryption algorithms Enc and E, and are
stored in the healthcare cloud. Note again that Enc and E are
different encryption schemes: Enc is a searchable encryption
scheme and E can be any secure encryption scheme chosen
by the data owner.
2.2 Privacy Requirements in SE Schemes
Intuitively, an SE scheme is secure if the server learns
nothing about the query as well as the documents except
the encrypted query results [1], [4], [5], [6]. In this section,
we discuss in detail the specific privacy requirements for
index-based data storage structures, where the cloud server
searches over a set of searchable index instead of searching
on encrypted data directly.
Data privacy is a basic requirement for the EHR data such
that the outsourced EHR data should not be revealed in
any form to any unauthorized parties, including the cloud
service providers. Typically, it can be guaranteed by the
encryption algorithms. The user who has the secret key can
effectively decrypt the encoded EHR data after retrieving
them from the cloud server. The encryption based protection
needs to consider the following three types of requirements
for privacy protection: (i) leakage due to search keywords,
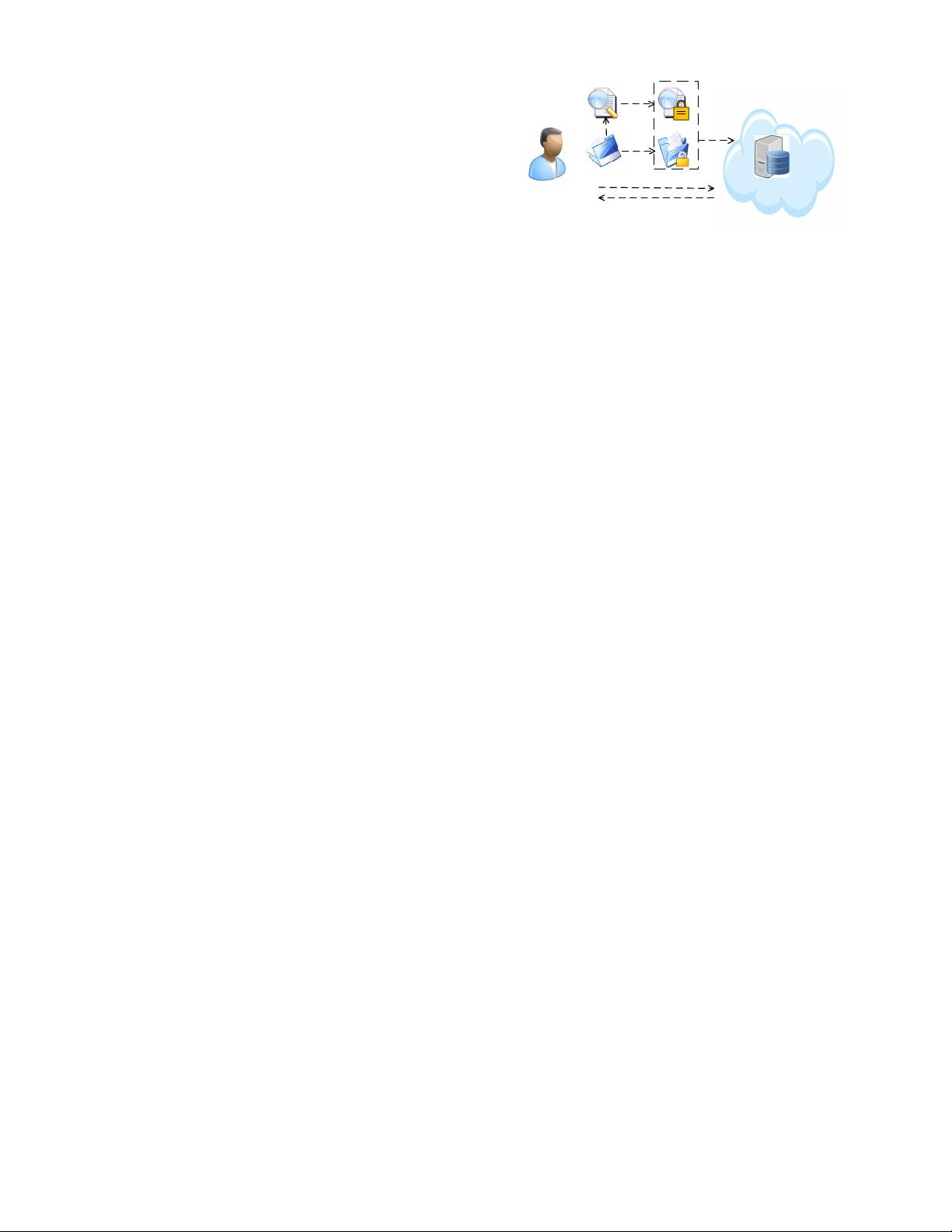
Patient
Encrypt
Search Token
Cloud
Result
Upload
Encrypt
Index
SSE
Fig. 3. The First Scenario: Owner as Reader/Writer
(ii) leakage due to search patterns, and (iii) leakage due to
access patterns.
Privacy of search keywords. This is related to plaintext
privacy: if the cloud server deduces any association between
frequent keywords and encrypted dataset from the index,
it may learn the main content of the EHR data. Therefore,
searchable index should be constructed in such a way that
prevents the cloud server from performing such kind of as-
sociation attacks. This kind of security is also called security
against chosen keyword attack (CKA). In an SE scheme, the
randomness of encrypted index guarantees to prevent such
attacks from the cloud server.
Privacy of search patterns. Data users usually prefer
to keep their query from being exposed to others, i.e.,
the keyword indicated by the corresponding token. In the
literature [7], [8], [9], [10], this kind of leakage is called
search pattern. Namely search patterns reveal whether the
same search was performed in the past or not. Accessing
the search pattern allows the server to use statistical analysis
and determine information about the query keywords. Us-
ing deterministic trapdoors directly leaks the search pattern.
Existing randomized SE schemes use randomly generated
tokens to guarantee the privacy of a user’s search pattern.
This security notion of randomized SE schemes is called
predicate privacy [6]. Note that randomizing token generation
algorithm only contributes to defend outside adversaries
of the cloud server but not inner adversaries (e.g., cloud
administrators), because the entry of index touched in
each search process discloses the search pattern as well.
A possible approach to reduce this leakage is to re-order
the keywords and re-generate the index periodically, say
semimonthly or monthly.
Privacy of access patterns. Besides the above privacy
requirements, we note that the sequence of search outcomes
of most SE constructions will likely reveal the information
of the keywords since the cloud server will always return
the same document set for the same queried keyword. This
kind of leakage is referred to as access pattern [7]. Access
pattern refers to the information that is implied by the
query results. Only ORAM can hide access patterns. But
ORAM is computationally intensive and do not scale well
for real world datasets. In practice, one may reduce (but not
eliminate) the leakage of access patterns. For example, one
could randomly insert fake documents in the bitmaps [11].
In this paper, we focus on the techniques for ensuring
plaintext privacy against any adversary and predicate privacy
against outsider adversaries of the cloud server. The above-
mentioned techniques can be combined with the four types
of SE schemes to reduce search and access pattern leakage
剩余17页未读,继续阅读
2021-01-14 上传
2021-02-11 上传
2021-02-09 上传
2021-02-20 上传
2021-02-08 上传
2021-02-22 上传
2021-02-09 上传
2021-02-11 上传
2021-02-22 上传

weixin_38525735
- 粉丝: 3
- 资源: 881
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
