Hadoop分布式框架搭建教程
需积分: 15 130 浏览量
更新于2024-07-09
收藏 6.05MB DOC 举报
"Hadoop搭建教程涉及Linux系统安装配置、Hadoop单例和伪分布式模式搭建、虚拟机克隆与网络配置、集群时间同步、Hadoop集群模式部署以及MapReduce案例应用,适合学习Hadoop分布式计算框架的学生。实验要求至少8GB内存和500GB硬盘的电脑。Hadoop是Apache基金会开发的分布式处理框架,广泛应用于国内外各大互联网公司,其核心包括高可靠的HDFS和分布式计算框架MapReduce,两者分别负责大数据的存储和计算。"
在深入理解Hadoop搭建过程前,我们需要先掌握一些预备知识。Hadoop是一个开源的分布式计算平台,它最初源于Google的GFS和MapReduce论文,旨在解决大数据处理的挑战。Hadoop允许在廉价硬件上构建大规模的数据处理系统,提供高可用性和高容错性。
0.1 实验内容概述
实验主要分为以下几个部分:
1. **Linux系统安装及配置**:Hadoop通常在Linux环境下运行,因此需要熟悉Linux基础操作,包括系统的安装、用户管理、文件系统管理和网络配置等。
2. **Hadoop单例模式搭建**:在单台机器上启动Hadoop,用于初步理解和测试Hadoop的基本功能。
3. **Hadoop伪分布式模式搭建**:模拟多节点环境,所有Hadoop进程运行在同一台机器的不同Java进程中,便于调试和学习。
4. **虚拟机克隆及相关网络配置**:通过虚拟机克隆构建多节点环境,学习如何配置网络以使各节点之间能相互通信。
5. **集群时间同步**:在分布式环境中,时间同步对于确保数据一致性至关重要,可以通过NTP服务实现。
6. **Hadoop集群模式部署**:在多台物理或虚拟机上部署Hadoop,形成真正的分布式集群。
7. **MapReduce案例应用**:学习编写和运行MapReduce程序,处理实际问题。
0.2 实验目标
实验的目标在于提升学生的以下能力:
- 理解Hadoop的背景和价值,了解其在大数据处理中的地位。
- 掌握Linux操作系统的基本操作,包括安装和管理。
- 学会Hadoop的三种运行模式:本地模式、单例模式和分布式模式。
- 理解MapReduce的编程模型,能编写简单的MapReduce程序并进行执行。
- 掌握分布式集群的部署和管理。
0.3 Hadoop核心组件
Hadoop的核心由两部分组成:
- **HDFS**:分布式文件系统,为大数据提供高可用、高扩展性的存储。它将大文件分割成块,并在多台机器上复制,保证数据的冗余和可靠性。
- **MapReduce**:分布式计算框架,负责处理HDFS中的数据。Map阶段将数据分片并进行本地化处理,Reduce阶段聚合结果。MapReduce简化了编写处理大量数据的应用程序的过程。
Hadoop的意义在于,它使得处理PB级别的数据成为可能,而且可以在普通硬件上运行,降低了大数据处理的门槛。此外,Hadoop的生态系统还包括HBase、Hive、Pig、Zookeeper等工具,它们共同构成了一个完整的数据处理解决方案。
在实际搭建Hadoop过程中,需要关注的问题包括环境变量配置、配置文件的修改(如hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等)、数据目录的设置以及启动和停止服务的命令。对于初学者,理解这些概念和步骤是成功搭建Hadoop集群的关键。同时,通过MapReduce的实际案例,可以更好地理解分布式计算的工作流程,为后续的大数据分析工作打下坚实的基础。
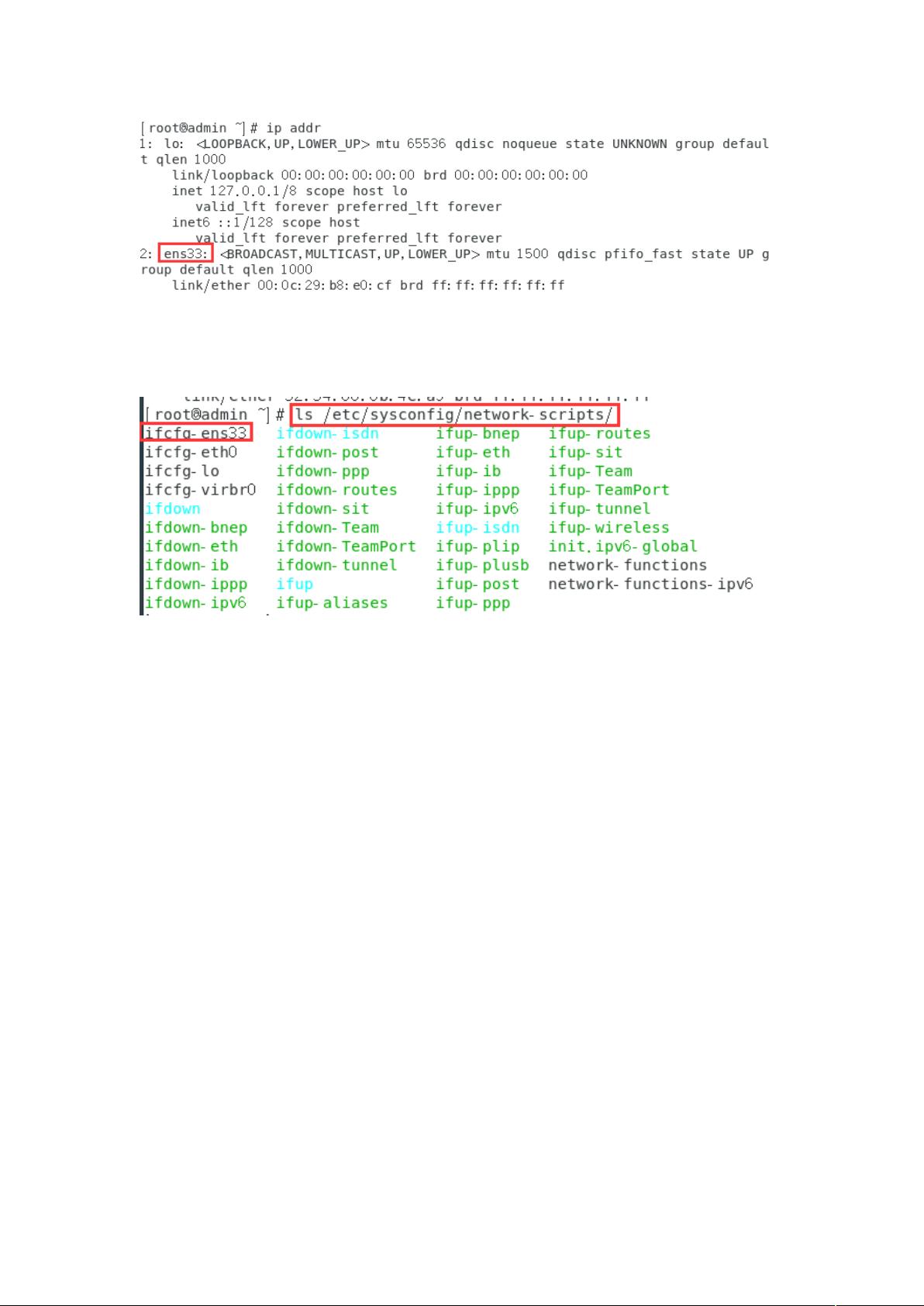
(:)输入 33!AB31(3看到网卡 信息的配置文件
名叫做 ..B
()输入 33!AB31(3..B查看,可以发
现虽然 <'#'C,但是 %<'C(若使用 命令可以
查出 下 有值(即 ?# 地址),则下面 ,D 步纯属实验性质可忽视,
直接开始第 E 步;没有的话需要执行 ,D 步)
( , ) 输 入 + 33!AB31(3..B 将
%<'C 修改为 !,修改完毕后, 一下看看,编辑完成后,保存并
退出(先按 = 键,然后输入:1F 即可保存并退出)
()现在重启网络服务: +1(
(D)重启完成后,输入 看到分配到的地址是 4G:-4D-4:E-4:


剩余63页未读,继续阅读
2021-10-05 上传
2023-03-07 上传
2021-09-29 上传
2020-04-01 上传
2021-01-08 上传

飞翔吧!小火龙
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
