掌握R语言进行预测分析
需积分: 9 116 浏览量
更新于2024-07-21
收藏 3.96MB PDF 举报
"Learning Predictive Analytics with R" 是一本由PACKT出版于2015年的图书,旨在帮助读者掌握使用R语言进行预测性分析的技能。书中涵盖了数据可视化和预测分析的关键工具,适合想要在R环境中探索数据知识的读者。
这本书深入浅出地介绍了R语言在数据分析领域的应用,特别强调了无监督学习和监督学习这两种主要的数据学习方式。无监督学习主要涉及数据结构的自动提取,而监督学习则利用带有标签的数据来学习目标属性的关系或评分。R语言凭借其丰富的标准和前沿统计功能,能有效挖掘隐藏在大量数据中的重要信息。
在内容部分,作者Eric Mayor通过实例和易懂的指导,让读者能够掌握R中的关键数据挖掘技术。读者将学习如何使用R进行数据预处理、特征工程、模型构建、评估和优化。此外,书中还涵盖了数据可视化,这是理解和解释分析结果的关键步骤,包括使用R中的ggplot2等包创建有效的图表。
书中的预测分析部分可能涉及到回归分析、决策树、随机森林、支持向量机、神经网络以及集成学习方法如梯度提升(Gradient Boosting)和堆叠泛化(Stacking)。这些方法在预测建模中有着广泛的应用,可用于分类、回归和异常检测等任务。
在数据可视化方面,读者将学习如何使用R中的各种库,如ggplot2、 lattice 和 plotly,创建交互式图表,以更好地理解数据分布、关系和模式。此外,书中可能会讨论如何使用R进行时间序列分析,这对于金融、气象学和市场营销等领域尤为重要。
“Learning Predictive Analytics with R”是一本全面的指南,它不仅教授R语言的统计基础,还强调实践应用,使读者能够利用R进行高效且深入的数据分析,从而发现有价值的洞察。通过这本书,读者可以提升自己的预测分析能力,为实际工作中的决策提供有力支持。

Preface
[ vii ]
Preface
The amount of data in the world is increasing exponentially as time passes. It is
estimated that the total amount of data produced in 2020 will be 20 zettabytes
(Kotov, 2014), that is, 20 billion terabytes. Organizations spend a lot of effort and
money on collecting and storing data, and still, most of it is not analyzed at all, or
not analyzed properly. One reason to analyze data is to predict the future, that is, to
produce actionable knowledge. The main purpose of this book is to show you how
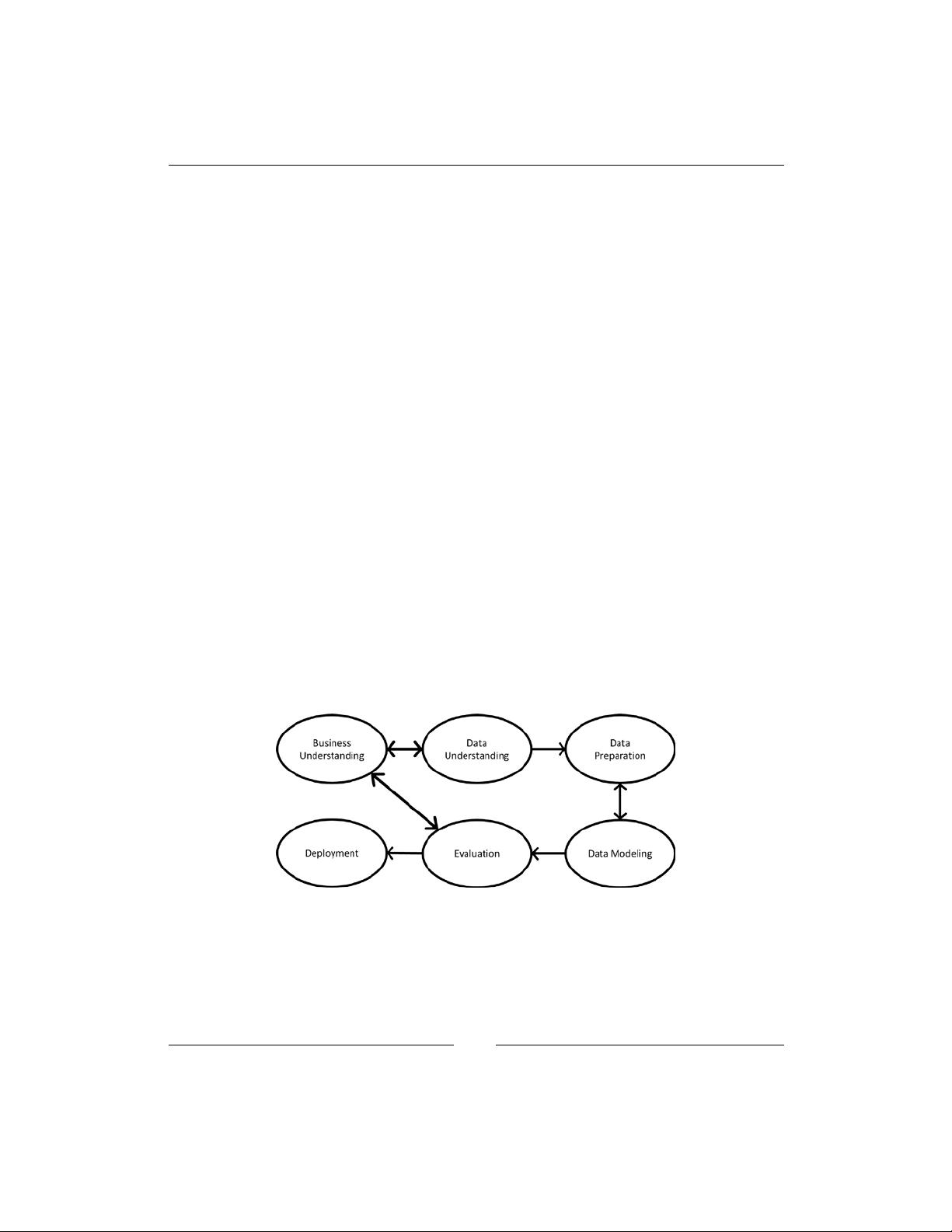
to do that with reasonably simple algorithms. The book is composed of chapters
describing the algorithms and their use and of an appendices with exercises and
solutions to the exercises and references.
Prediction
What is meant by prediction? The answer, of course, depends on the eld and the
algorithms used, but this explanation is true most of the time—given the attested
reliable relationships between indicators (predictors) and an outcome, the presence
(or level) of the indicators for similar cases is a reliable clue to the presence (or level)
of the outcome in the future. Here are some examples of relationships, starting with
the most obvious:
• Taller people weigh more
• Richer individuals spend more
• More intelligent individuals earn more
• Customers in segment X buy more of product Y
• Customers who bought product P will also buy product Q
• Products P and Q are bought together
• Some credit card transactions predict fraud (Chan et al., 1999)
• Google search queries predict inuenza infections (Ginsberg et al., 2009)
• Tweet content predicts election poll outcomes (O'Connor and
Balasubramanyan, 2010)
www.it-ebooks.info


剩余332页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
104 浏览量
2017-12-13 上传
2018-04-23 上传
2018-01-05 上传
2018-01-06 上传
2018-02-24 上传









