HBase核心技术与实战解析
版权申诉
87 浏览量
更新于2024-06-20
收藏 4.13MB PPT 举报
"该文件是一个关于HBase的介绍和实践分享的PPT,主要涵盖了HBase的基本概念、架构特点以及其在大数据处理中的应用。"
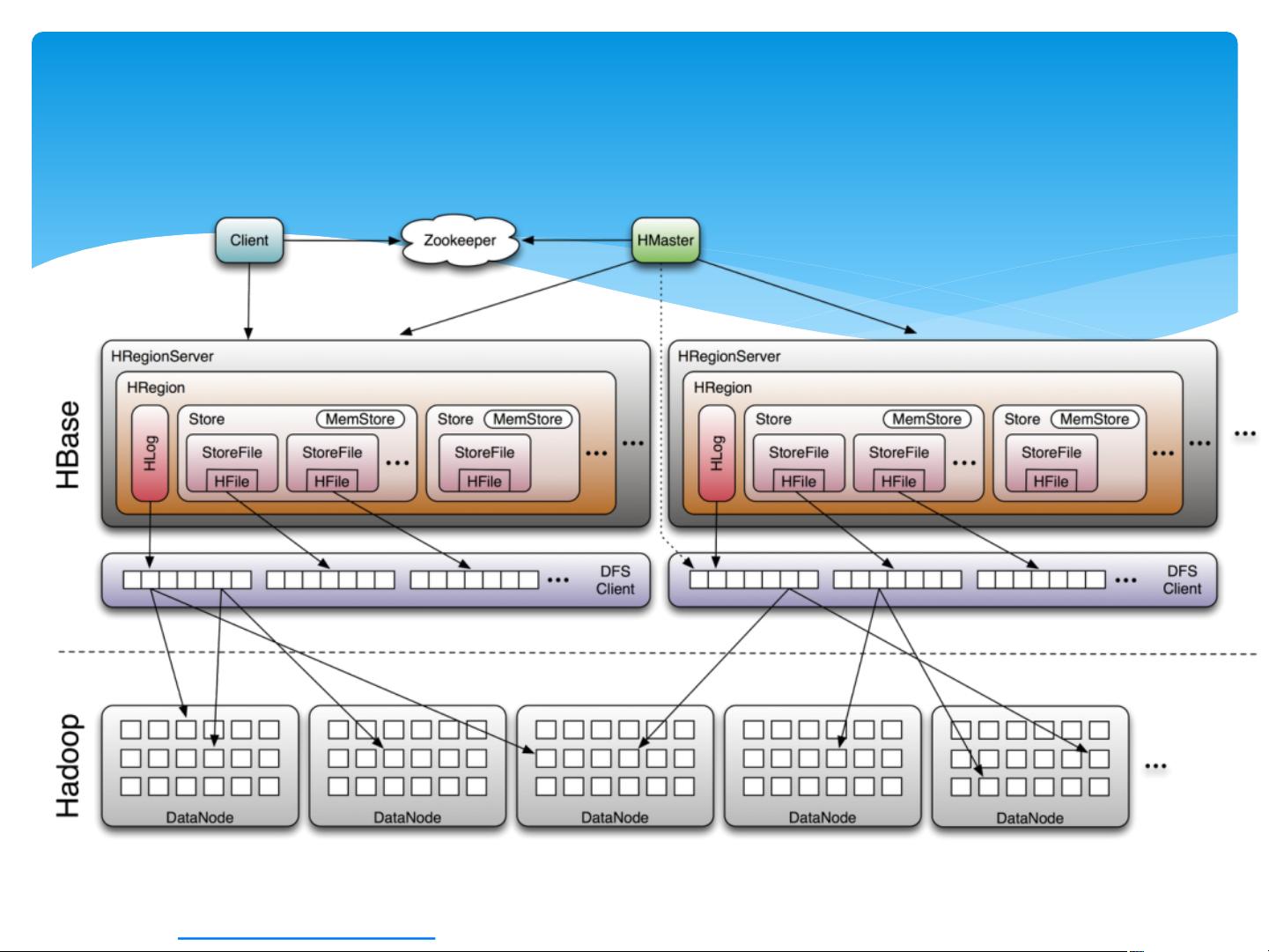
HBase是一种分布式、版本化的NoSQL数据库,其设计灵感来源于Google的Bigtable。HBase的主要贡献者包括Yahoo!、Facebook和Cloudera等公司。它被广泛用于处理大规模数据,尤其适合实时读取大量数据的场景。
在HBase中,数据以表格的形式存储,每个表由多个列族(ColumnFamily)组成。列族是逻辑上的数据分组,例如在示例中,"name"和"contact"可以视为两个列族。列族内的数据是稀疏的,由列标签(ColumnQualifier)来标识,如"firstname"、"lastname"等。每个单元格的值是以字节数组的形式存储,并带有版本号,以便于追踪数据的变化。
HBase的表是通过Region进行管理的,每个Region包含了一段连续的行键(RowKey)范围,例如(startKey, endKey)。Region会根据其大小自动分裂,当一个列族的数据量超过预设阈值时,Region会被分成两个新的Region。为了快速定位数据,HBase使用了特殊的表-`.META.`和`-ROOT-`,它们保存了所有Region的位置信息。
RegionServer是HBase的核心组件,负责Region的读写操作。而Master节点则负责Region的分配和管理,确保数据的均衡分布。HBase依赖ZooKeeper实现高可用性,确保在Master故障时能够快速切换。
HBase的架构特点是强一致性,同一行数据的所有修改只在一个RegionServer上进行,确保了数据的一致性。此外,HBase支持水平扩展,通过添加更多的DataNode(存储节点)或RegionServer(计算节点),可以轻松地提升系统的存储容量和处理能力。
HBase支持行级别的事务,即在同一行内对不同列的操作是原子性的。它的数据模型是列导向的,数据按照行键(升序)、列标签和时间戳(版本)进行排序,形成了一个三维有序的数据结构。这种设计使得HBase在处理大数据时能提供高效的查询性能。
HBase是一个为大数据设计的高性能、可扩展的NoSQL数据库,适用于需要实时查询和大规模数据处理的场景。通过理解其基本概念和架构,我们可以更好地利用HBase来解决实际的大数据挑战。
剩余29页未读,继续阅读
2018-06-19 上传
2022-06-22 上传
2022-07-05 上传
2021-09-29 上传
2019-08-04 上传
2019-08-04 上传
2013-12-12 上传

小小哭包
- 粉丝: 2050
- 资源: 4206
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
