滴滴Fusion实践:从NoSQL到NewSQL的演进
46 浏览量
更新于2024-08-27
收藏 1.65MB PDF 举报
"滴滴NewSQL演进之Fusion实践"
在滴滴的数据库演进过程中,Fusion作为其自研的成熟NoSQL系统,扮演了至关重要的角色。Fusion系统基于RocksDB引擎,通过添加网络层、集群管理层和接入层,构建了一个强大的分布式存储解决方案,能够处理海量的数据和提供高吞吐能力。它不仅满足了内部400多个业务的需求,还在全公司范围内广泛使用,拥有300多个集群,总数据量高达1500TB,峰值QPS(每秒查询率)超过1400万次,实现了全自动化运维,无需专门的运营人员参与。
Fusion最初的诞生,旨在解决历史订单和司机行程轨迹的存储问题。随着滴滴业务的发展,这两个数据量庞大的业务对存储系统的性能提出了更高要求。传统的Redis和MySQL在处理这种规模的数据时显得力不从心,于是Fusion应运而生。Fusion支持Redis协议,利用RocksDB的持久化存储能力,有效应对了大规模数据的挑战。
在此基础上,滴滴进一步发展了NewSQL系统,即dise。dise在Fusion的基础上增强了功能,引入了schema管理、二级索引、事务处理和binlog等功能,使得系统具备了传统关系型数据库的事务能力及SQL支持,从而更好地适应了需要复杂查询和事务处理的业务场景。
为了提升整体架构的效率和智能化,滴滴构建了一套智能管控系统,该系统依托于salt-stack平台,包含了用户系统和运维系统。用户系统简化了业务接入流程,而运维系统则实现了自动化运维,有效地降低了管理和维护成本。
展望未来,滴滴的数据库演进还涉及到了分布式数据库的规划。这将意味着更高级别的可扩展性和容错性,以应对日益增长的业务需求和数据规模。这样的演进策略展示了滴滴在数据库技术领域的持续创新和追求卓越的精神。
滴滴的Fusion和NewSQL演进之路体现了从NoSQL到NewSQL的自然过渡,以及如何在实际业务中逐步优化和增强存储系统的能力,以适应不断变化的业务场景。这一过程不仅展示了技术上的创新,也体现了对业务需求深入理解和灵活应对的智慧。
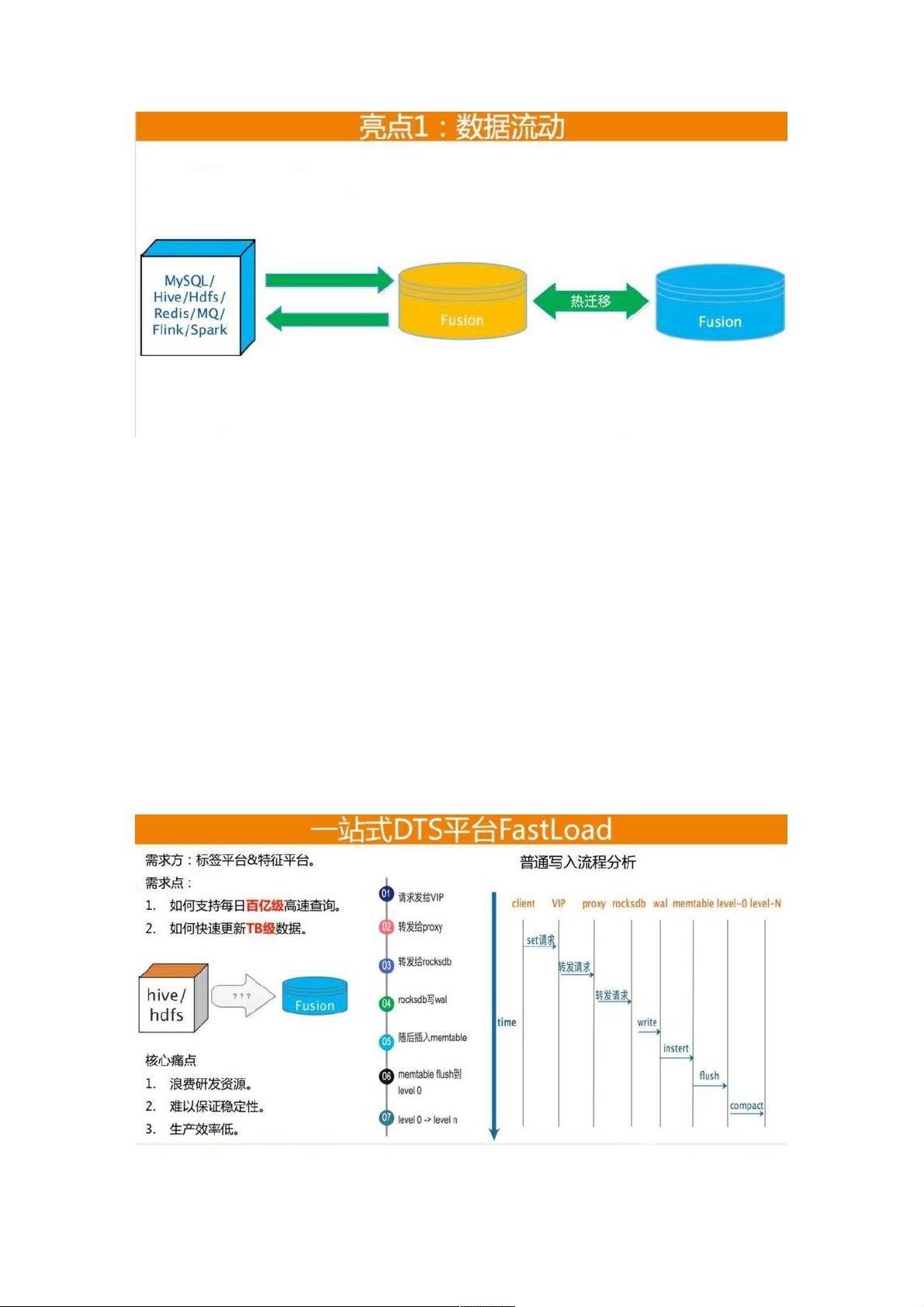
第一个是数据流动能力。做为一个自研的存储系统,他必须融入整个公司的开发生态,具备与其他存储系统、中间件、离线计
算、实时计算等平台打通的能力,才能推广开。因此,我们在这方面做了很多工作,其中挑hive到Fusion打通,以及Fusion与
Fusion之间打通的例子来展开介绍。
为了解决离线hive到Fusion的数据流动,我们做了一站式DTS平台FastLoad,其架构设计如下:
首先,他诞生初期是为了解决标签平台和特征平台的业务问题。这两个业务的数据是通过离线计算产生,因此数据是存放在
hive上,很显然hive的优势并不是OLTP。
因此他们希望有个存储系统能够满足两个需求:
1. 支撑每天数百亿次的高速查询;
2. 支持他们快速的从离线更新TB级别的数据到在线。
很显然Fusion很容易满足第一个需求。那么第二个需求如何解决呢?业务很容易想到的办法是:遍历读取hive的数据,然后构
造成一条条Redis协议支持的KV数据,然后调用Redis客户端写到我们的VIP->proxy->Fusion。整个过程链路比较长,总结下
有3个核心痛点:
浪费研发资源。凡是有从hive到Fusion数据打通的业务,都得维护一套相同逻辑的代码。
难以保证稳定性。离线平台意味着高吞吐、高并发,用它往在线数据库灌数据,显然得注意流控和错峰,因此稳定性难以保
证。
生产效率低。业务使用Redis协议的方式灌库,很多batch和压缩能力都没法用上。
基于上述的业务需求和核心痛点,我们做了FastLoad一站式DTS平台。它主要给RD、产品经理等用户提供服务,因此提供了
两种接入方式:web console和open API。用户通过这两种方式,把FastLoad任务上传到我们服务器,然后服务器会注册一个
调度任务,该调度任务通过用户传入参数,判定数据源,然后从数据源捞取目标数据,再把目标数据分片通过may/reduce做
排序,构建SST文件,然后通过TCP协议的方式下载到Fusion存储节点,绕过proxy,利用RocksDB的ingest功能,加载到
Fusion当中,再通知用户,用户就可以通过Redis协议读到导入的数据了。
剩余10页未读,继续阅读
2019-08-28 上传
2021-10-25 上传
179 浏览量
165 浏览量
133 浏览量
690 浏览量
254 浏览量
151 浏览量

weixin_38523251
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握MATLAB中不同SVM工具箱的多类分类与函数拟合应用
- 易窗颜色抓取软件:简单绿色工具
- VS2010中使用QT连接MySQL数据库测试程序源码解析
- PQEngine:PHP图形用户界面(GUI)库的深入探索
- MeteorFriends: 管理朋友请求与好友列表的JavaScript程序包
- 第三届微步情报大会:深入解析网络安全的最新趋势
- IQ测试软件V1.3.0.0正式版发布:功能优化与错误修复
- 全面技术项目源码合集:企业级HTML5网页与实践指南
- VC++6.0绿色完整版兼容多系统安装指南
- 支付宝即时到账收款与退款接口详解
- 新型不连续导电模式V_2C控制Boost变换器分析
- 深入解析快速排序算法的C++实现
- 利用MyBatis实现Oracle映射文件自动生成
- vim-autosurround插件:智能化管理代码中的括号与引号
- Bitmap转byte[]实例教程与应用
- Qt YUV在CentOS 7下的亲测Demo教程
