Hive在Linux上的安装与部署及词频统计实践
需积分: 16 187 浏览量
更新于2024-07-09
1
收藏 1.04MB DOCX 举报
"该文档是关于大数据技术课程的实验报告,主要聚焦于Hive的安装、部署以及使用Hive进行词频统计。实验者姚能燕在基于Linux系统的Hadoop伪分布式环境中,使用Hadoop 2.7.1及以上版本、JDK 1.6及以上版本和Eclipse作为开发工具,配合Hive 3.1.2和MySQL 8.0.22进行了实验。实验内容包括Hive的配置,以及利用Hive实现词频统计算法,对数据库数据进行操作。"
在大数据处理领域,Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,方便大规模数据集的管理和分析。本实验中,Hive的安装和部署是首要任务,通常包括以下步骤:
1. **系统准备**:确保运行环境为Linux,因为Hadoop和Hive通常在Linux环境下运行更稳定。这里提到的是Linux操作系统,可能需要根据具体版本配置相应的MySQL。
2. **安装JDK**:Hadoop和Hive都需要Java环境支持,所以首先需要安装JDK 1.6或更高版本。
3. **安装Hadoop**:根据实验描述,Hadoop版本至少为2.7.1。安装包括下载Hadoop二进制包,解压,配置环境变量,以及初始化和启动HDFS及YARN等服务。
4. **配置Hadoop**:这涉及到修改`hadoop-env.sh`、`core-site.xml`、`hdfs-site.xml`、`yarn-site.xml`等配置文件,设置Hadoop相关的参数,如HDFS的名称节点和数据节点,以及YARN的相关配置。
5. **安装Hive**:下载Hive的相应版本,解压后配置环境变量,同时需要配置Hive与Hadoop的连接,修改`hive-site.xml`文件,设置Hive的 metastore(元数据存储),通常可以选择使用MySQL作为元数据库。
6. **启动Hive**:启动Hive的服务,包括Hive Server和MetaStore Server,然后通过命令行或Web界面交互。
7. **创建表和导入数据**:在Hive中创建适合词频统计的表结构,然后将文本数据导入HDFS,作为Hive表的数据源。
在完成Hive的安装和配置后,实验进入了词频统计部分。Hive支持SQL语句,可以通过编写查询来统计文本中的词频。一般步骤如下:
1. **数据预处理**:可能需要对原始文本进行清洗,去除标点符号、停用词等,然后将文本分词。
2. **创建词频统计表**:在Hive中创建一个新表,用于存储每个词及其出现次数。
3. **词频统计**:使用Hive的`COUNT()`和`GROUP BY`函数,对每个词进行计数,分组统计每个词出现的次数。
4. **结果展示**:最后,查询结果并展示词频最高的词语。
这个实验不仅锻炼了对Hadoop生态组件的掌握,还展示了如何在实际场景中应用Hive进行大数据处理。通过这样的实践,学生能够更好地理解大数据处理流程,以及Hive在数据分析中的作用。
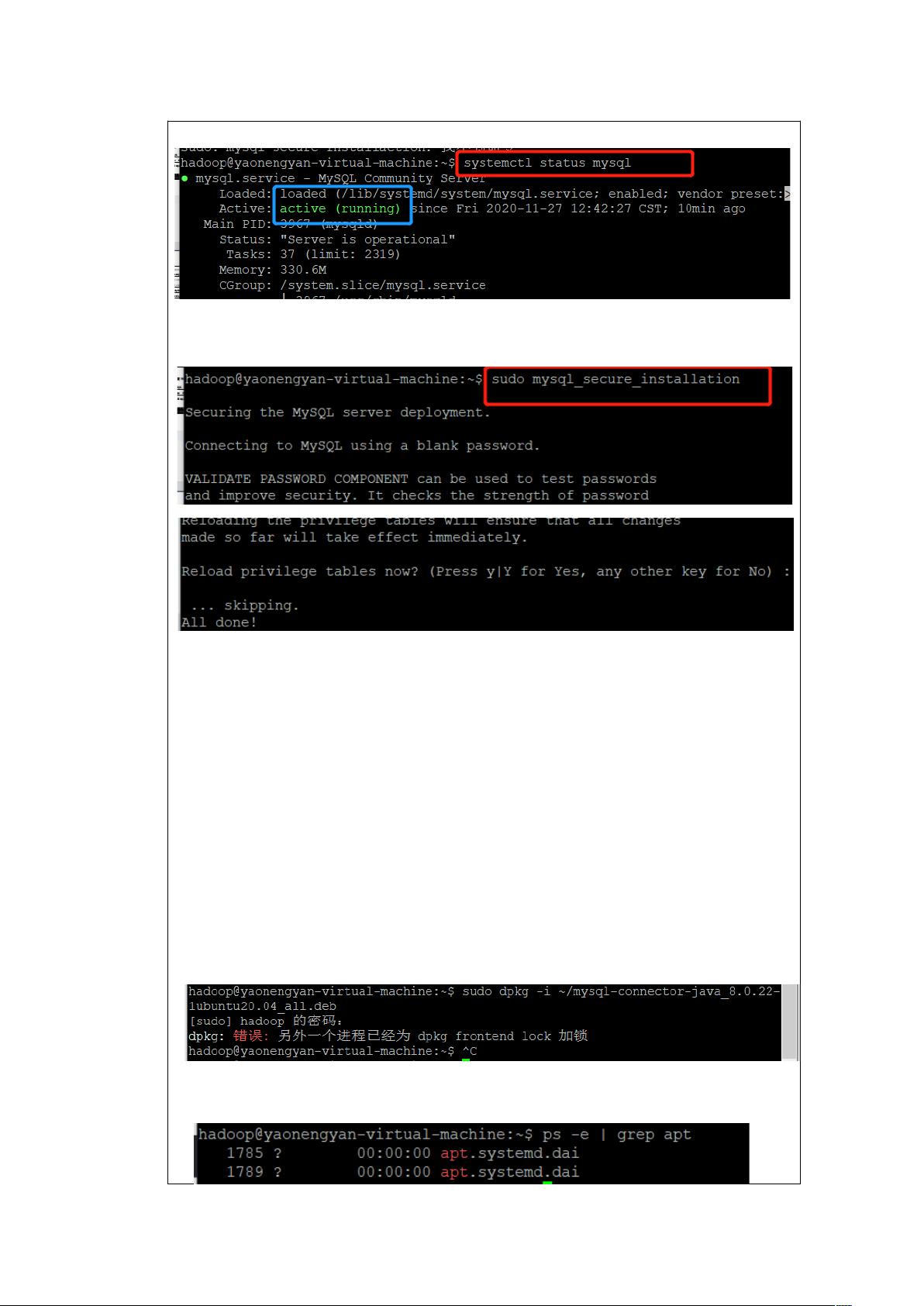
最后 保护加固 MySQL,操作如下图所示,一直回车就可以了:
像上面这样就可以啦,中途的时候可以设一下 mysql 的 root 密码。
2.2 与 Hive 相关的准备工作
采用 MySQL 数据库保存 Hive 的元数据
想要加链接器的时候,提示我加锁了,如下错误:
所以我查看具体是哪个进程加锁:
剩余24页未读,继续阅读
2022-08-14 上传
2020-06-18 上传
2022-04-30 上传
2022-04-30 上传
2020-05-02 上传
2021-10-26 上传
2020-04-15 上传
2023-11-01 上传
2023-12-20 上传

努力的小包
- 粉丝: 4
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
