深度学习 RGB-D 物体识别:相关与个体多模态方法
需积分: 1 21 浏览量
更新于2024-09-05
收藏 1008KB PDF 举报
"这篇论文提出了一种名为相关与独立多模态深度学习(CIMDL)的方法,用于RGB-D对象识别。与大多数传统RGB-D对象识别方法不同,CIMDL通过一对深度神经网络联合学习原始RGB-D数据的特征表示,以便同时并明确地利用共享信息和模态特定信息。具体来说,它构建了两个深度残差网络来处理RGB和深度数据,并在网络的顶层将它们连接起来,通过损失函数学习一个新的特征空间,该空间能够很好地建模RGB-D信息的相关部分和个体部分。整个网络的参数通过反向传播准则进行更新。实验结果在两个广泛使用的RGB-D对象图像基准数据集上表明,我们的方法超越了大多数最先进的方法。"
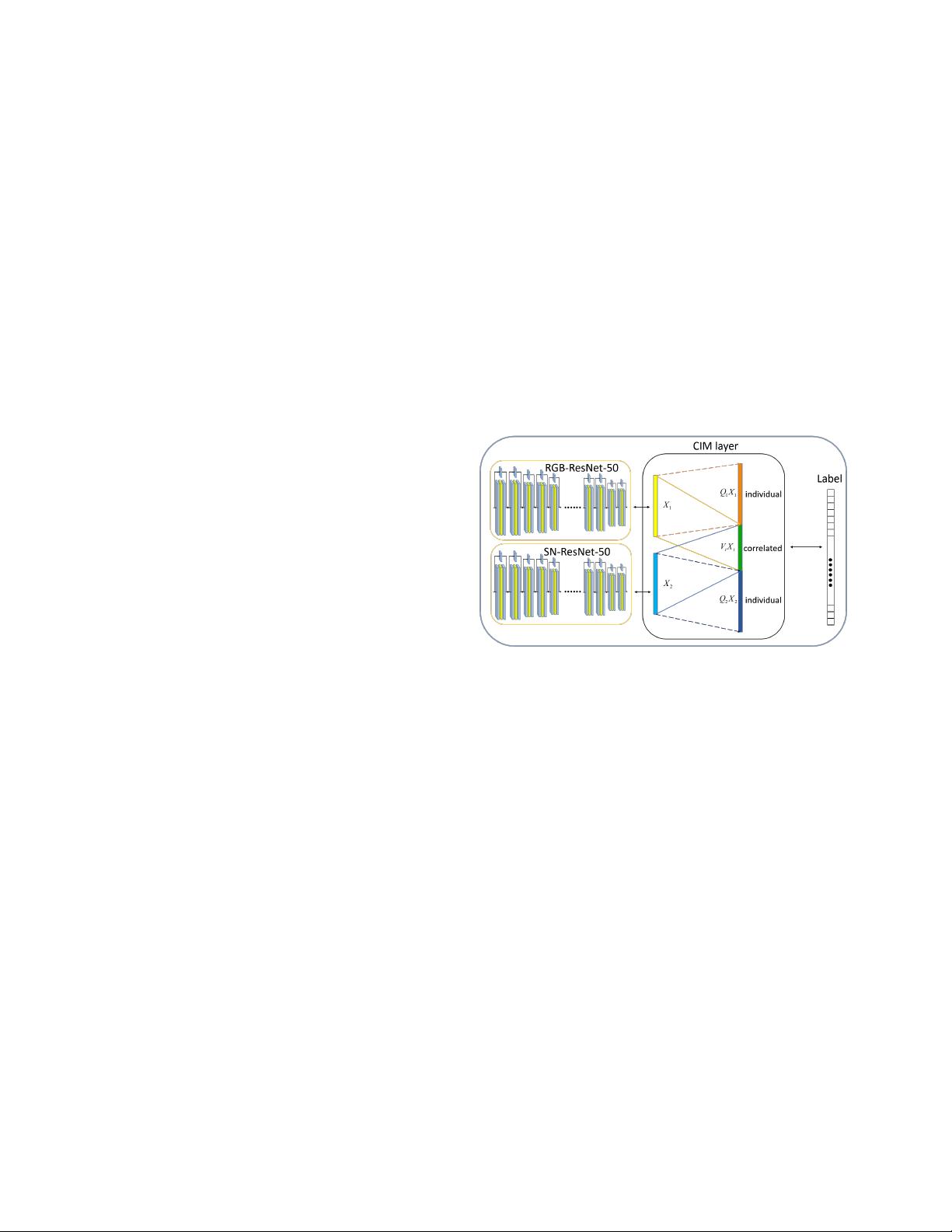
本文主要探讨的是RGB-D对象识别领域的一个创新方法——相关与独立多模态深度学习(CIMDL)。RGB-D数据是指结合了红绿蓝(RGB)彩色信息和深度信息的数据,常用于增强现实、机器人导航和物体识别等应用。传统的RGB-D对象识别方法通常分别从RGB和深度通道提取特征,而CIMDL则采用了一种新的策略。
CIMDL的核心是通过一对深度神经网络(DNNs)联合学习,这允许从原始RGB-D数据中同时挖掘共享信息和模态特有的信息。深度残差网络(Residual Networks)被选用来处理RGB和深度数据,因为它们在处理高维数据时表现出色,能有效地捕获复杂的模式。这两部分网络在顶层进行连接,意味着它们的输出会在一个共同的特征层融合。
为了更好地建模RGB-D信息的两个关键方面,即相关性和个体特性,论文中设计了一个损失函数。这个损失函数的作用是在网络的顶部创建一个新的特征空间,使得RGB和深度信息的关联部分和独特部分都能在这个空间中得到良好的表示。通过反向传播算法,网络的参数得以更新,优化整个模型以提高识别性能。
实验部分,作者们在两个广泛使用的RGB-D对象图像数据集上验证了CIMDL的效果。结果显示,CIMDL在识别准确率上超越了当前的许多先进方法,证明了其有效性和优越性。
CIMDL提供了一种更高效、更全面的方式来利用RGB-D数据的全部潜力,对于提升物体识别的准确性和鲁棒性具有重要意义,尤其在复杂环境或光照条件下的应用中。这一方法的提出,不仅推动了深度学习在多模态数据处理中的发展,也为未来的RGB-D识别任务提供了新的研究方向。
Correlated and Individual Multi-Modal Deep Learning for RGB-D Object
Recognition
Ziyan Wang
Tsinghua University
zy-wang13@mails.tsinghua.edu.cn
Jiwen Lu
Tsinghua University
lujiwen@tsinghua.edu.cn
Ruogu Lin
Tsinghua University
lrg14@mails.tsinghua.edu.cn
Jianjiang Feng
Tsinghua University
jfeng@tsinghua.edu.cn
Jie Zhou
Tsinghua University
jzhou@tsinghua.edu.cn
Abstract
In this paper, we propose a correlated and individual
multi-modal deep learning (CIMDL) method for RGB-D
object recognition. Unlike most conventional RGB-D object
recognition methods which extract features from the RGB
and depth channels individually, our CIMDL jointly learns
feature representations from raw RGB-D data with a pair
of deep neural networks, so that the sharable and modal-
specific information can be simultaneously and explicitly
exploited. Specifically, we construct a pair of deep resid-
ual networks for the RGB and depth data, and concatenate
them at the top layer of the network with a loss function
which learns a new feature space where both the correlated
part and the individual part of the RGB-D information are
well modelled. The parameters of the whole networks are
updated by using the back-propagation criterion. Exper-
imental results on two widely used RGB-D object image
benchmark datasets clearly show that our method outper-
forms most of the state-of-the-art methods.
1. Introduction
Object recognition is one of the most challenging prob-
lems in computer vision, and is catalysed by the swift devel-
opment of deep learning [16, 18, 24] in recent years. Var-
ious works have achieved exciting results on several RGB
object recognition challenges [11, 14]. However, there are
several limitations for object recognition using only RGB
information in many real world applications, as it projects
the 3-dimensional world into a 2-dimensional space which
leads to inevitable data loss. To amend those shortcomings
of RGB images, using depth images as a complimentary is
a plausible way. The RGB image contains information of
color, shape and texture while the depth contains informa-
Figure 1. The pipeline of our proposed approach. We construct
a two-way ResNet for RGB images and surface normal depth im-
ages for feature extraction. We design a multi-modal learning layer
to learn the correlated part V
i
X
i
and the individual parts Q
i
X
i
of
the RGB and depth features, respectively. We project the RGB-D
features X
1
, X
2
into a new feature space. The loss function en-
forces the affinity of the correlated part from different modalities
and discriminative information of the modal-specific part, where
the combination weights are also automatically learned within the
same framework. (Best view in the color file)
tion of shape and edge. Those basic features can serve both
as a strength or weakness in object recognition. For exam-
ple, we are able to tell the difference between an apple and
a table simply by the shape information from depth. How-
ever it is ambiguous when it comes to figure out whether
it is an apple or an orange just by depth. When an or-
ange plastic ball and an orange are placed together, it is
equally difficult for us to tell the difference just by RGB
image. This means that a simple combination of features
from two modalities sometimes jeopardizes the discrim-
inability of feature. Therefore, we are supposed to choose
those shared and specific features more wisely. Thus, we
believe a more elaborated combination of modality-specific
4321
arXiv:1604.01655v3 [cs.CV] 9 Dec 2016
下载后可阅读完整内容,剩余9页未读,立即下载
2949 浏览量
3569 浏览量
1598 浏览量
2009-03-14 上传
602 浏览量

jihong193
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- imgix-emacs: Emacs内图像编辑与imgix URL生成工具
- Python实现多功能聊天室:单聊群聊与智能回复
- 五参数逻辑回归与数据点拟合技巧
- 微策略MSTR安装与使用教程详解
- BootcampX技术训练营
- SMT转DIP分线板设计与面包板原型制作指南
- YYBenchmarkFFT:iOS/OSX FFT基准测试工具发布
- PythonDjango与NextJS构建的个人博客网站指南
- STM32控制433MHz SX1262TR4-GC无线模块完整设计资料
- 易语言实现仿SUI开关滑动效果源码教程
- 易语言寻路算法源码深度解析
- Sanity-typed-queries:打造健壮的零依赖类型化查询解决方案
- CSSSTATS可视化入门套件使用指南
- DL_NG_1.4数据集压缩包解析与使用指南
- 刷卡程序及makefile编写教程
- Unreal Engine 4完整视频教学教程中文版208集
