数据中心的QoS感知计算冲刺管理:ESprint
117 浏览量
更新于2024-08-27
收藏 624KB PDF 举报
"ESprint: QoS-Aware Management for Effective Computational Sprinting in Data Centers"
本文是一篇研究论文,探讨了在“暗硅”时代数据中心如何通过QoS(服务质量)感知管理来实现有效的计算冲刺(Computational Sprinting),以应对低频高密度突发工作负载对硬件资源的需求。在现代数据中心,为了确保应用的服务质量,通常需要额外的硬件资源来应对可能出现的突发性工作负载。计算冲刺是一种提高多核处理器芯片计算性能的技术,它允许芯片在短时间内超出其功率和热限制,通过开启所有处理器核心并利用新型相变材料吸收额外的热量散发。
计算冲刺的关键在于,当系统遇到短期的高需求时,它能够短暂地超越设计规格,从而最大化利用硬件潜力。这种技术可以有效地处理偶尔的工作负载峰值,避免频繁增加额外的硬件设备。文章中提到,通过使用相变材料,芯片可以在短时间内吸收并处理由于超负荷运行产生的额外热量,而不会对长期稳定性造成损害。
ESprint 提出的QoS感知管理策略旨在优化计算冲刺的过程,确保在提升性能的同时,仍能保持服务质量和系统的稳定性。这可能涉及到智能调度算法,以决定何时启动计算冲刺,以及如何分配资源以最大化效益。此外,这样的管理系统还需要考虑到能耗效率,以防止过度使用能源导致的不必要成本。
论文可能会详细分析计算冲刺的性能提升效果、对系统稳定性的影响、以及与传统资源管理策略的比较。它可能还会讨论潜在的挑战,如如何预测和识别适合进行计算冲刺的工作负载,以及如何在不影响其他应用服务的情况下,平滑地进行性能提升。此外,研究可能还会涵盖相变材料在实际应用中的技术细节,包括它们的性能特性、耐用性和成本效益。
"ESprint"提供了一种创新的解决方案,用于在数据中心环境中有效地管理计算资源,以适应不断变化的工作负载需求,同时确保服务质量。这种QoS感知的计算冲刺管理方法有望成为未来数据中心资源管理的一个重要方向,促进更加高效和绿色的数据中心运营。
ESprint: QoS-Aware Management for Effective
Computational Sprinting in Data Centers
Haoran Cai, Qiang Cao , Feng Sheng, Yang Yang, Changsheng Xie, Liang Xiao
Wuhan National Laboratory for Optoelectronics, Key Laboratory of Information Storage System of Ministry of Education,
School of Computer Science and Technology, Huazhong University of Science and Technology
Corresponding Author: caoqiang@hust.edu.cn
Abstract—In the era of ’dark silicon’, modern data centers
have to provision additional hardware resources to guarantee
the Quality of Service (QoS) of applications in case of bursty
workloads that typically occur in low frequency but high inten-
sity. Fortunately, Computational Sprinting has proven to be an
effective approach to boost the computing performance of many-
core processor chips, which allows a chip to exceed its power and
thermal limits temporarily by turning on all processor cores and
absorbing the extra heat dissipation with novel phase-changing
materials. Consequently, it offers a promising way to deal with
these occasional workload bursts by unleashing the full potentials
of hardware, avoiding deploying extra computing resources. In
this work, we propose ESprint, a QoS-aware management system
based on an effective feedback control mechanism for latency-
critical applications in data centers. ESprint can perform compu-
tational sprinting by precisely scheduling core count, frequency
levels, and sprinting duration, serving bursty workloads without
QoS violation under the thermal constraint. Specifically, ESprint
effectively predict load intensity in the next time interval, and
further dynamically allocates appropriate computing resources to
minimize actual power consumption. Our prototype-based evalu-
ation results show that ESprint achieves up to 1.92x improvement
on energy efficiency for typical workloads while ensuring QoS,
over the non-sprinting strategy. We also explore the design space
among energy efficiency, core count/frequency scaling techniques,
workload characteristics, burst intensity, and QoS requirements,
and draw several key insights to guide the effective use of
computational sprinting in data centers.
Keywords: Computational Sprinting, Energy efficiency,
Power management, Data center, Quality of Service
I. I
NTRODUCTION
Modern processors cannot power on all cores at the nomi-
nal operating voltage and frequency due to thermal constraints,
a phenomenon known as ’dark silicon’ [11]. Recent studies
have manifested that computational sprinting, which activates
idle cores and increases voltage and/or frequency for a short
period of time by absorbing the extra heat dissipation with
emerging materials (e.g., phase-changing materials), provides
a promising way to temporarily speed up application perfor-
mance during workload bursts [28], [27], [34], [15].
On the other side, cloud data centers routinely endure
bursty workloads with low frequency but high intensity own
to interactive services (e.g., search, forum, news) [34], [21],
particularly under special events such as breaking news, online
shopping big sales (e.g., the Black Friday after Thanksgiving),
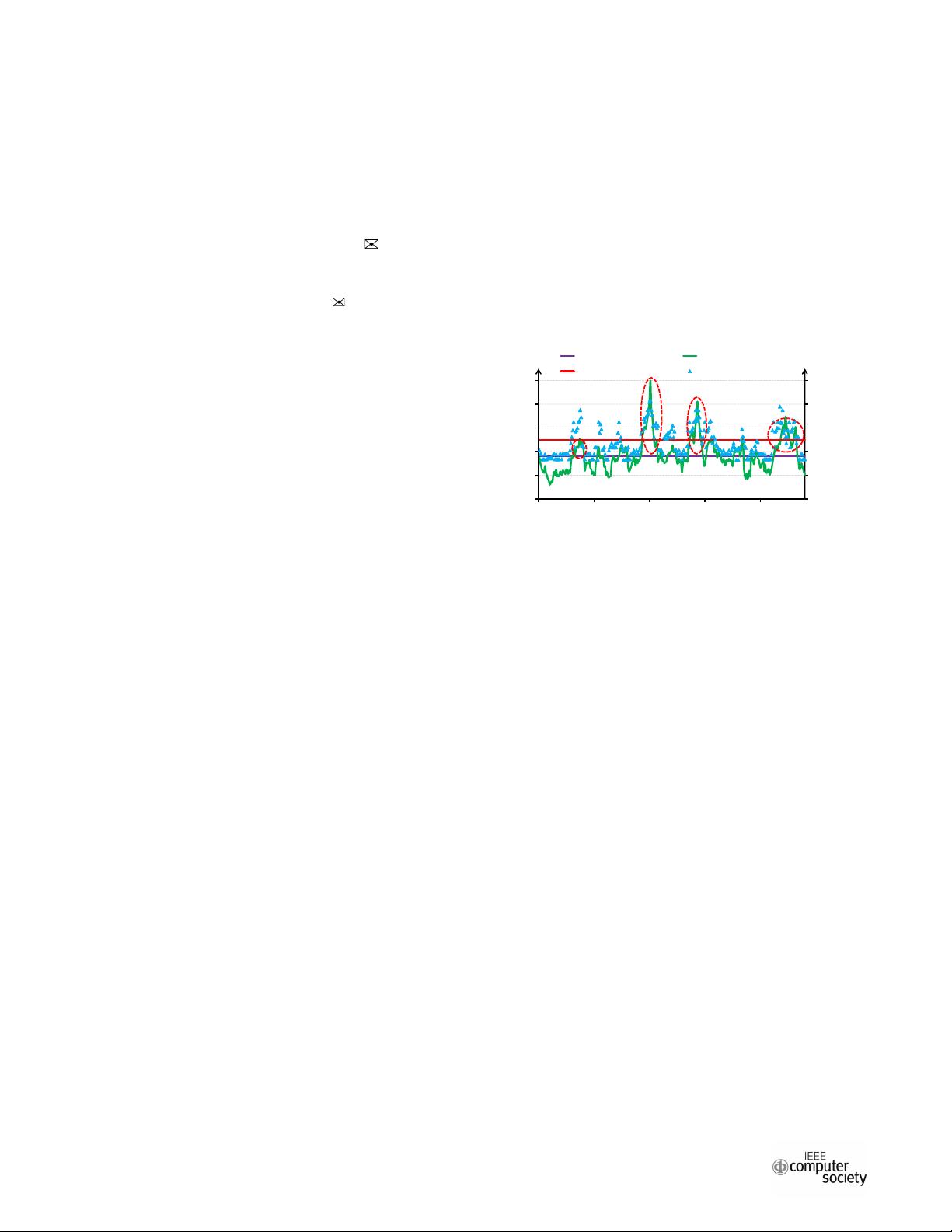
etc. As illustrated by Figure 1, the diurnal workload pattern
(green line) from a study of a Google data center [30] consists
0
200
400
600
800
1000
0
0.2
0.4
0.6
0.8
1
0 5 10 15 20
Processing Capacity
Workload Intensity
QoS Target
Latency
Load
Latency
Time (Hour)
Figure 1: Workload pattern (normalized to the maximal load
intensity) for a Google data center [30] and measured latency
results under limited server processing capacity.
of several load spikes (indicated by the red ovals) during
a whole day with varying burst intensities and durations.
However, the actual processing capacity of modern servers
in data centers, which is denoted by a purple line in Figure
1, is limited under normal cooling environment. Therefore,
the measured latency results can violate the quality of service
(QoS) target (e.g., 500ms constraint for Web-search workload
as the red line shows) under the load spikes as shown in this
figure. Considering that the QoS of latency-critical applica-
tions plays a pivotal role in the financial success of a business
[2], [16], it is imperative to strictly ensure user satisfaction
even by deploying extra servers or high-density rack, such as
Scorpio [4] and Open Compute Project [3], leading to high
investment cost and over-provisioned power budget.
Fortunately, computational sprinting can temporarily un-
leash the full power of processors. Recent studies have
introduced this approach to improve the task throughput
for data analytic workloads or to reduce the runtime for
parallel workloads, avoiding deploying extra hardware and
power budget [15], [27]. However, computational sprinting
precisely serving workload bursts has to overcome two critical
challenges: a) Thermal constraint at chip level and power
limitation at data center level from the supply side. During
a sprinting process, the cooling system needs to effectively
remove the extra heat dissipated from chip-level sprinting.
In a data center, simply conducting sprinting must draw
more power, potentially overloading facilities in the power
infrastructure, such as the power distribution units (PDUs)
and the on-site power substation. b) Workload fluctuation
420
2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID)
978-1-7281-0912-1/19/$31.00 ©2019 IEEE
DOI 10.1109/CCGRID.2019.00056
下载后可阅读完整内容,剩余9页未读,立即下载
2021-02-05 上传
2019-08-08 上传
2021-05-26 上传
2024-12-19 上传
2024-12-19 上传
2024-12-19 上传

weixin_38514523
- 粉丝: 8
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
