Hive自定义UDF实现:仿MySQL add_months 函数
需积分: 50 12 浏览量
更新于2024-08-29
收藏 758KB DOCX 举报
"hive自定义UDF编写函数"
在Hive中,用户定义的函数(User Defined Functions, UDFs)允许开发人员扩展HQL的功能,以满足特定的业务需求。本资源主要介绍了如何在Hive中自定义UDF,特别是通过继承`GenericUDF`或`UDF`类来实现这一过程。以下是详细步骤和关键知识点:
1. **创建UDF类**
自定义UDF通常涉及创建一个新的Java类,该类继承自`GenericUDF`或`UDF`基类。`GenericUDF`提供了一种更通用的方法来处理各种数据类型,而`UDF`则相对简单,适用于单个输入和单个输出的情况。在本例中,我们选择了`GenericUDF`,因为它的灵活性,但这也意味着我们需要处理更多的细节,如`ObjectInspector`和参数类型检查。
- `ObjectInspectorinitialize`方法:这个方法在`evaluate`方法执行前被调用一次,用于验证传入参数的类型和数量。你需要使用`ObjectInspector`来检查这些信息,确保它们与你的UDF期望的输入匹配。
- `evaluate`方法:这是UDF的核心,类似于`UDF`中的`evaluate`,它接收参数并返回计算结果。在`GenericUDF`中,参数是`DeferredObject`类型的数组,这意味着你需要处理延迟对象以获取实际的值。
- `getDisplayString`方法:当UDF执行出错时,这个方法返回的字符串将作为错误提示信息。
2. **实现特定功能**
在这个例子中,目标是实现与MySQL中的`date_add(CURDATE(), INTERVAL 1 MONTH)`相同功能的UDF,即在当前日期上增加一个月。为了完成这个任务,可能需要引入特定的库,如`hadoop-common-2.7.3.jar`和`hive-exec-1.2.1.jar`,以访问日期和时间操作。
3. **构建JAR文件**
为了将UDF打包成可执行的JAR,你需要在项目中创建一个`MANIFEST.MF`文件,指定主类(即包含UDF的类)和依赖的JAR包。`Class-Path`条目用于指明依赖项的位置。然后,使用IDE(如Eclipse)的打包功能,指定JAR的名称和输出位置,并选择已创建的`MANIFEST.MF`文件。
4. **在Hive中注册和使用UDF**
- **临时函数**:生成JAR后,将其上传到Hive服务器的某个位置。在Hive CLI中,使用`add jar`命令添加JAR到Hive的类路径,然后使用`create temporary function`创建一个临时函数。临时函数只在当前会话中可见,一旦会话结束,函数就会失效。
- 命令示例:
```sql
add jar /home/(省略)/bigdata-udf-mysql-addmonths.jar;
create temporary function mysql_add_months as 'com.xx';
```
在这里,`com.xx`应替换为你的UDF类的全限定名。
5. **调用UDF**
注册UDF后,就可以在Hive查询中使用它了,就像使用内置函数一样。例如,如果你的UDF接收一个日期字段和一个整数(表示月份数量),你可以这样使用它:
```sql
SELECT mysql_add_months(date_column, 1) FROM table_name;
```
通过以上步骤,你可以在Hive环境中创建自己的UDF,以处理特定的业务逻辑或数据转换需求。这增强了Hive的功能,使其更贴近实际应用。
1.创建一个类继承 GenericUDF 或者 UDF 类,在类中实现自定义函数的逻辑,此例是继承
GenericUDF 类。GenericUDF 实现比较复杂,需要先继承 GenericUDF。这个 API 需要操作
Object Inspectors,并且要对接收的参数类型和数量进行检查。 GenericUDF 需要实现以下三
个方法:
// 这个 方法只调用一 次,并且在 evaluate()方法之前调用。该方法接受的参数是一个
ObjectInspectors 数组。该方法检查接受正确的参数类型和参数个数。
abstract ObjectInspector inialize(ObjectInspector[] arguments);
//这个方法类似 UDF 的 evaluate()方法。它处理真实的参数,并返回最终结果。
abstract Object evaluate(GenericUDF.DeferredObject[] arguments);
//这个方法用于当实现的 GenericUDF 出错的时候,打印出提示信息。而提示信息就是你实
现该方法最后返回的字符串。
abstract String getDisplayString(String[] children);
2. 此 处 是 重 新 实 现 hive 中 add_months 函 数 , 实 现 和 mysql 中 添 加 月 份 一 样 的 效 果
(date_add(CURDATE(),INTERVAL 1 MONTH)),此处需要引入两个 jar 包:hadoop-common-
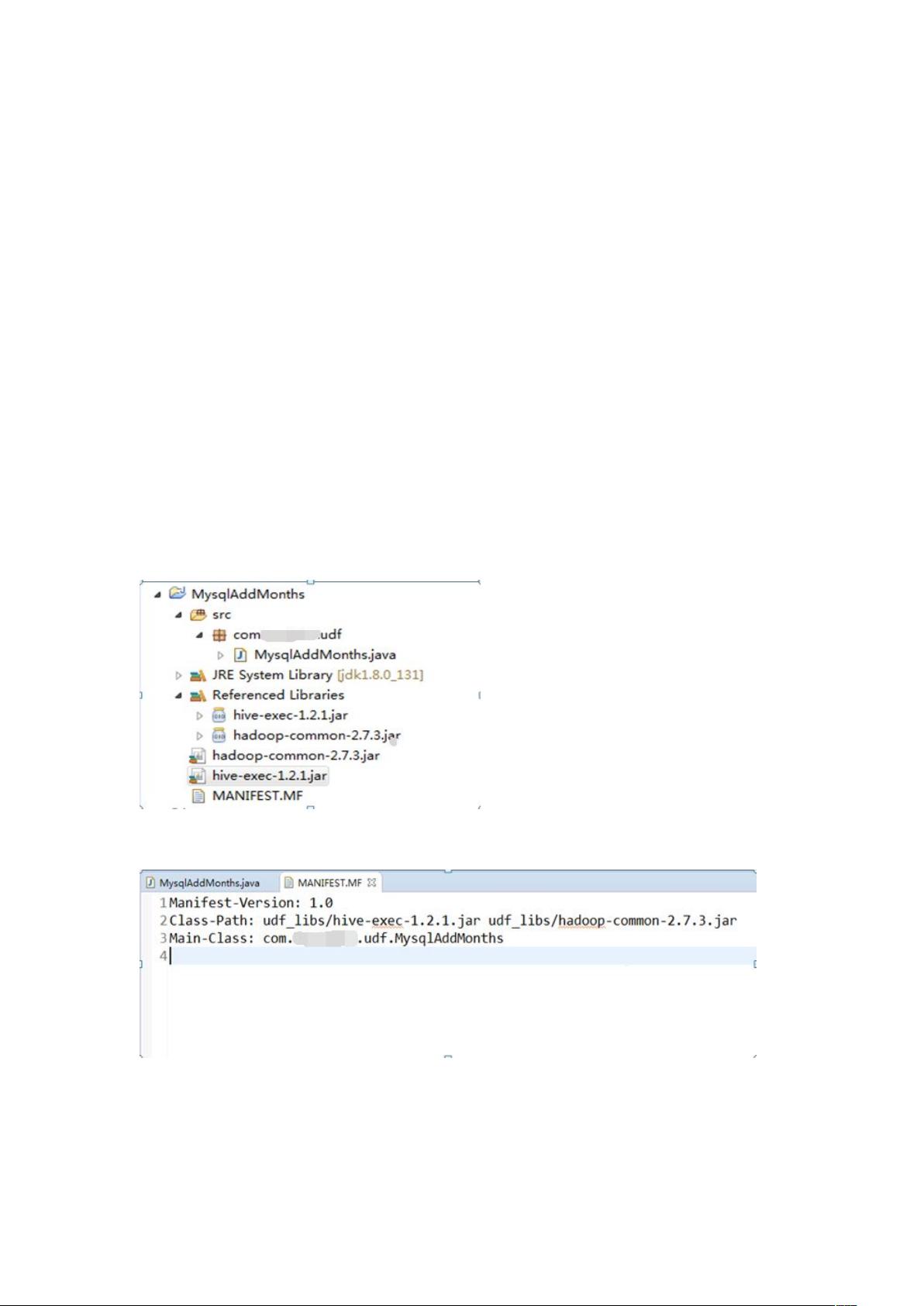
2.7.3.jar,hive-exec-1.2.1.jar,项目结构如下图:
需要在项目中添加一个 MANIFEST.MF 文件,定义主类和关联的 jar 包,内容如下:
说明:Class-Path 需要指定依赖的第三方 jar 包的存储位置
下载后可阅读完整内容,剩余5页未读,立即下载

benjamin3721
- 粉丝: 3
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言谭浩强版本电子书
- Pragmatic Programmers - Release It - Design and Deploy Production Ready Software (2007).pdf
- h264 and mpegx
- 密码锁的verilog代码
- java ajax框架DWR中文文档
- win2000 cluster
- JAVA 多 线 程 机制
- Delphi程序员笔试题
- 1602 LCD 使用完全手册
- 个人网站毕业设计论文
- QQ2440的原理图,非常完整
- Compilers: Principles, Techniques, and Tools 2ed, PDF版
- 常用仪表、控制图形符号及仪表位号命名准则
- 一个简单的Java布局的程序
- 最小生成树算法,用数据结构实现
- 小谈如何搭建自动化测试的框架
