




机器学习降维方法:K近邻与低维嵌入
下载需积分: 10 | PPTX格式 | 4.23MB |
更新于2024-07-16
| 146 浏览量 | 举报
第10章主要探讨了机器学习中的关键概念——降维与度量学习。降维是数据分析中常用的技术,旨在减少数据的维度,使得复杂问题在低维空间中更易于理解和处理。本章内容分为两个主要部分:
1. 特征选择与特征提取:
- 特征选择:这是一种方法,它仅在原始特征集合中挑选最相关的部分,去除冗余或无关的信息。它基于统计或领域知识,通过评估每个特征与目标变量的相关性来决定哪些特征应该保留。
- 特征提取:与特征选择不同,特征提取是通过数学变换创造新的特征,这些新特征能够更好地捕捉数据的内在结构。例如,主成分分析(PCA)就是一种常用的特征提取技术,它通过线性变换将原始数据投影到一组新的坐标系中,新坐标系的轴按照方差的大小排序,从而实现降维。
2. 降维方法举例:
- k近邻学习 (KNN):作为懒惰学习算法,KNN在预测时依赖于训练样本的直接邻域,而非建立复杂的预测模型。它的核心是K值和距离度量的选择,这两个参数会直接影响分类效果。尽管其分类错误率通常不会超过贝叶斯最优分类器的两倍,但在高维数据中,由于“维数灾难”,KNN的效率会降低。
- 低维嵌入:针对高维数据稀疏性的问题,一种常见的解决方案是通过多维尺度(MDS)等方法进行降维,如MDS可以保持原始样本间距离的关系,使得在低维空间中数据的分布更加直观。然而,MDS仅关注训练数据,对新样本的表示有限,因此需要考虑如何扩展到整个空间。
- 线性降维:线性降维方法如主成分分析(PCA)和核化线性降维,通过线性变换寻找低维子空间,但可能受到特定约束,如保持正交性或稀疏性,这会影响最终的降维效果。
3. 度量学习:这部分关注的是如何设计有效的距离度量,以便在低维空间中更好地反映数据的内在结构。常见的度量学习方法包括等度量映射和局部线性嵌入,它们的目标是学习一种度量方式,使得数据点之间的相似性在降维后的空间中得到保留。
本章内容深入浅出地介绍了机器学习中降维技术的重要性以及具体实现方法,特别是如何通过特征选择和提取、低维嵌入和度量学习来处理高维数据的挑战。理解这些概念对于处理大规模、复杂的数据集至关重要。
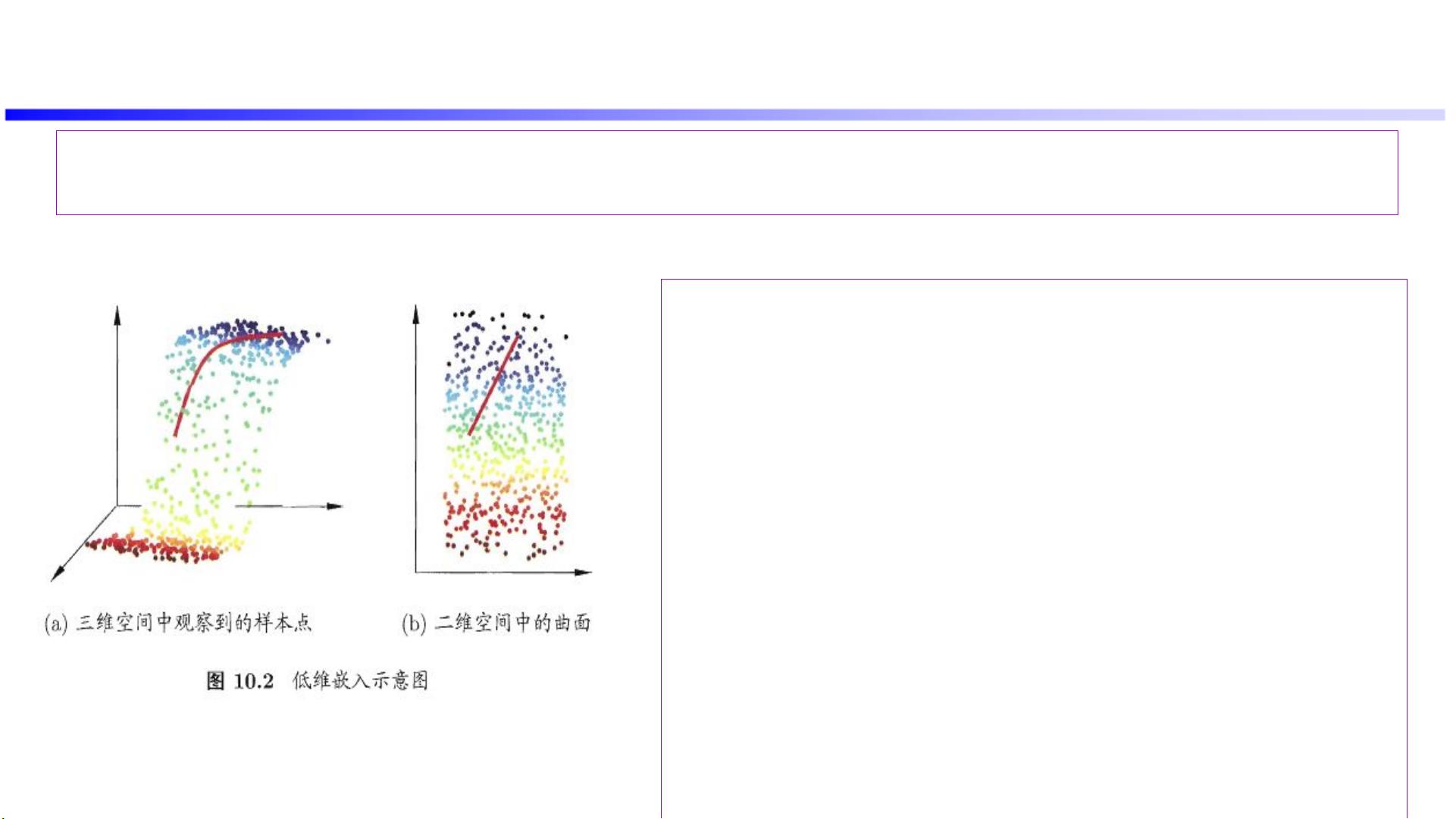
2. 低维嵌入
背景: k 近邻学习的一个重要假设是训练样本的采样密度足够大。事实上高维情形下数据样本稀疏,
很难满足密采样条件(图 10.2 ),而且高维下距离计算困难。 维数灾难
策略:“降维”
数据降维分为特征选择和特征提取两种方
法,
特征提取:在原有特征基础之上经某种变
换
去创造凝练出一些新的特
征出来。
特征选择:只是在原有特征上进行筛选。
过程:某种数学变换将原始高维属性转换到低维“子
空间”,在这个子空间中样本密度大幅提高,
距离计算变得容易。
基础:为什么能进行降维?观测或收集到的数据虽是
高维,但是与学习任务密切相关的可能是某
个
低维分布,即高维空间中的一个低维“嵌入”。

剩余44页未读,继续阅读
相关推荐


cjj131112
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开








最新资源
- MetaTrader 5脚本:iAlligator_HTF绘制鳄鱼指标
- USB micro SMT封装库:全面的原理图与PCB元件资源
- 《古庙全套测绘图纸》- CAD图纸参考下载
- 三星1865型号刷机工具包介绍与使用教程
- 快速搭建Browserify vueify环境,助力Vue 2.0原型设计
- 美国钻石DMM-16-AT操作与技术指南解析
- 市场分析数据对比图表商务PPT模板
- Swift开发的发票计算器应用介绍
- STM32-F0/F1/F2单片机遥控避障巡线小车设计
- Spring5框架学习笔记深度解析
- 手机游戏门户网站模板:单机游戏下载与攻略评测
- JavaSE基础开发:五子棋人机对战小游戏教程
- 易语言实现进程枚举的三种方法详解
- JokerChrome: 探索Chrome生成技术与版本信息
- HTML5打造交互式MP3音乐唱机动画效果
- 商务范工作总结与计划PPT模板设计






















