"C4.5决策树算法实例与拓展"
需积分: 0 100 浏览量
更新于2024-01-26
收藏 911KB PPTX 举报
决策树是一种有监督的分类方法,它通过从数据中生成分类器来解决问题。决策树采用自顶向下的递归方式,通过在内部节点进行属性值的比较,并根据不同的属性值判断从该节点向下的分支,最终在叶节点得到结论。整个决策树可以看作是一组析取表达式的规则,每条从根到叶节点的路径对应着一条合取规则。
决策树的主要应用场景是分类问题,它能够将数据集划分为不同的类别。在决策树的训练过程中,可以使用有标签的数据进行监督学习,也可以使用无标签的数据进行无监督学习,还可以同时使用有标签和无标签的数据进行半监督学习。传统上,半监督学习通常是两阶段的训练,先用较小规模的有标签数据训练一个Teacher模型,再用这个模型对较大规模的无标签数据进行训练。
决策树的生成过程可以分为如下几个步骤。首先,从根节点开始,选择一个属性作为划分标准,将数据集按照该属性的不同取值划分为若干子集。然后,对每个子集递归地重复这一步骤,直到满足终止条件(如子集中的样本都属于同一类别或者属性集为空)。在选择划分标准时,需要根据某种准则评估属性的重要性,常用的准则有信息增益比例和基尼系数。
信息增益比例是一种常用的属性选择准则,它基于信息论中的熵概念。熵可以衡量数据集的纯度,信息增益则表示将数据集划分为不同子集后的纯度改善程度。信息增益比例是信息增益与被划分的子集的熵之比,可以用来解决特征取值数目不同的问题。
决策树模型的性能评估可以使用k折交叉验证方法。在k折交叉验证中,将数据集划分为k个相等大小的子集,依次将每个子集作为验证集,其余的子集作为训练集,重复k次计算模型的准确率或其他性能指标,最后求平均值作为模型的评估结果。
在处理连续值和缺失值时,C4.5算法提供了相应的解决方法。对于连续值属性,可以通过二分法将其转化为离散的属性,然后按照一般的方法进行处理。对于缺失值,C4.5算法使用了替代法和缺失值分支法,在构建决策树的过程中对缺失值进行处理。
C4.5算法是决策树的一种变种,相比于ID3算法,它在属性选择上更加灵活,允许使用连续值属性,并且能够处理缺失值。C4.5算法的核心思想是使用信息增益比例作为属性选择的准则,通过递归构建决策树,最终生成一个可以用于分类的模型。
除了C4.5算法,决策树还有其他一些主流的算法,如CART算法和ID3算法。CART算法是一种二叉决策树算法,它将数据集划分为两个子集,并通过选择最优的属性进行划分。ID3算法是决策树的一种基本算法,它使用信息增益作为属性选择的准则,但不支持连续值属性和缺失值处理。
在实际应用中,决策树可以通过计算机编程来实现,也可以使用图形化工具来可视化生成的决策树模型。在计算机编程实现中,可以使用Python等编程语言来编写决策树的代码,并通过对数据集的训练和预测来使用决策树进行分类。图形化实现决策树可以通过使用可视化工具如Graphviz来将生成的决策树模型转化为可视化的图形展示。
最后,决策树的发展还衍生出了一种拓展方法,即集成学习。集成学习通过将多个决策树进行集成,利用集体智慧提高模型的预测准确率,常见的集成学习方法包括随机森林和梯度提升树等。
总之,决策树是一种有监督的分类方法,通过从数据中生成分类器来解决问题。它具有简单易懂、解释性强的特点,在实际应用中具有广泛的应用价值。通过选择合适的属性选择准则、处理连续值和缺失值以及进行性能评估,可以构建出高效准确的决策树模型,并通过集成学习进一步提高预测准确率。
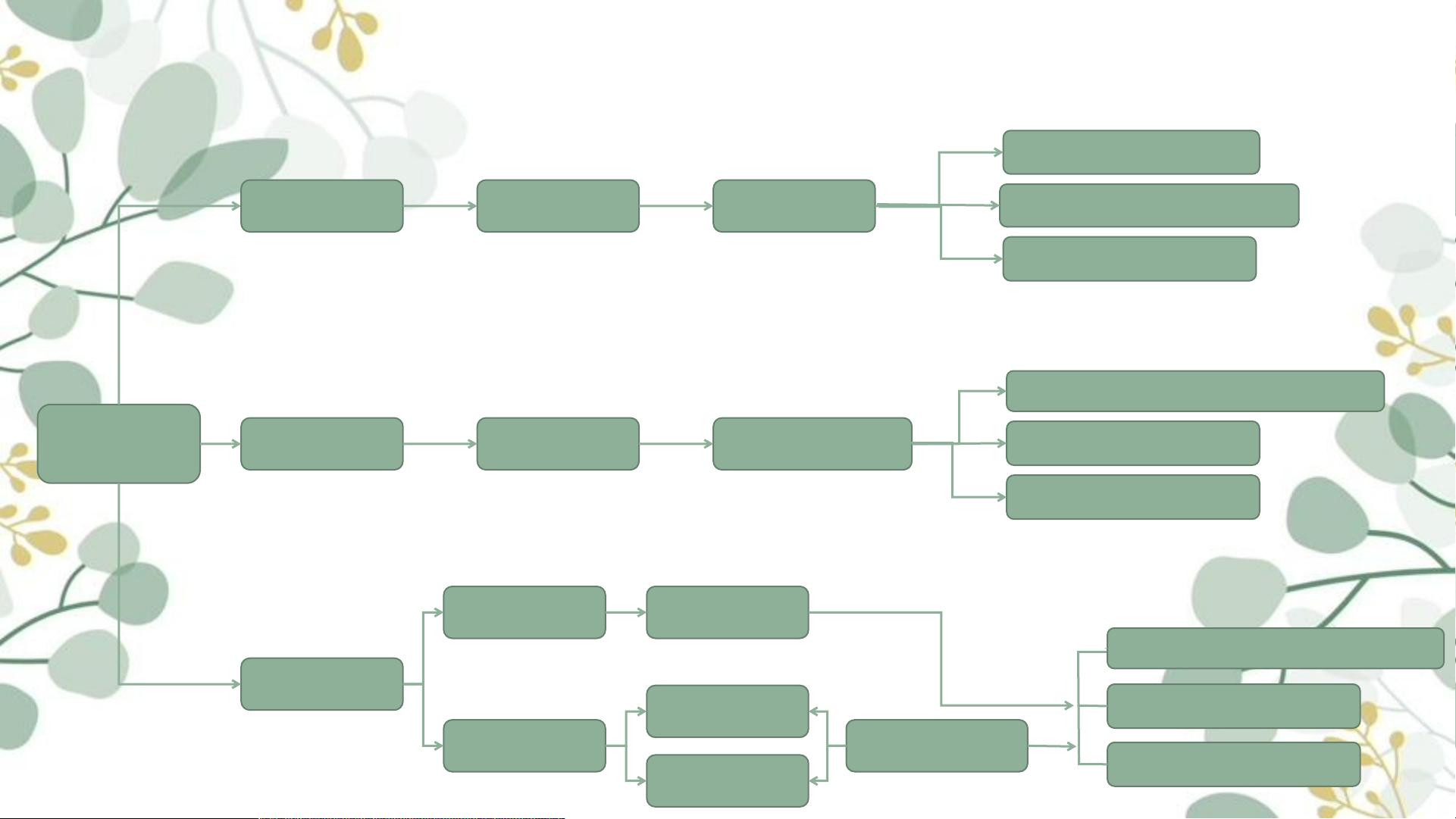
(2)决策树的主流算法有哪些?
决策树
C4.5
CART
支持离散型或连续型数据
能处理缺失值
可以剪枝
支持离散型或连续型数据
能处理缺失值
可以剪枝
分类
分类
回归
信息增益比例
ID3 分类 信息增益
仅支持离散型数据
不能处理缺失值
不能剪枝
Gini系数
回归树
模型树
误差平方和

剩余25页未读,继续阅读
2022-06-14 上传
105 浏览量
2021-09-23 上传
2021-09-23 上传
2021-10-01 上传
2021-09-23 上传
2021-10-04 上传
306 浏览量

Lemon-Stars
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- androidcollectibleguide:Android收藏指南应用程序的源代码-Android application source code
- 2004年全国主要人口数据
- leetcode答案-leetcode-cs:leetcode刷题
- WHGradientHelper:iOS渐变,支持——线性渐变,径向渐变,渐变动画,lable字体渐变,lable字体渐变动画
- 基于STM32手写绘图板的设计.zip
- C-:siki教程
- FabriKGenerator:用Kotlin编写的Fabric mod的mod模板生成器
- leetcode答案-leetcode-machine-swift:Xcode中的leetcode解决方案验证
- YourToDo:使用Django制作的To Do应用程序,用户可以在其中添加,编辑和删除任务
- PHP实例开发源码—PHP版 Favicon在线生成工具.zip
- HttpServer.rar
- SmartCurrencyConverter:Android应用程序的源代码-SmartCurrencyConverter-Android application source code
- MDA车库
- GOTOTALPLAY
- leetcode答案-Study4Job:为了准备秋招而做的准备
- hkp_client:用Dart编写的非常基础的HKP密钥服务器客户端
