编译原理实验:设计与实现词法分析器
版权申诉
166 浏览量
更新于2024-09-03
收藏 295KB PDF 举报
"该资源是一份关于编译原理实验的报告,主要讲解了词法分析器的设计,实验目的是深入理解词法分析原理,并掌握如何对源程序进行词法分析,识别出保留字、标识符、常数、运算符和分隔符等。实验内容包括编写词法分析器,处理C语言子集的源代码,输出单词的内部编码和属性值。实验要求不仅包括基础功能,还鼓励扩展,如处理注释、增加单词类型、错误处理等。实验设计方案提到了数据字典和程序流程,使用C语言进行开发。"
在这个实验中,词法分析器扮演着至关重要的角色,它是编译器的第一个阶段,负责将源代码分解成一个个有意义的单元,即 tokens。这些 tokens 包括保留字(如 `if`, `else`, `int` 等)、标识符(由字母和数字组成的字符串)、常数(无符号整数)、运算符(如 `+`, `-`, `*`, `/`, `=` 等)和分隔符(如 `,`, `;`, `{`, `}` 等)。实验要求词法分析器能正确识别这些 token,并给出它们的内部编码和属性值。
实验的扩展部分鼓励学生提高词法分析器的复杂性,比如处理注释、增加对更多类型的单词识别(例如浮点数、字符串等),并且建立符号表来存储标识符和常数。符号表在编译过程中用于存储变量和函数等的声明信息,以便于后续阶段的语义分析。
实验的设计方案提到了数据字典,这是一个关键的数据结构,它包含了所有可能的 token 类型及其对应的标识ID。例如,保留字 `void` 的标识ID为1,标识符的标识ID为2,无符号整数和小数的标识ID为3,运算符的标识ID为4,而分隔符的标识ID为5。数据字典有助于快速识别输入中的字符序列,并将其映射到正确的 token 类别。
此外,实验还涉及到程序流程的设计,虽然具体流程没有详细列出,但通常会包括读取源文件内容、逐字符分析、识别 token、生成内部编码和属性值,以及错误处理机制。错误处理在词法分析阶段至关重要,因为如果源代码中存在语法错误,词法分析器需要有能力跳过错误部分并继续分析,同时给出错误提示。
在实现这个实验时,选择 C 语言作为开发工具,是因为 C 语言简洁且效率高,适合编写底层的编译器组件。在 Test2 类中定义的函数可能是处理文件读取、token 分析和错误处理等功能的关键组件。
总结来说,这个实验旨在通过实践来深化对编译原理中词法分析的理解,培养学生的编程能力和问题解决能力,同时为构建更复杂的编译器打下坚实的基础。
集美大学实验报告
课程名称 :编译原理 班级 :
指导教师 : 姓名 :
实验项目编号 :实验三 学号 :
实验项目名称 :词法分析器的设计 实验成绩 :
一、实验目的
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分
析方法。
二、实验内容
编写一个词法分析器,从输入的源程序(编写的语言为 C语言的一个子集)
中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、
分隔符五大类。 并依次输出各个单词的内部编码及单词符号自身值。 (遇到错误
时可显示“ Error ”,然后跳过错误部分继续显示)
三、实验要求
1、 词法分析器的功能和输出格式
词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符
号常常表示成以下的二元式 ( 单词种别码,单词符号的属性值 )
。
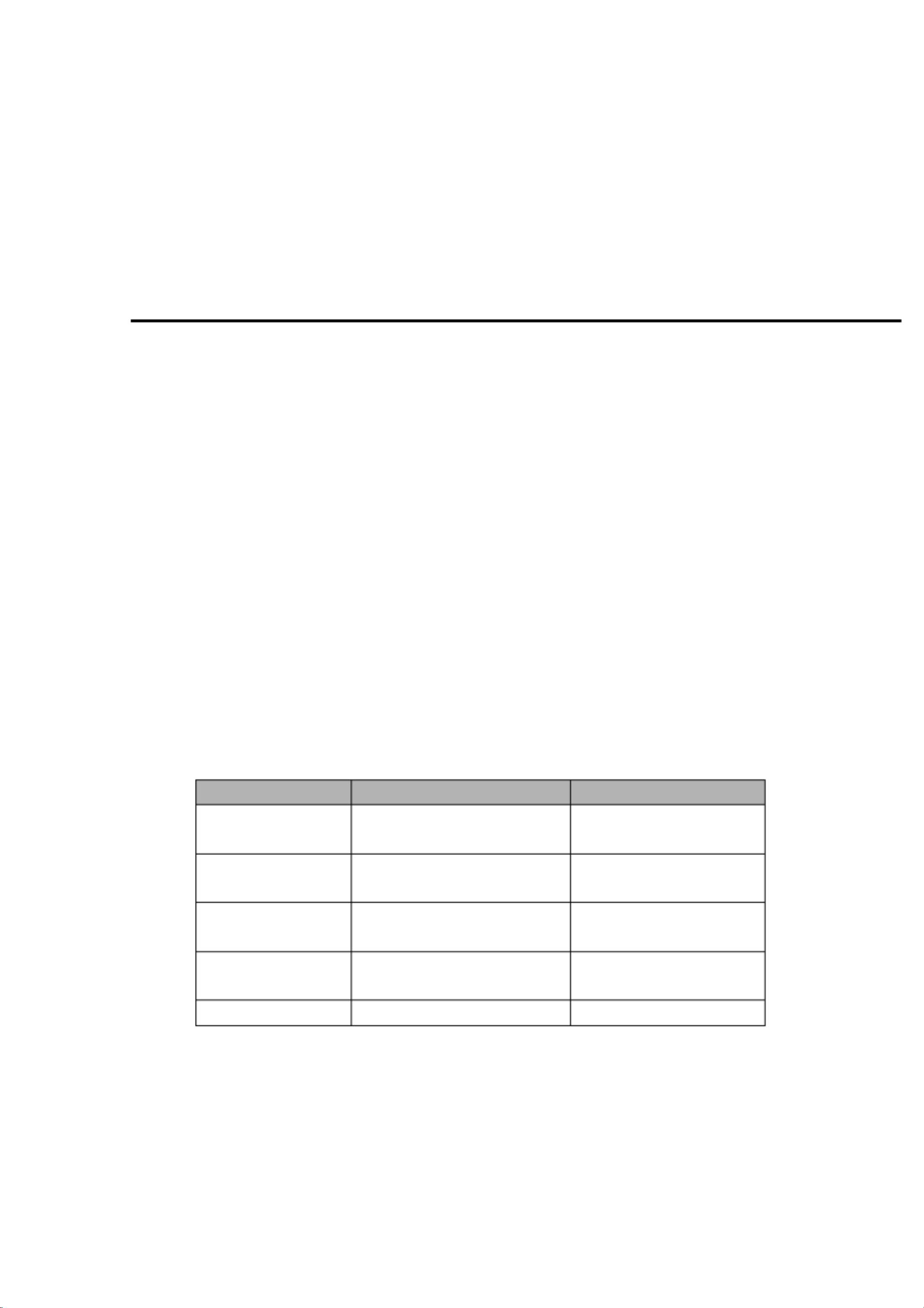
单词 示例 单词种别码要求
保留字 if、 else、 int、while 、do 每个保留字的单词种别都
单独为一种
标识符 以字母开头且包含字母和数
字的字符串
标识符作为一种
常数(只识别无符号
整数)
123、343 无符号整数作为一种
运算符 +、-、*、/、=、= = 、!=、> 、
<、 >=、 <=
每符一种,也可以每一类
符号一种
分隔符 ,、;、{ 、} 、(、 ) 每符一种
2、上述要求仅为基本要求,可以在此基础上扩充,例如删除注释,增加识
别单词的类型,将标识符和常量分别插入到相应的符号表中,增加错误处理等。
3、编程语言不限。
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-04-03 上传
2023-05-06 上传
2021-10-12 上传
2021-11-05 上传
2021-11-22 上传
2024-05-08 上传

xuexishangqian
- 粉丝: 0
- 资源: 5万+
 我的内容管理
展开
我的内容管理
展开







