Kettle循环执行作业:动态替换表名与遍历查询
"kettle设置循环变量 - 实现作业步骤的动态循环执行"
在Kettle(Pentaho Data Integration,简称PDI)中,设置循环变量是实现动态作业流程的关键技术,尤其是在需要对多个表进行相同操作的情况下。以下是对标题和描述中提到的知识点的详细解释:
1. **变量与参数的使用**
Kettle支持使用变量和参数来存储和传递值。在这个场景中,我们可以先从User_Tables表中获取待处理的表名,将每个表名存储为一个变量。Kettle的“设置变量”步骤允许我们将查询结果或其他步骤的输出设置为变量,以便在后续步骤中使用。
2. **循环执行的基础**
当有多个表需要处理时,单个变量无法满足需求,因为Kettle的变量一次只能保存一个值。这时,可以利用Kettle的转换(Transformation)和作业(Job)功能,创建一个转换来获取所有表名,然后在作业中设置循环结构来动态执行这个转换。
3. **获取表的数量**
创建一个转换(如图1所示),用于从User_Tables中读取表名并将其复制到结果字段。然后在作业中运行这个转换(图2中的“获取表的数量”步骤),获取到表的数量,这将用于后续的循环控制。
4. **循环控制**
使用“循环控制器”步骤(图2中的【循环控制器】)来建立一个循环结构,它的条件通常基于一个计数器或变量。在这个例子中,循环控制器的条件可能是计数器小于获取到的表的数量。在每次循环中,将执行针对单个表的操作。
5. **执行表操作**
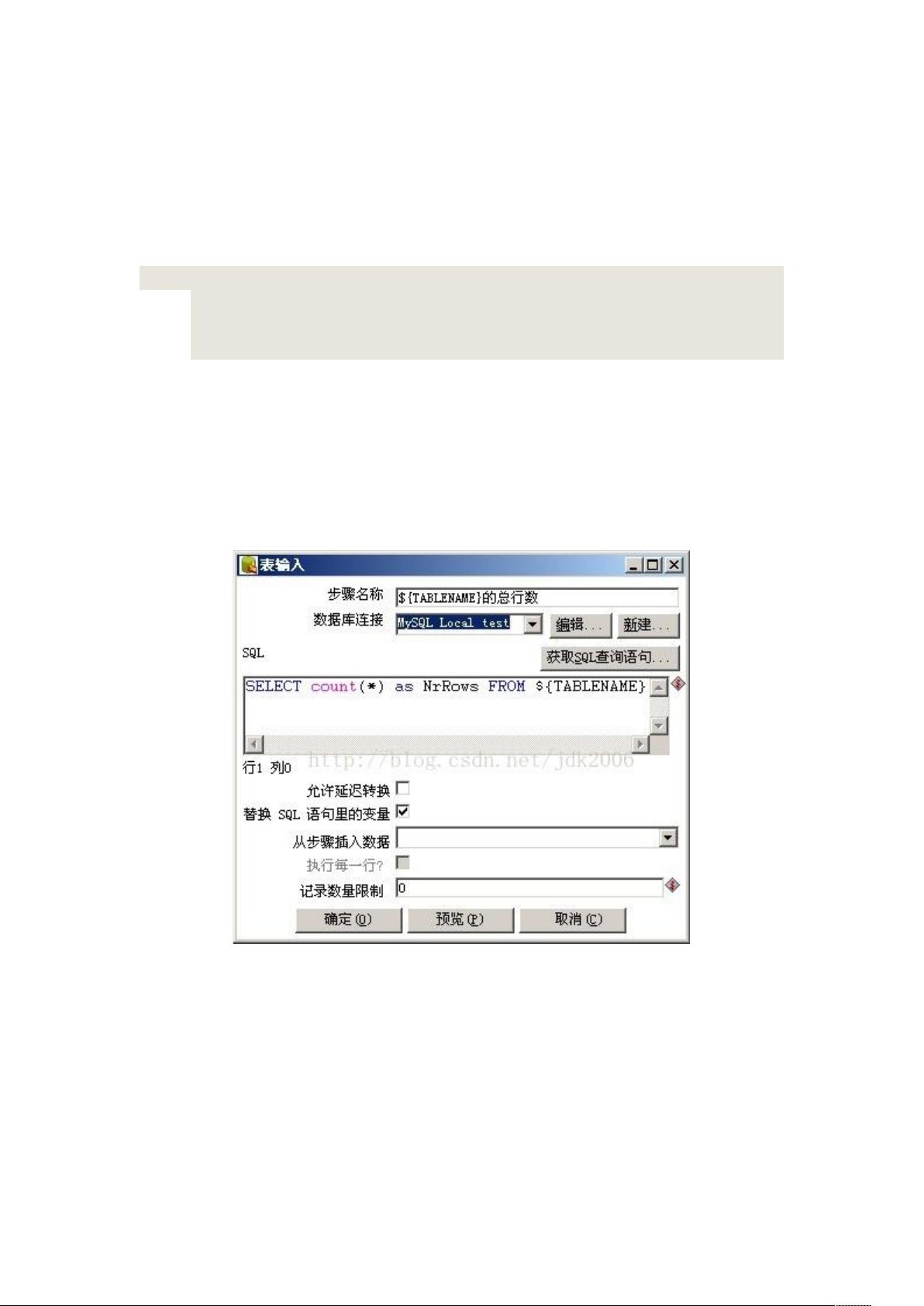
在循环体内,使用“表输入”步骤(图2中的【获取表行数】)动态替换表名,执行针对当前表的SQL查询,例如计算表的行数。这通常通过在SQL查询中使用变量来实现,如 `${TABLENAME}`,然后在循环中动态设置该变量。
6. **计数器和变量更新**
“计数器累加”步骤(图2中的【计数器累加】)不仅用于增加循环计数,还可以在每次迭代中更新变量TABLENAME,使其指向下一个待处理的表。这样,每次循环时,变量的值都会变化,从而实现对不同表的处理。
7. **作业设计**
整个作业的设计应该包括初始化变量、运行获取表数量的转换、设置循环控制器、在循环内部执行表操作并更新计数器,最后可能还包括清理或结束步骤。
通过这种方式,Kettle能够灵活地处理动态数据源,实现对多个表的批量操作,极大地提高了ETL(提取、转换、加载)过程的效率和可维护性。这种技术对于需要对数据库中的多张表进行类似操作的场景非常有用,例如数据清洗、报表生成或者定期备份等。
Kettle
作业步骤循环执行的实现
分类: ETL 工具 2013-10-25 13:342821 人阅读评论(3)收藏举报
场景:User_Tables 存放着系统用户的表信息,其中列 Table_Name 存放着表名。现在想
从 User_Tables 中获取要进行相同数据抽取操作的表,使用 Kettle 实现循环执行这些表。
例如统计表 A、B 的总行数:
[sql] view plaincopyprint?
1. SELECT COUNT(1) FROM A;
2. SELECT COUNT(1) FROM B;
这些 SQL 语句除开表名外,其他部分都是一样的,所以在使用 KETTLE 抽取数据时,
Kettle 循环抽取这些表的数据。
环境:Kettle4.4
思路:
1、上面的 SQL 中除了表名不一致外,其他都是一样的。所以首先解决 Kettle 表输入中表
名替换问题。Kettle 提供了设置变量的步骤,可以将查询出的表名作为变量,在 Kettle 内
进行传递赋值。如下图所示:
2、由于 Kettle 变量一次只能接收一个值,因此若是要执行查询操作的表为两个或者两个以
上,就无法直接使用变量来替换${TABLEnAME}。需要一个能够存储多个表名的步骤或脚
本实现遍历查询出的表名,并将查询出 来的一个表名设置成变量。
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-08 上传
2018-07-18 上传
2013-10-26 上传
2016-03-22 上传
点击了解资源详情
点击了解资源详情
2023-08-24 上传
2018-04-27 上传
2019-08-18 上传

CHEN___FENG
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- OPNET 用户指南_翻译稿
- 数据库的设计-----VFP
- FLEX 3 CookBook 简体中文学习基础资料PDF
- TOMCAT移植到JBOSS
- Myeclipse7[1].0+JBoss5.0测试EJB3.0环境搭建过程详解
- PROTEUS中文教程
- NCURSES Programming HOWTO中文第二版
- 高性能计算之并行编程技术--MPI并行程序设计
- ORACLE备份策略
- 软件评测师07年大题与答案,Word版
- The Productive Programmer.pdf
- c#团队开发之命名规范
- 计算机操作系统(汤子瀛)习题答案.pdf
- ArcGIS Server轻松入门
- 基于组播技术的网络抢答系统设计
- USB数据采集的几个问题
