Python数据分析:分类、预测与聚类算法解析
版权申诉
165 浏览量
更新于2024-08-05
收藏 20KB DOCX 举报
"本文档详细介绍了Python在数据分析与挖掘中的应用,主要涵盖了分类、预测、聚类分析以及关联规则四个核心知识点。"
1. **分类**:
分类是数据分析中的一个重要步骤,它旨在构建一个模型,根据输入样本的属性值来预测其所属的类别。分类属于有监督学习,因为它需要利用带有类标记的训练数据来建立模型。模型构建分为两个阶段:首先,通过学习训练集来归纳分析,得出分类规则;其次,使用测试集评估规则的准确性,如果满足要求,则用于预测未知类别的新样本。常见的分类算法包括决策树、逻辑回归、支持向量机和随机森林等。
2. **预测**:
预测是构建一个函数模型,用于揭示两个或多个变量之间的关系,并据此进行预测或控制。例如,线性回归、时间序列分析和机器学习中的各种预测模型(如神经网络、深度学习模型)都用于预测未知数据点的值。预测模型在金融、气象、市场营销等领域有着广泛应用。
3. **聚类分析**:
聚类分析是对未标记数据进行分组的方法,依据数据之间的相似性或距离。与分类不同,聚类属于无监督学习,因为它不需要预先知道类别的信息。聚类的目标是最大化组内相似性和最小化组间差异。常见的聚类方法有划分方法(如K-Means、K-MEDOIDS)、层次分析方法(如层次聚类)、基于密度的方法(如DBSCAN)、基于网络的方法(如STING)、基于模型的方法(如EM算法)等。
4. **关联规则**:
关联规则分析是一种探索数据中隐藏的、有意义的关系的方法,例如“购买尿布的人很可能也购买啤酒”的购物篮分析。常用算法包括Apriori、FP-Tree和Eclat等。这些算法寻找频繁项集,即在数据集中经常一起出现的项,并从中挖掘出强关联规则。关联规则在市场篮子分析、推荐系统和行为模式识别等领域有广泛的应用。
在实际数据分析项目中,Python提供了许多强大的库,如Pandas用于数据处理,Scikit-learn用于分类和预测,以及Scipy和NetworkX用于聚类和关联规则挖掘。通过熟练掌握这些工具和方法,分析师可以有效地挖掘数据中的价值,为业务决策提供有力支持。
分类与预测
分类
分类是构造一个分类模型,输入样本的属性值,输出对应的类
别, 将每个样本映射到预先定义好的类别。分类模型建立在已有类标
记的数据集上,模型在已有样本上的准确率可以方便的计算, 所以分
类属于有监督的学习。
分类算法分两步: 第一步是学习, 通过归纳分析训练样本集来建立分
类模型得到分类规则;第二步是分类,先用已知的测试样本集评估分类规则
的准确率,如果可以接受, 则用该模型对未知标号的待测样本集进行预测。
预测
预测是指建立两种或两种以上变量间相互依赖的函数模型, 然后
进行预测或控制。
经过数据探索与数据预处理, 得到了可以直接建模的数据。 根据挖掘
目标和数据形式可以建立模型,包括:分类与预测、聚类分析、关联规则、
时序模式和偏差检测等。
分类和预测是预测问题的两种主要类型, 分类主要是预测分类标号
( 离散属性), 而预测主要是建立连续值函数模型, 预测给定自变量对应
的因变量的值。
预测模型也分两步, 第一步是通过训练集建立预测属性的函数模型;
第二步在模型通过检验后进行预测或控制。
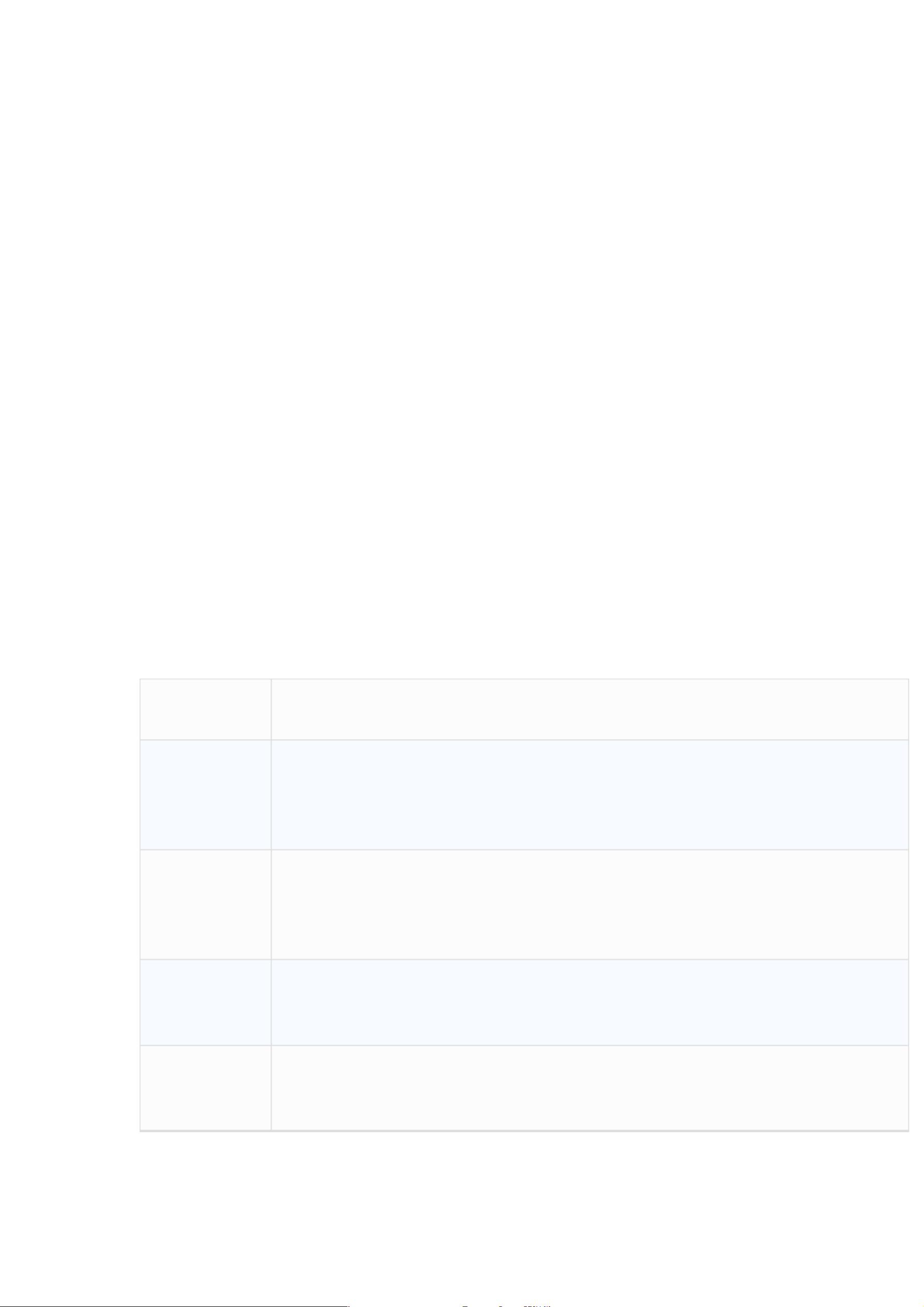
常用分类与预测算法
算法名称
算法描述
回归分析是确定预测属性与其他变量间相互依赖的定量关系最常用
回归分析
的统计学方法。包括线性回归、非线性回归、 Logistic
归、 主成分回归、 偏最小二乘回归等模型
回归、岭回
决策树
决策树采用自顶向下的递归方式, 在内部节点进行属性值的比较,
并根据不同的属性值从该节点向下分支, 最终得到的叶节点是学习划分
的类
人工神经网
络
人工神经网络是一种模仿大脑神经网络结构和功能而建立的信息处
理系统, 表示神经网络的输入与输出变量之间关系的模型
贝叶斯网络
贝叶斯网络又称信度网络,是 Bayes 方法的扩展, 是目前不确定知
识表达和推理领域最有效的理论模型之一
下载后可阅读完整内容,剩余3页未读,立即下载
2019-08-11 上传
2020-05-23 上传
2022-07-01 上传
2023-06-12 上传
2021-11-12 上传
2023-02-22 上传
2024-06-03 上传
2023-03-11 上传
2023-07-30 上传

Cheng-Dashi
- 粉丝: 106
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







