关系数据库设计理论:函数依赖与范式解析
118 浏览量
更新于2024-08-30
收藏 1.32MB PDF 举报
本文主要介绍了关系数据库设计的核心概念,包括关系模式设计、函数依赖、范式和模式设计理论。通过一个学生课程数据库的设计实例,阐述了如何处理数据冗余、异常问题,并详细解释了不同级别的范式,如1NF、2NF、3NF、BCNF、4NF和5NF。
在关系数据库设计中,关键在于创建合适的关系模式,这涉及到确定各个模式的属性以及如何组合这些模式以构建有效的关系模型。设计过程需遵循关系数据库设计理论,该理论主要包括三个方面:函数依赖、范式和模式设计。函数依赖是模式分解和设计的基础,而范式则是衡量模式分解是否恰当的标准。
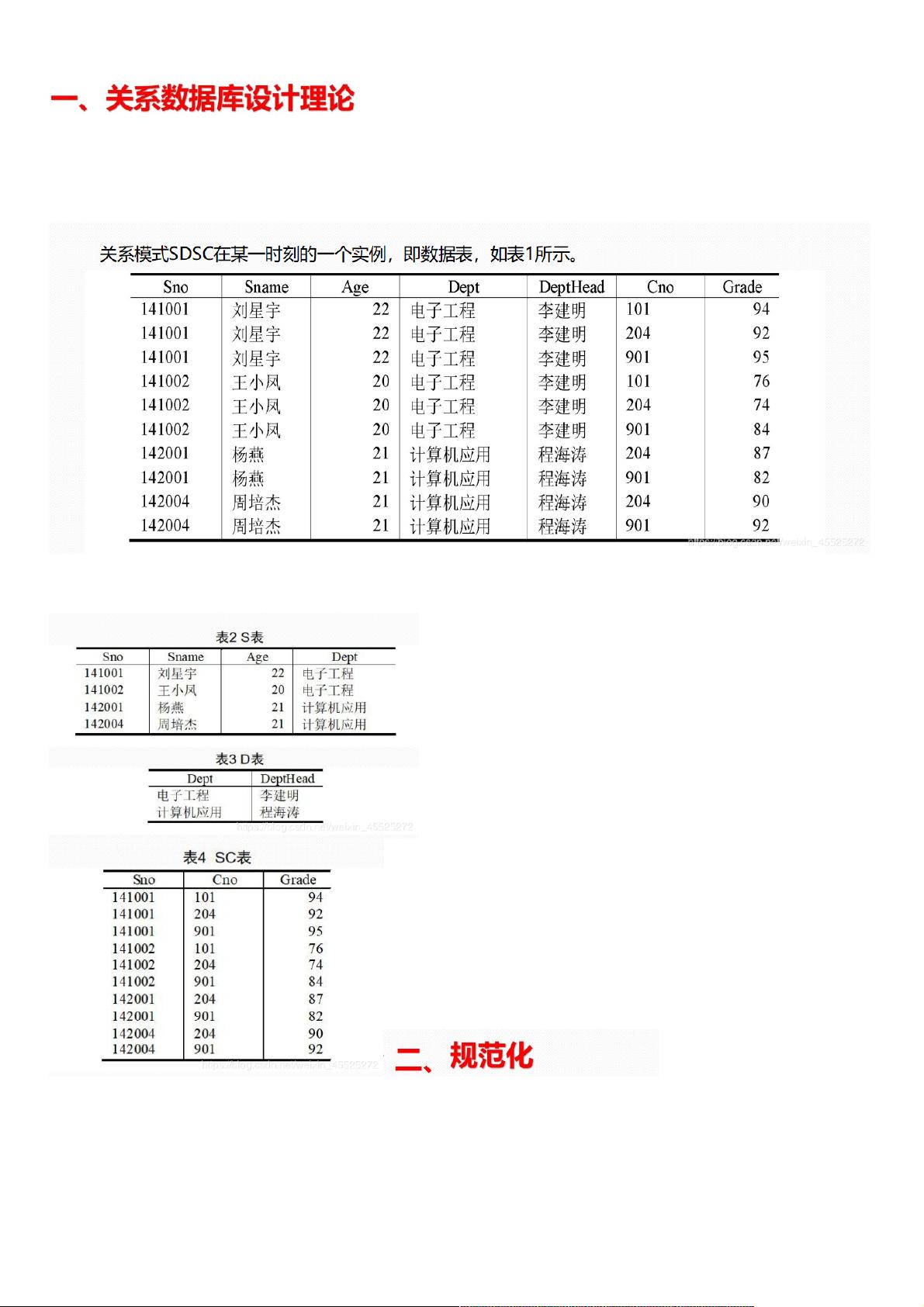
以一个学生课程数据库为例,关系模式SDSC包括学号(Sno)、姓名(Sname)、年龄(Age)、系(Dept)、系主任姓名(DeptHead)、课程号(Cno)和成绩(Grade)。根据实际需求,每个学生属于一个系,一个系只有一个系主任,学生可以选修多门课程,课程也可被多个学生选修。然而,这样的关系模式会导致数据冗余、插入异常、删除异常和修改异常等问题。
为了解决这些问题,需要对关系模式进行规范化,即分解为学生关系S、系关系D和选课关系SC,分别存储学生的个人信息、系的信息和选课信息,这样可以减少数据冗余并避免异常。规范化的目标是达到不同级别的范式,例如1NF、2NF、3NF等,这些范式定义了关系模式的结构和数据完整性规则。
1NF(第一范式)要求每个属性不可再分,确保基本数据单元的原子性。2NF(第二范式)是在1NF基础上,要求非主属性完全依赖于主键。3NF(第三范式)进一步要求所有非主属性都直接依赖于主键,而非其他非主属性。BCNF(巴斯-科德范式)则规定任何非平凡的函数依赖都必须以主键为左部。4NF和5NF涉及多值依赖和投影依赖,分别解决了更复杂的数据依赖问题。
通过这些范式的应用,可以逐步优化关系模式,提高数据一致性,降低数据冗余,从而提高数据库的性能和维护性。在实际数据库设计中,设计师需要根据具体需求和业务逻辑,灵活运用这些理论来构建高效、稳定的关系数据库系统。
数据库编程技术数据库编程技术3——关系数据库设计核心关系数据库设计核心
1、设计一个合适的关系数据库系统的关键是关系数据库模式的设计,即应构造几个关系模式, 每个模式有哪些属性,怎样将这些相互关联的关系模式组建成一个适合的关系模型,
关系数据库 的设计必须在关系数据库设计理论的指导下进行。
2、关系数据库设计理论有三个方面的内容:函数依赖、范式和模式设计。函数依赖起核心作用, 它是模式分解和模式设计的基础,范式是模式分解的标准。
【例1】设计一个学生课程数据库,其关系模式SDSC(Sno, Sname, Age, Dept,DeptHead, Cno,Grade),各属性含义为学号、姓名、年龄、系、系主任姓名;课程号、成绩。根据实
际情况, 这些属性语义规定为:
(1)一个系有若干学生,一个学生只属于一个系。
(2)一个系只有一个系主任。
(3)一个学生可以选修多门课程,一门课程可被多个学生选修。 (4)每个学生学习每门课程有一个成绩
从上述语义规定和分析表中数据可以看出,(Sno, Cno)能唯一标识一个元组,所以,(Sno, Cno)为该关系模式的主码,但在进行数据库操作时,会出现以下问题。
((1)数据冗余()数据冗余(2)插入异常()插入异常(3)删除异常()删除异常(4)修改异常)修改异常
由于存在上述问题,SDSC不是一个好的关系模式。为了克服这些异常,将S关系分解为学生关系S (Sno, Sname, Age, Dept),系关系D(Dept,DeptHead),选课关系SC(Sno,
Cno,Grade),这三个关系模式的实例如表2、表3、表4所示。
规范化的基本思想是尽量减小数据冗余,消除数据依赖中不合适的部分,解决插入异常、删除异常和更新异常等问题,这就要求设计出的关系模式要满足一定条件。在关系数据库的
规范化过程中,为不同程度的规范化要求设立的不同标准或准则称为范式。满足最低要求的称为第一范式,简称1NF,在第一范式基础上满足进一步要求的成为第二范式2NF,以此
类推。
1971年至1972年,E.F.Codd系统地提出了1NF、2NF、3NF的概念,讨论了关系模式的规
范化问题。 1974年,Codd。和Boyce又共同提出了一个新范式,即BCNF。1976年有人提出了4NF,后又有人提出了5NF
各个范式之间的集合关系可以表示为:
5NF4NFBCNF3NF2NF1NF
如下图所示:
下载后可阅读完整内容,剩余3页未读,立即下载
2021-10-04 上传
2008-10-16 上传
2020-12-14 上传
2022-06-12 上传
2011-07-18 上传
2021-12-18 上传
2023-08-06 上传
2022-06-02 上传
2018-08-31 上传

weixin_38663452
- 粉丝: 5
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
