渐进模仿学习:提升轻量级CNN模型性能
需积分: 0 144 浏览量
更新于2024-08-05
收藏 2.32MB PDF 举报
本文探讨了"Progressive Mimic Learning: Train Lightweight CNN Models"这一主题,它提供了一个新的视角来训练轻量级卷积神经网络(Lightweight CNN)模型。作者们,Hongbin Ma、Shuyuan Yang、Dongzhu Feng、Licheng Jia 和 Luping Zhang,分别来自西安西电大学人工智能学院、电子工程学院以及国防科技大学自动目标识别国家实验室,他们共同关注的问题是如何通过知识蒸馏(Knowledge Distillation, KD)有效地提升轻量化模型的性能。
知识蒸馏是一种常用的技术,它建立一个小型的学生模型(Student Model, SM),并将其训练得尽可能接近一个大型的教师模型(Teacher Model, TM)。教师模型积累了大量的知识和经验,通过模仿其内部学习过程,学生模型得以受益。然而,挑战在于如何设计一种有效的策略,让小尺寸的SM能够在性能上超越其大容量的TM,尤其是对于卷积神经网络,这涉及到模型复杂度、计算效率与精度之间的平衡。
论文的核心贡献可能包括以下几个方面:
1. **新方法**:提出了Progressive Mimic Learning,这是一种创新的学习策略,可能逐步地、分阶段地让SM逐渐模仿和学习TM的高级特征和知识,以逐步提高性能,同时保持模型的轻量化特性。
2. **挑战分析**:深入研究了训练轻量级CNN模型时面临的挑战,如过拟合风险、模型复杂度限制等,并可能提出针对性的解决方案。
3. **知识传递策略**:论文可能会探讨不同的知识传递技术,比如注意力机制、多模态蒸馏或者自适应蒸馏,以增强SM的学习效果。
4. **实验与评估**:作者可能会展示一系列实验,通过对比不同方法和模型大小,证明Progressive Mimic Learning在实际应用中的优势,包括在各种任务上的性能提升和资源消耗的降低。
5. **潜在应用**:论文可能讨论了这种轻量化方法在物联网、移动设备等资源受限环境下的实际部署潜力,以及它对能源效率和实时性的影响。
6. **未来方向**:最后,论文可能会提出未来的研究方向,比如如何进一步优化学习过程,或者结合其他技术如迁移学习,以提升轻量级CNN的性能。
"Progressive Mimic Learning"提供了一种创新的思路,通过借鉴人类学习行为的洞察,旨在解决轻量化CNN模型训练中的难题,有望推动该领域的发展。
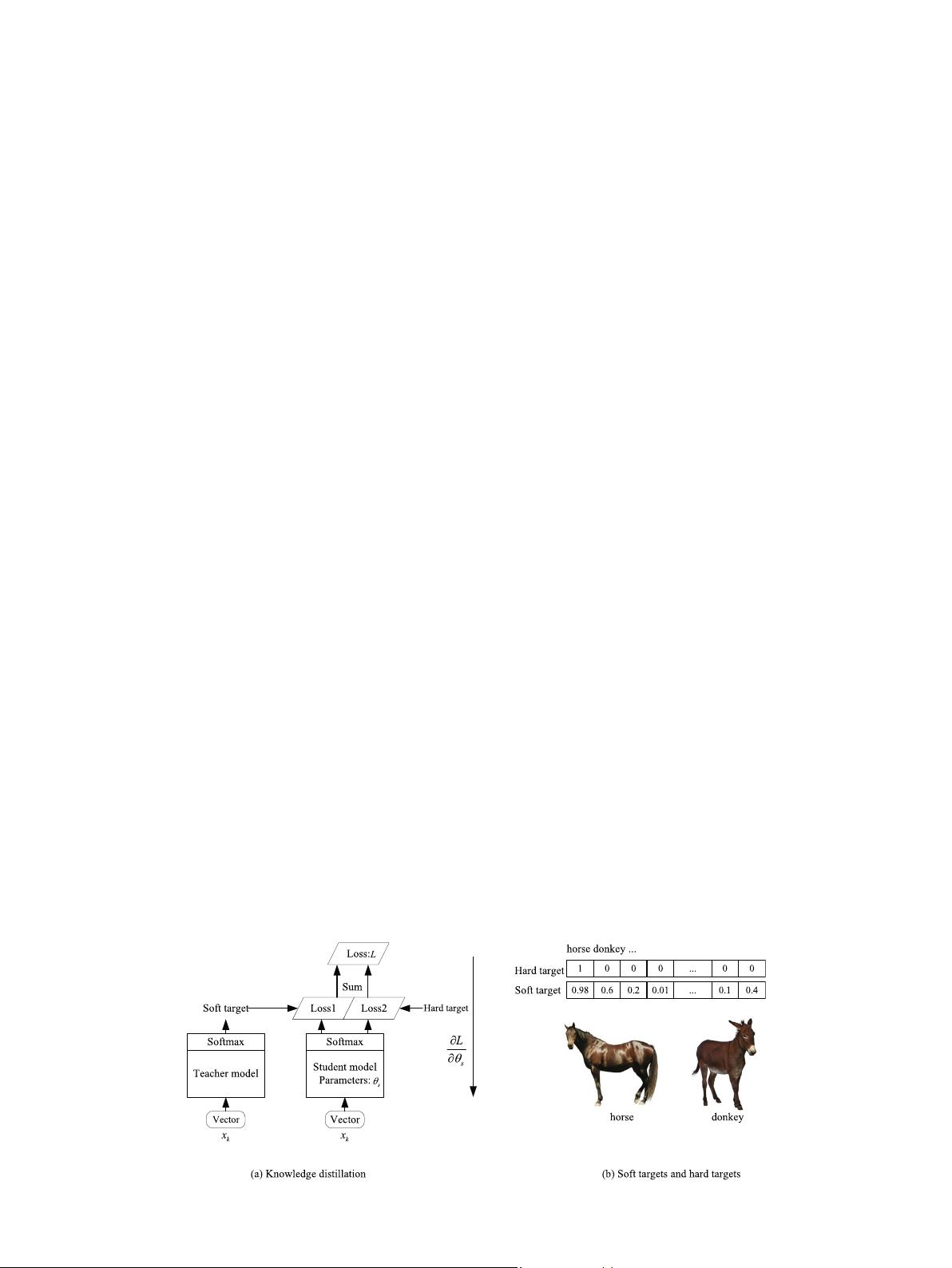
2.2. Knowledge Distillation
Knowledge Distillation (KD) which transfers knowledge from
the TM to the SM is one of the effective methods to train light-
weight CNN models. As shown in Fig. 1(a), the outputs of the
trained TM are utilized as ‘soft targets’ and the true labels of sam-
ples are employed as ‘hard targets’ for the training of the SM. The
soft targets have high entropy, and they provide much more infor-
mation and much less variance in the gradient between training
samples than hard targets, so the SM can be trained on much less
data than the TM, and it can achieve higher performance than the
SM trained on hard targets [24]. For the example shown in Fig. 1
(b), the inter-class similarity is ignored by the hard target, and
the same distance between classes is considered. Compared with
the hard target, the inter-class similarity learned by the TM is
added into the soft target, such as the similarity between horse
and donkey, so the soft target provides much more information
than the hard target.
Exploiting knowledge transfer to train a lightweight model was
proposed first in [39], where a trained TM is utilized to label a large
unlabeled data set, and the newly labeled data set is employed to
train a SM. However, this work is limited to shallow models. The
idea, KD, was advanced in [40] to compress a deep and wide TM
into a shallower SM, where the SM mimicked knowledge learned
by the TM. Recently, KD has attracted a lot of attention. For exam-
ple, Hinton et al. [24] designed a joint loss function between the
TM and the SM to guide the SM training. In [25], Romero et al.
mapped hidden layers in the SM to the prediction of hidden layers
in the TM, and defined a loss function to train an efficient SM.
Zagoruyko et al. [26] employed attention information from the
convolutional layers of the TM to improve the SM performance.
In [27], Zhou et al. utilized parameter sharing and a new loss func-
tion to train the SM and the TM simultaneously. Besides, some
researchers [41,42] focused on using adversarial networks to
replace the manually designed loss, such as L1/L2 loss and KL
divergence.
Previous KD methods can be divided into two groups. The first
group of methods refers to that a TM is trained first on hard targets,
and then a corresponding SM is trained on hard targets and soft
targets from the TM, such as in [24–26]. However, in [27], Zhou
et al. assumed that not only the final outputs of TM but also the
learning process of TM is beneficial to train SM. Therefore, they uti-
lized the simultaneous training of SM and TM to make the learning
process of TM guide the learning of SM. Nevertheless, the opti-
mization of SM at each iteration is mainly influenced by TM, which
restricts the independence of SM, and makes TM guide SM in the
wrong direction possibly. It is just like that a student A who has
a strong learning ability guides another student B with weak learn-
ing ability to learn knowledge, but knowledge from student A
maybe not correct. In addition, in each epoch, the TM is not always
optimized in the direction of reaching the final goal, such as the
case that the loss of the TM increases, and the accuracy of the
TM decrease in a training epoch.
3. PML
In this section, the PML is described in detail. Firstly, inspired by
human learning behavior, we present the PML for the training of
lightweight CNN models, and we design a landmark loss for the
PML. Then, the landmark loss is described in detail. Finally, an
explicit algorithm flow is given for the PML implementation.
3.1. PML framework
In order to learn higher mathematics, students should learn
some preliminary elementary and middle school mathematics in
advance. In other words, not only the acquired knowledge but also
the accumulated process is important for human learning. In [28],
researches on human learning also prove that the learning process
of a teacher is significant for the learning of students. Inspired by it,
we propose the PML for the better learning of lightweight CNN
models, which mainly exploits the knowledge learned by the TM
and the learning process of the TM to guide the SM training pro-
cess. In the PML, both the learning process of the TM and the learn-
ing process of the SM are regarded as multiple learning stages. In
each learning stage of the SM, the SM is trained to approximate
the TM in the corresponding learning stage, which is different from
all previous knowledge distillation methods.
As illustrated in Fig. 2, the SM is a lightweight, CNN model for
image recognition, and all layers of the SM are divided into b
þ 1
groups that are composed of b groups with convolutional layers
and one group with FC layers. Firstly, b þ 1 groups are utilized to
construct a TM with a higher recognition accuracy, where the
jthð1 6 j 6 b þ 1Þ group in the TM has a similar structure as the
jth group in the SM, and it has more layers and more parameters
than that in the SM.
Then, the learning process of the TM with E iterations is divided
into c learning stages, where E ¼
P
c
i¼1
E
i
; 1 6 i 6 c, and E
i
denotes
the iteration number in the ith learning stage. The last state of
the TM in the ith learning stage is defined as a landmark
M
t
i
¼½f
t
1
ðx
k
Þ; ::; f
t
b
ðx
k
Þ; zðx
k
Þ; qðx
k
Þ, where f
t
j
ðx
k
Þ is the output of the
jth group and zðx
k
Þ is the output of the b þ 1th group in the TM.
Fig. 1. Knowledge distillation. (a) The framework of knowledge distillation. (b) Soft targets and hard targets.
H. Ma, S. Yang, D. Feng et al. Neurocomputing 456 (2021) 220–231
222
剩余11页未读,继续阅读
2018-12-11 上传
2023-03-17 上传
2021-02-10 上传
2021-05-31 上传
2021-04-23 上传
2021-05-26 上传
2021-05-11 上传
2021-02-03 上传
2021-04-14 上传

hb_ma
- 粉丝: 46
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
