"深入解析MapReduce计算框架及开发实践"
需积分: 0 83 浏览量
更新于2024-01-25
收藏 1.4MB PDF 举报
01-02MapReduce深入
MapReduce是一种用于并行处理大规模数据的编程模型和软件框架。它可以将大规模数据集划分为多个小数据集,然后通过分布式计算的方式进行并行处理。在本文中,我们将深入探讨MapReduce的基础知识、Hadoop Streaming开发要点和实践经验,以及MapReduce计算框架的执行流程。
首先,我们将介绍MapReduce的基础知识。MapReduce是由Google提出的用于处理大规模数据的编程模型,它包括Map和Reduce两个阶段。在Map阶段,输入数据被划分为若干个逻辑分片,然后由多个Map任务并行处理。在Reduce阶段,Map阶段的输出结果被分组合并,然后由多个Reduce任务并行处理。通过这种方式,MapReduce可以有效地处理大规模数据集,并且具有良好的容错性和可伸缩性。
接下来,我们将介绍Hadoop Streaming的开发要点。Hadoop Streaming是一种支持使用任意编程语言编写MapReduce作业的工具。通过Hadoop Streaming,可以使用脚本语言如Python或Ruby编写Map和Reduce函数,并将其作为MapReduce作业的任务提交到Hadoop集群上执行。这种灵活的开发方式为MapReduce作业的开发提供了便利,同时也拓宽了MapReduce的应用范围。
然后,我们将介绍基础实践中的MapReduce实践。通过实际案例,我们将展示如何使用MapReduce来处理真实的大规模数据集。我们将介绍MapReduce作业的开发、调试和提交流程,以及如何优化MapReduce作业的性能和资源利用率。通过这些实践经验,读者可以更好地理解MapReduce的实际应用和操作技巧。
最后,我们将深入探讨MapReduce计算框架的执行流程。我们将介绍MapReduce作业的执行过程,包括作业的提交、任务的调度和执行、作业的监控和日志输出等环节。通过了解MapReduce作业的执行流程,读者可以更好地理解MapReduce计算框架的内部工作原理,从而更好地进行作业调优和故障排查。
总的来说,本文深入探讨了MapReduce的基础知识、Hadoop Streaming开发要点和实践经验,以及MapReduce计算框架的执行流程。通过本文的阅读,读者可以更加全面地了解MapReduce的工作原理和应用方法,从而更好地进行大规模数据处理和分布式计算。
气吞山河——MapReduce深入
— —
八 斗 大 数 据 内 部 资 料 , 盗 版 必 究
— —
八斗
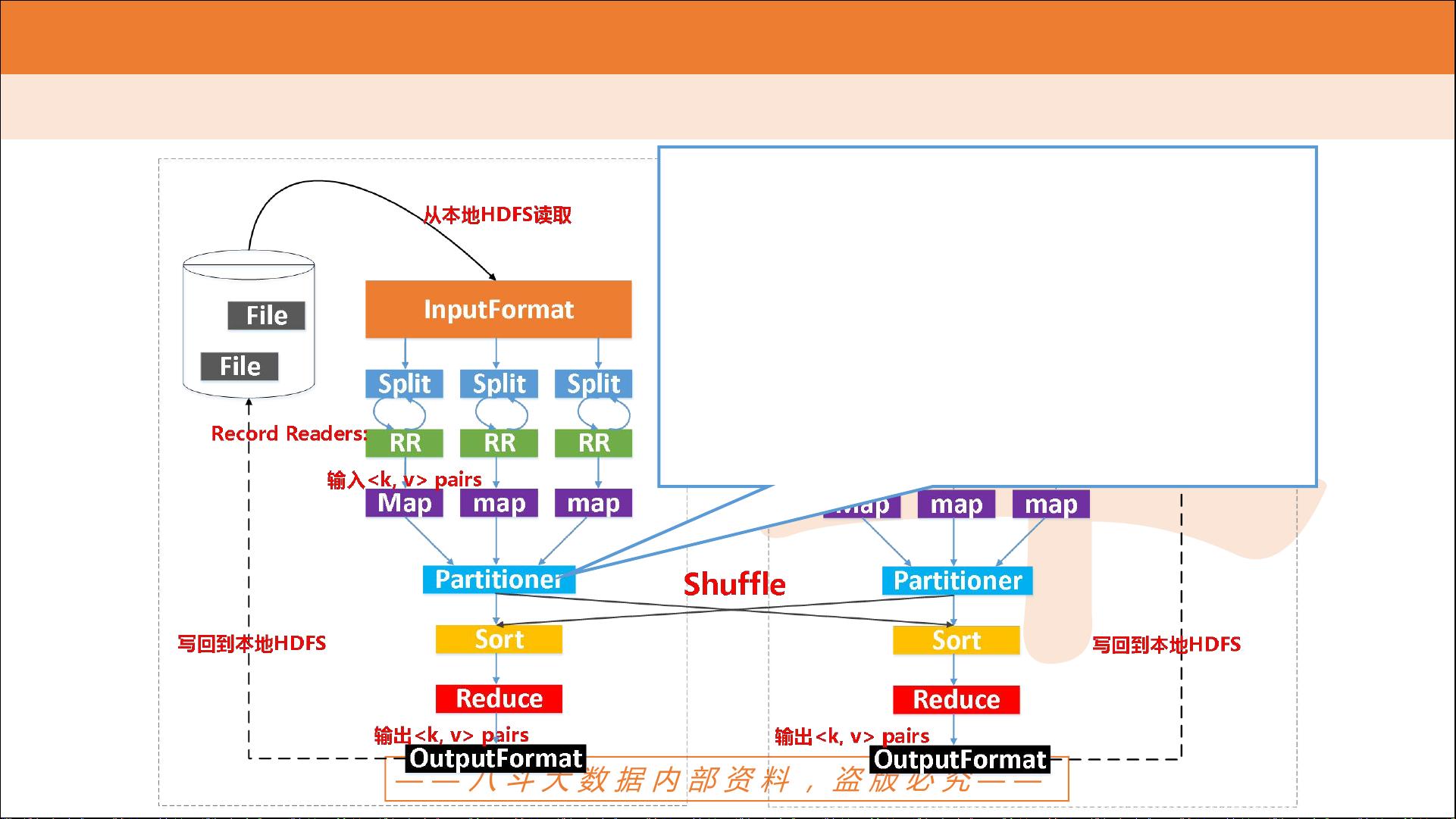
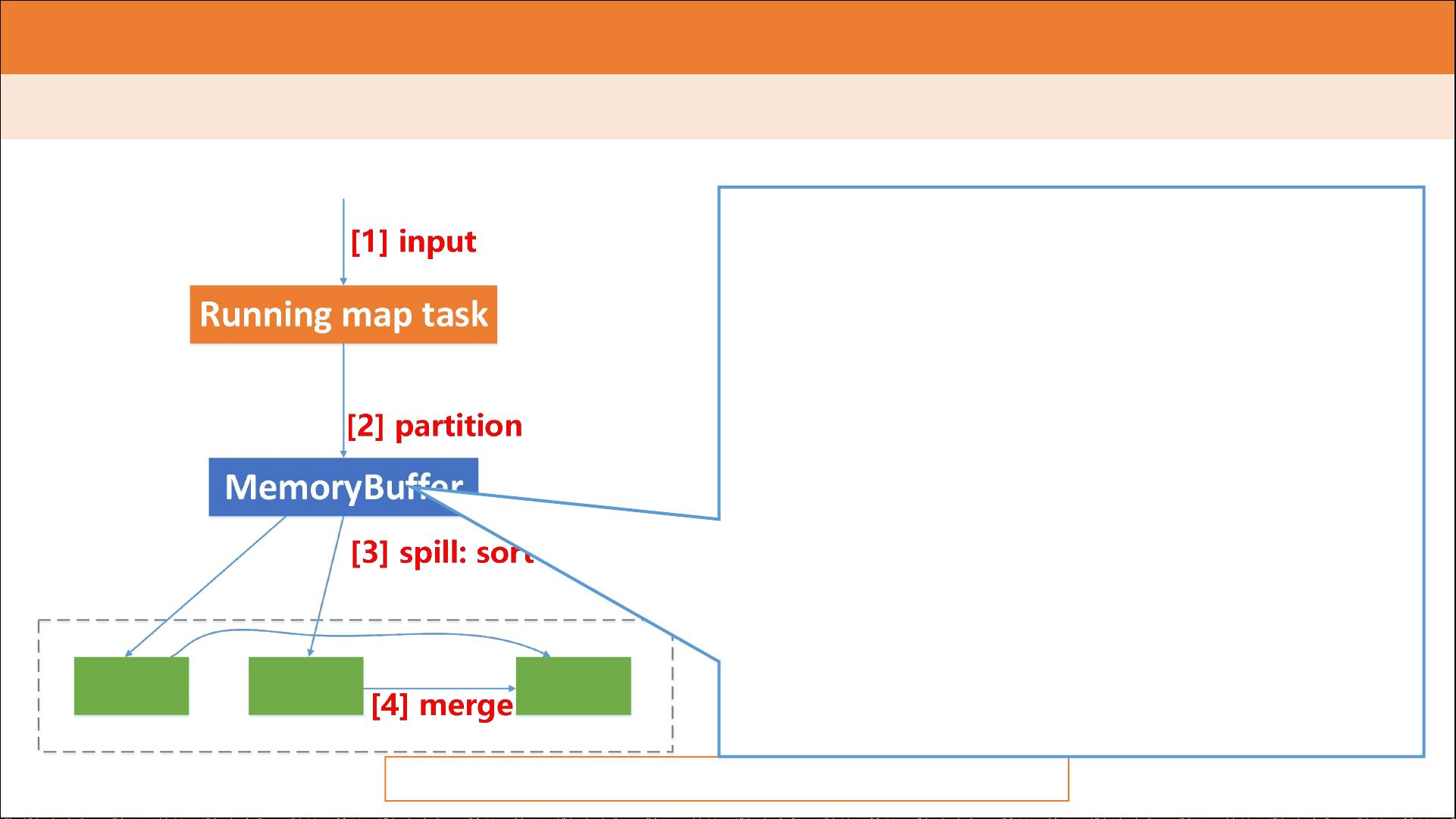
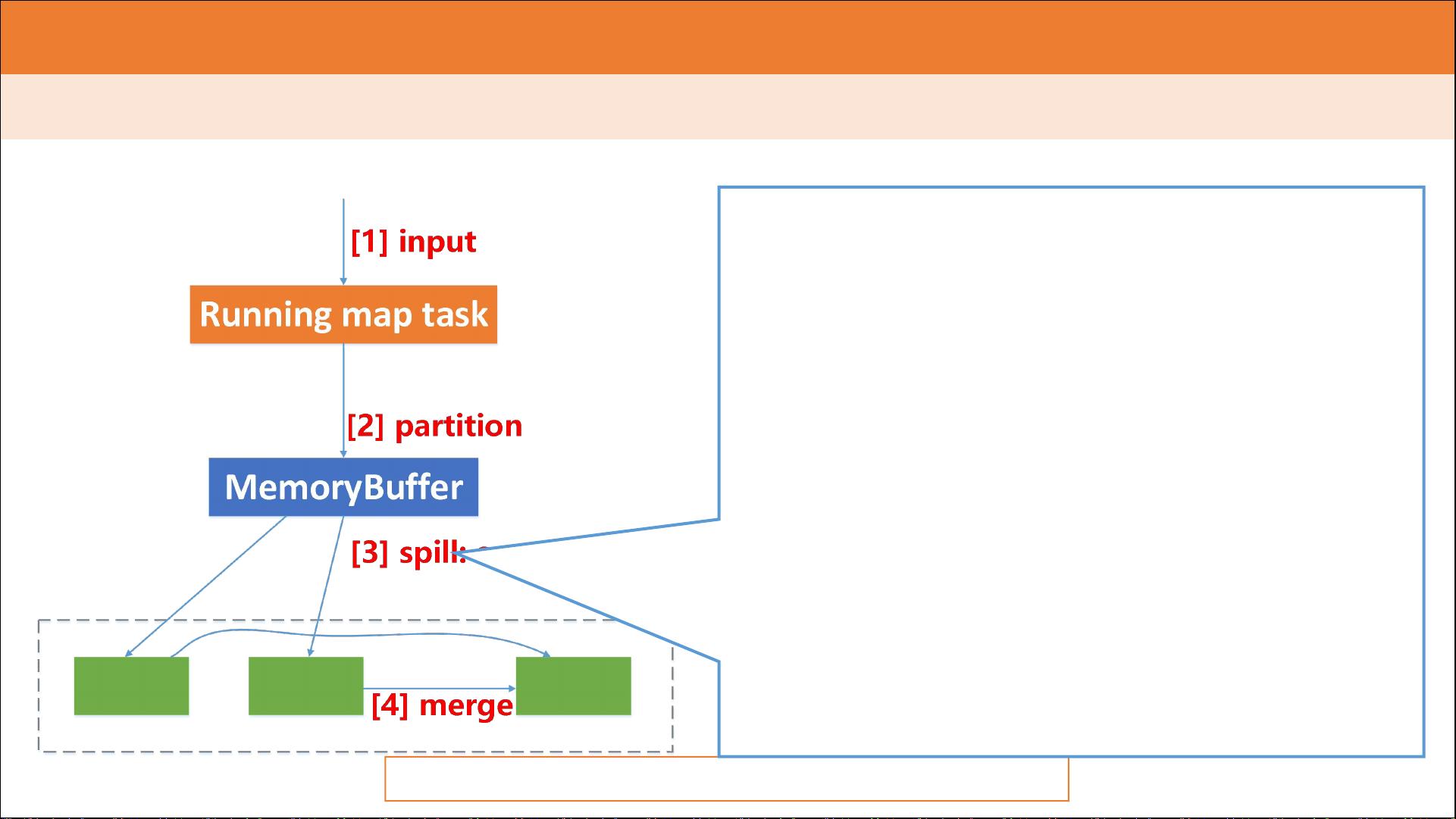
M a p R e d u c e 计 算 框 架 - 执 行 流 程
Partitioner:
决定数据由哪个Reducer处理,从而分区
比如采用Hash法,有n个Reducer,那么数
据{“are”: 1}的key“are”对n进行取模,
返回m,而生成{partition, key, value}
剩余62页未读,继续阅读
207 浏览量
128 浏览量
2022-08-08 上传
2021-09-29 上传
2021-09-29 上传
2021-09-29 上传









