深度学习检测复杂货物X射线图像中隐蔽车辆技术
需积分: 10 171 浏览量
更新于2024-07-17
收藏 9.44MB PDF 举报
"这篇论文提出了一种利用深度学习检测复杂货物X射线成像中隐蔽车辆的方法。在运输枢纽,基于X射线成像技术的非侵入式检查系统用于确保货物内容与提供的装运清单相符。随着贸易量的增长和法规的严格,手动检查效率低下。机器视觉技术可以通过自动化部分检查流程来帮助操作员。由于汽车常被用于贩运、出口欺诈和逃税,因此它们是自动检测和标记以供后续人工检查的理想目标。论文中详述了一种从零开始训练的卷积神经网络(CNN)方法,该方法能够检测X射线货箱图像中的汽车。通过引入适当的过采样策略,解决了训练用汽车图像数量少的问题,实现了在每454个图像中只有一个假阳性的条件下,100%的汽车图像分类准确率。即使汽车被其他货物部分或完全遮挡,也能正确检测到,表明该方法适用于现场部署。预计只要提供合适的训练数据,这种通用对象检测工作流程可以扩展到其他物体类别。"
在深度学习领域,卷积神经网络(CNN)是一种强大的工具,尤其在图像识别和分类任务中表现出色。在这项研究中,CNN被训练来识别X射线图像中的汽车,即使这些汽车可能被其他货物遮挡。过采样策略是解决类别不平衡问题的一种常见方法,特别是在训练数据中某一类别的样本数量较少的情况下。通过过采样,研究人员能够增加稀有类别的权重,从而提高模型对这些类别的识别能力。
在实际应用中,这样的系统可以显著提高运输安全检查的效率和准确性。传统的手动检查方法面临高负荷和低效率的问题,而深度学习驱动的自动化检测系统则可以实时分析大量图像,减少漏检的可能性。此外,这种方法还能适应犯罪分子常用的隐藏手法,如用其他货物遮挡汽车,这对于打击非法活动至关重要。
论文中的实验结果表明,该深度学习模型具有很高的性能,误报率为1/454,这意味着在大量图像中,模型能保持极低的错误报警率,同时准确地检测到所有汽车图像。这一成就意味着该方法具备在实地实施的潜力,可以进一步提升物流和运输安全。
未来的研究可能会扩展这个框架,涵盖更多的物体类别,例如其他交通工具、违禁物品等,只要提供足够的训练数据,CNN就能够学习并识别这些新类别。这将推动非侵入式检查系统的智能化发展,使它们能够处理更复杂的场景,为保障全球贸易安全提供更强大的支持。
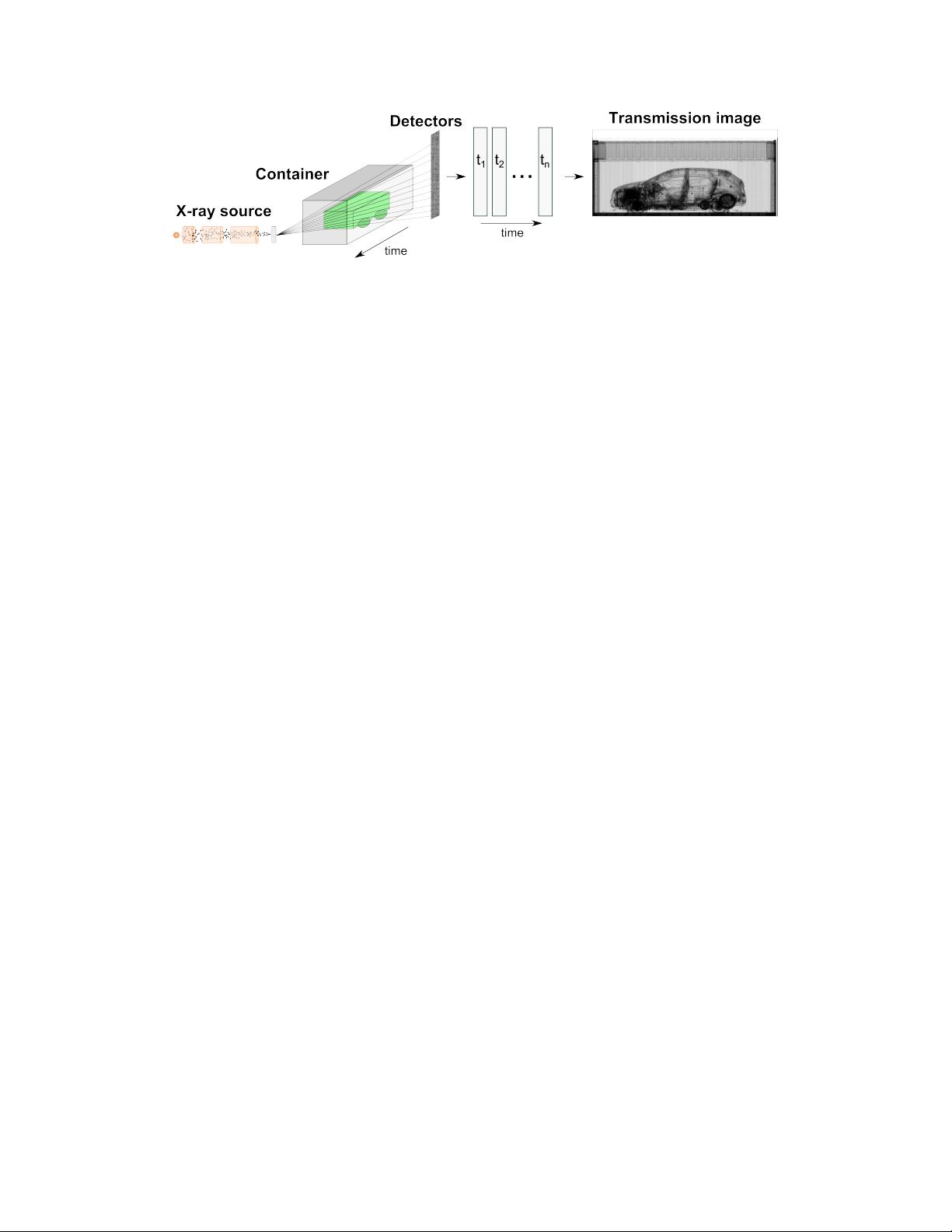
Figure 1: Illustration of the X-ray image formation and acquisition processes. Photons emitted by
an X-ray source interact with a container and its content, leading to a signal attenuation measured
by detectors placed behind the container. By moving the container or the detector, attenuations are
determined spatially and are be mapped to pixel values to produce an X-ray transmission image
is in part made possible by the relatively constrained process of baggage scanning: scene dimensions
and complexity are both bounded by the small dimensions of a bag. Multi-view (potentially volumet-
ric), multi-energy, and high resolution imaging enable discriminating between threats and legitimate
objects, with the latter being mostly identical across different baggage.
In contrast, the detection of threats and anomalies in X-ray cargo imagery is significantly more
challenging. Scenes tend to be very large and complex with little constraints on the arrangement and
packing of goods. Scanning is usually limited to a single view and the spatial resolution is much
lower than in baggage, making it especially difficult to resolve and locate small anomalous objects.
Moreover, a very high fraction of items packed in baggage are well-cataloged (e.g. clothing), whereas
potentially anything can be transported in a container making it impractical to learn the appearance
of frequent legitimate objects to facilitate the detection of threats. For these reasons, the performance
reported for cargo imagery is usually low.
Zhang et al. [
15
] built a so-called “joint shape and texture model” of X-ray cargo images based on
BoW extracted in superpixel regions. Using this model, images were classified into 22 categories
depending on their content (e.g. car parts, paper, plywood). The results highlighted the challenges
associated with X-ray cargo image classification, with only 51% of images being assigned to the
correct category. In another effort to develop an automated method for the verification of cargo
content in X-ray images, Tuszynski et al. [
5
] developed models based on the log-intensity histograms
of images categorized into 92 high-level HS-codes (Harmonized Commodity Description Coding
System). A city block distance was used to determine how much a new image deviates from training
examples for the declared HS-code. Using this approach, 31% of images were associated with the
correct category, while in 65% of cases the correct category was amongst the five closest matching
models.
With around 20% of cargo containers being shipped empty, it would be of interest to automatically
classify images as empty or non-empty in order to facilitate further processing (e.g. avoid processing
empty images with object-specific detectors) and to prevent fraud. Rogers et al. [
23
] described a
scheme where small non-overlapping windows were classified by a Random Forest (RF) based on
multi-scale oriented Basic Image Features (oBIFs) and intensity moments. In addition, window
coordinates were used as features so that the classifier would implicitly learn location-specific
appearances. The authors reported that 99.3% of SoC non-empty containers were detected as such
for a 0.7% false alarm rate and that 90% of synthetic images (where a single object equivalent
to 1L of water was placed) were correctly classified as empty for 0.51% false alarms. The same
problem was tackled by Andrews and colleagues [
24
] using an anomaly detection approach; instead
of implementing the empty container verification as a binary classification problem, a “normal” class
is defined (either empty or non-empty containers) and new images are scored based on their distance
from this “normal” class. Features of markedly down-sampled images (
32 × 9
pixel) were extracted
from the hidden layers of an auto-encoder and classified by a one-class SVM, achieving 99.2%
accuracy when empty containers were chosen as the “normal” class and non-empty instances were
considered as anomalies.
Representation-learning is an alternative to classification based on designed features, whereby the
image features that optimise classification are learned during training. CNNs, often referred to as
deep learning, are representation-learning methods [
25
] that were recently shown to significantly
3
剩余14页未读,继续阅读
2022-02-14 上传
2021-08-31 上传
2022-04-16 上传
2021-08-07 上传
2021-08-19 上传
2021-10-23 上传
2021-08-18 上传
2023-10-24 上传

qq_43674158
- 粉丝: 3
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
