CVPR2007 Bag-of-Words模型在图像识别中的应用
需积分: 7 143 浏览量
更新于2024-07-21
收藏 10.36MB PPT 举报
"CVPR2007_tutorial_bag_of_words"
在计算机视觉领域,"Bag of Words"(BoW)模型是一种广泛应用于图像分类、物体识别和自然场景理解的技术。该模型最初源于文本处理,后来被成功地应用到图像特征表示上。CVPR2007上的这个教程详细介绍了这一概念及其在图像分析中的应用。
早期的“Bag of Words”模型主要被用于纹理识别。例如,Cula & Dana (2001)、Leung & Malik (2001)、Mori等人(2001)、Schmid (2001)以及Varma & Zisserman (2002, 2003)等的研究中,这些工作奠定了BoW模型的基础。这些模型通常通过对图像的局部特征进行量化和统计来提取图像的“词汇”,并构建一个不考虑顺序的特征向量,类似于文本中的词频统计。
接着,借鉴了文档分析中的层次贝叶斯模型,如pLSA(概率潜在语义分析)和LDA(潜在狄利克雷分配),Hoffman (1999)、Blei等人(2004)以及Teh等人(2004)的工作将这些概念应用于图像处理,以更好地理解图像中的复杂结构。
BoW模型在物体分类中的应用,如Csurka等人(2004)、Sivic等人(2005)以及Sudderth等人(2005)的研究,证明了该模型在识别不同类别的物体时的有效性。模型通过创建一个“词汇库”来捕捉图像的关键视觉元素,然后将新的图像表示为这个词汇库中“单词”的频率分布。
自然场景分类也是BoW模型的重要应用领域,例如Vogel & Schiele (2004)、Fei-Fei & Perona (2005)以及Bosch等人(2006)的工作,展示了如何使用BoW模型对复杂的自然环境进行有效的分类和理解。
BoW模型与文本处理中的文档分析有强烈的类比关系。就像一篇文章是由一系列单词构成,不论它们的顺序如何,图像也可以被视为由一系列视觉“单词”(如SIFT、SURF等局部特征)组成。大脑处理视觉信息的过程,就像我们阅读和理解文字一样,是基于关键元素的识别而非单个像素的点对点传输。
CVPR2007的这个教程深入探讨了BoW模型的理论基础,发展历程,以及它在计算机视觉中的各种应用,包括纹理识别、文档分析的方法移植、物体分类和自然场景理解。这一模型的出现极大地推动了图像分析技术的进步,使得机器能够更有效地理解和解析视觉世界。

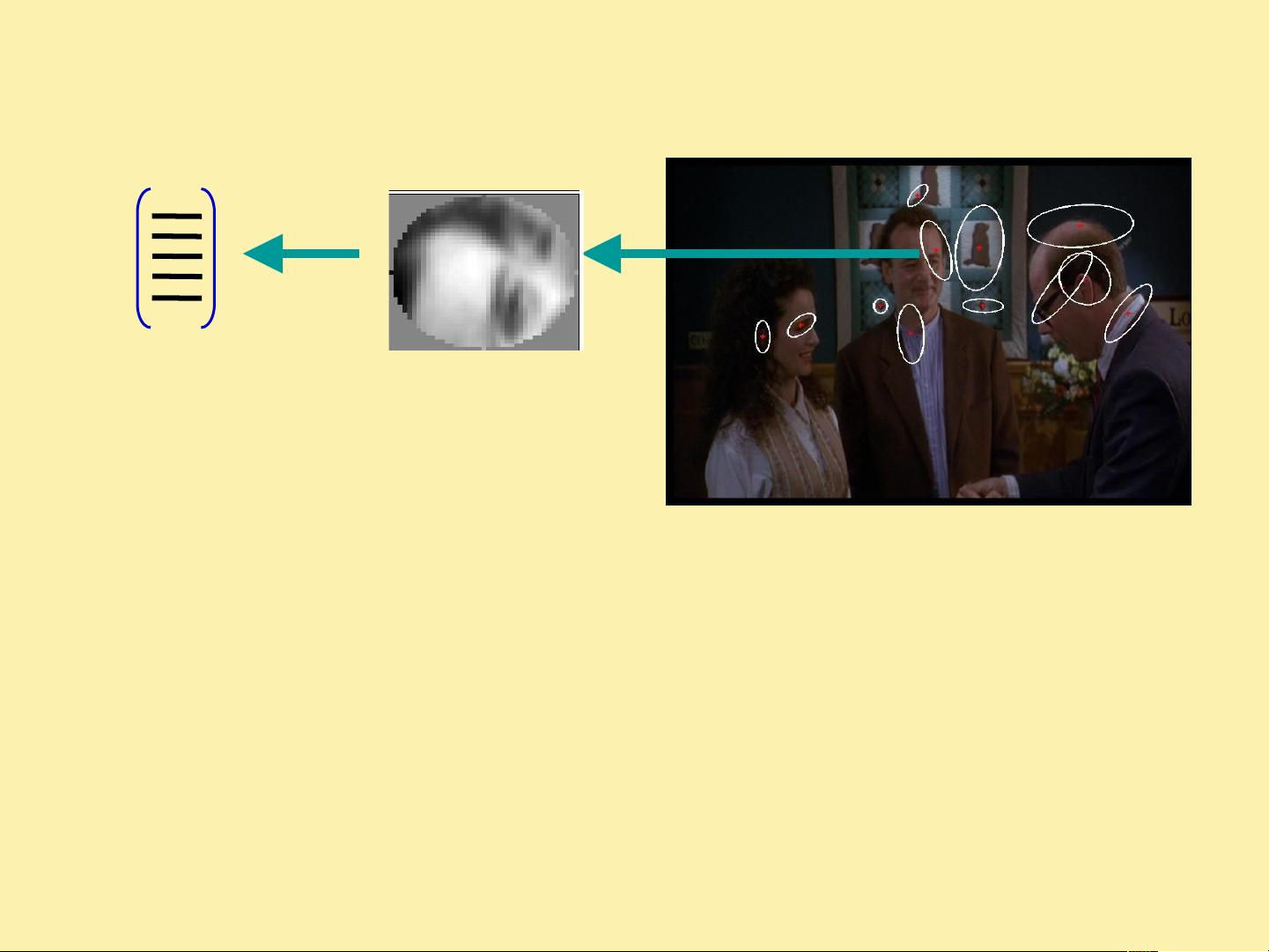
1.Feature detection
1.Feature detection
and representation
and representation
•
Regular grid
–
Vogel & Schiele, 2003
–
Fei-Fei & Perona, 2005
•
Interest point detector
–
Csurka, et al. 2004
–
Fei-Fei & Perona, 2005
–
Sivic, et al. 2005

剩余63页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2009-07-30 上传
2020-05-28 上传
2018-03-01 上传
2022-09-15 上传
2021-05-26 上传

fqss0436
- 粉丝: 2
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
