复杂模型的透明之光:可解释机器学习技术解析
需积分: 0 166 浏览量
更新于2024-08-05
收藏 725KB PDF 举报
"可解释机器学习技术1"
随着信息技术的快速发展,机器学习已经在各个领域取得了显著成就,特别是在复杂的模型如集成模型和深度神经网络(DNNs)的应用中。然而,这些模型的一个主要问题是其“黑箱”特性,即用户难以理解模型如何做出决策。这在关键决策领域如自动驾驶汽车中显得尤为突出,当模型出现非预期行为时,可能导致严重后果。为了解决这个问题,可解释机器学习应运而生,它旨在使模型能够以易于理解的方式向用户解释其决策过程,增强用户的信任感并提高系统的安全性。
可解释机器学习分为两种主要类型:内生可解释和后置可解释。内生可解释技术通过构建内在可解释的模型来实现,如决策树、规则模型、线性模型和注意力模型,这些模型在设计时就考虑了可解释性,但可能会影响预测性能。另一方面,后置可解释技术是在现有模型之外构建辅助模型来提供解释,这种方法可以保持原始模型的预测准确性,但解释可能不完全精确,因为它们是基于近似的。
为了提高模型的可解释性,研究人员和开发者一直在探索各种技术。例如,对于决策树,用户可以直接理解分支规则来明白模型的决策路径;规则模型通过一套清晰的if-then规则来解释决策;线性模型的权重系数可以直观地表示特征的重要性;注意力模型则强调输入序列中的关键部分,展示模型重点关注的信息。
此外,还有一些后置可解释技术,如局部可解释性模型(LIME)和SHAP(SHapley Additive exPlanations),它们通过近似复杂模型的局部行为来生成解释。LIME通过在模型周围的邻域内创建简单模型来解释单个预测,而SHAP则利用合作游戏理论来分配特征对预测的贡献。
可解释性不仅对用户至关重要,也对开发者和研究者有着重要价值。它可以帮助他们理解模型为何在特定情况下失效,从而改进模型设计,防止潜在的错误和偏见。同时,可解释性也有助于满足监管要求,比如在金融和医疗等领域,模型的决策过程必须透明,以便于审计和合规。
可解释机器学习是提升机器学习模型透明度的关键,它不仅促进了模型在关键应用中的采纳,还推动了机器学习领域的发展,使其更加人性化和可靠。随着技术的不断进步,我们期待看到更多创新的可解释性方法,以增进人们对AI决策的信任,并推动人工智能的广泛应用。
译文
第 16 卷 第 6 期 2020 年 6 月
80
随着诸如集成模型、深度神经网络 (DNNs) 之
类的复杂模型技术的发展,机器学习已经取得了巨
大的进步,但其自身仍存在局限性和缺陷,其中很
重要的一点就是它们的行为背后缺乏透明性,用户
很难理解机器学习模型是如何做出决策的。以先进
的自动驾驶汽车为例,虽然它使用了各种机器学习
算法,但面对一辆停止的消防车时却无法刹车或减
速。这种非预期行为让用户非常失望,并疑惑为什
么会出现这种情况。如果自动驾驶车辆正在高速行
驶,错误的决策会导致更为严重的后果,可能会使
其最终撞上消防车。复杂模型的黑盒特性,已经阻
碍了其在自动驾驶汽车等需要关键决策领域的应用。
可解释机器学习
是可以缓解该类问题的有效
工具。可解释机器学习使得机器学习模型能够以易
于理解的方式向用户解释或呈现其行为
[10]
,我们
称这种特性为可解释性 (interpretability) 或者解释性
(explainability),在本文中,这两个术语可以互换使
用。为了使机器学习更好地为人类服务以造福社会,
可解释性是必不可少的。可解释性将会增强终端用
户对机器学习系统的信任,并鼓励他们使用机器学
习系统。对于机器学习的开发者与研究者,可解释
性让其更好地理解问题、数据以及模型失败的原因,
最终提升系统的安全性。
可解释机器学习技术
*
作 者 :杜 梦 楠 刘宁昊 胡 侠
译 者 :胡 欣 宇 岳亚伟
*
本文译自
Communications of the ACM
,
“
Techniques for Interpretable Machine Learning”,2020, 63(1): 68-77 一 文 ,有 删 节 。
关键词 :
可解释机器学习
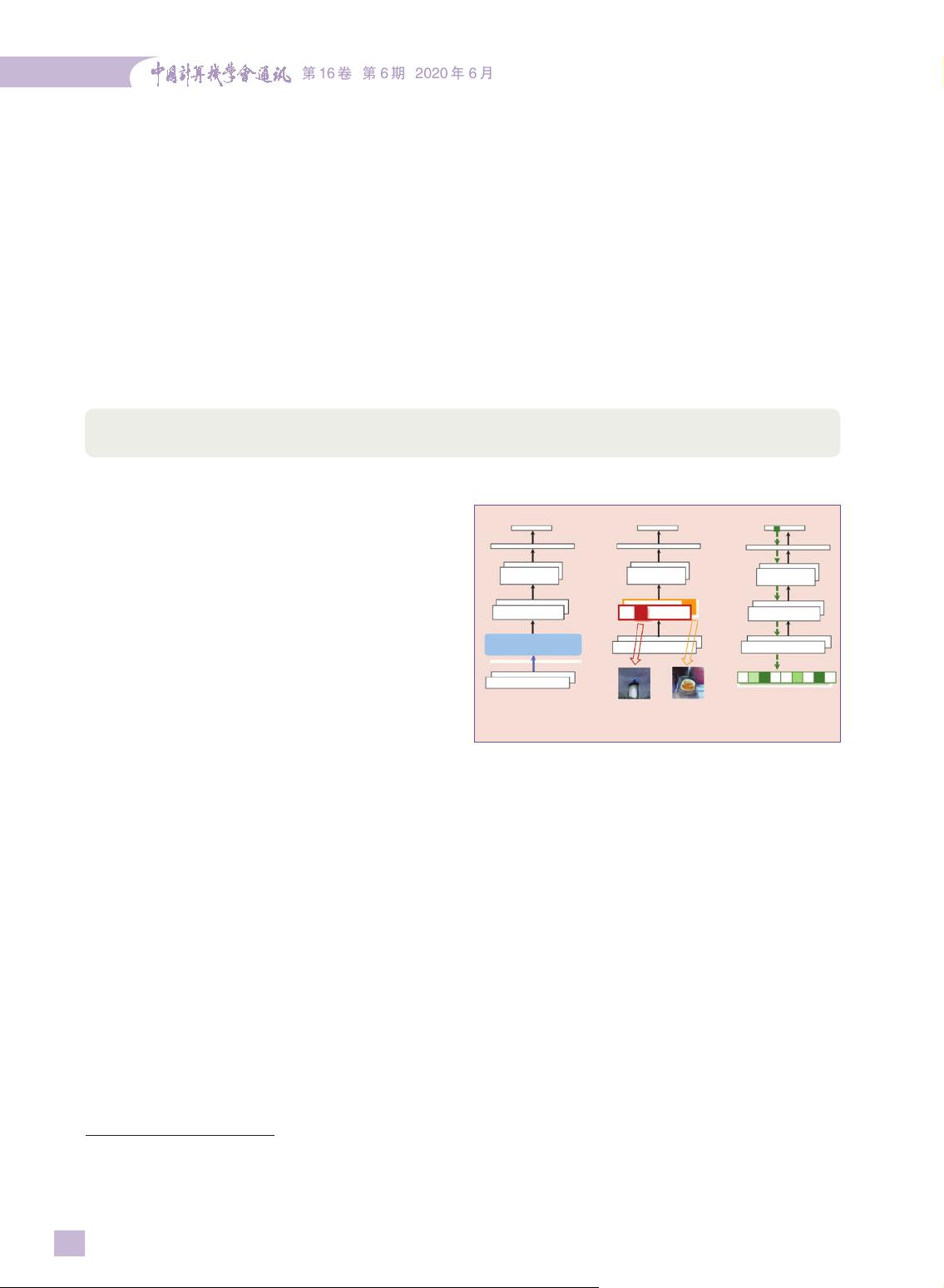
根据获取可解释能力的时间,可以将可解释机
器学习技术分为两类:内生可解释与后置可解释
[23]
。
内生可解释通过构建自身可解释模型实现,将可解
释性直接融入到模型结构。这一类模型包括决策树、
规则模型、线性模型、注意力模型等。相比之下,
后置可解释需要创建一个额外的辅助模型对原有模
型进行解释。这两类模型之间的主要区别在于模型
精度和可解释能力之间的权衡。内生可解释模型能
够提供准确、无失真的解释,但可能会在一定程度
上影响预测性能。后置可解释模型可以保证模型的
准确性,但其可解释能力受限于其近似特性。
基于上面的分类,我们进一步将可解释性分为
机器学习模型决策机制揭秘。
图 1 可解释机器学习的三条技术线(以 DNN 为例)
包含可解释限制
的新层
内生可解释方法
(全局或局部)
后置全局
可解释方法
后置局部
可解释方法
下载后可阅读完整内容,剩余9页未读,立即下载
2021-09-24 上传
2023-09-16 上传
2021-02-11 上传
2021-10-04 上传
2019-07-10 上传
2020-11-09 上传
2019-08-12 上传
2021-09-24 上传
2021-07-19 上传

高工-老罗
- 粉丝: 25
- 资源: 314
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
