理解C4.5算法:构建单变量与多变量决策树
"C4.5算法是一种用于构建单变量决策树的机器学习算法,其主要目标是通过对已知类别实例集的分析,学习如何对新实例进行分类。此外,本文还探讨了多变量决策树,这种树结构在每个节点上使用多个属性来进行分类。本文旨在解释C4.5算法的工作原理,以及如何实现构建这些决策树的算法,并提供了单变量和多变量决策树的实例结果。\n\n1. 引言\n\n模式识别的过程主要是让机器通过已知类别的实例集学习分类对象。当我们拥有一个训练集,其中实例的类别已知时,可以使用多种算法来发现实例属性向量的行为规律,以此预测新实例的类别。决策树(DT's)就是其中一种方法。\n\n2. 决策树简介\n\n决策树由两类节点组成:叶节点,标记着一个类别;或者是一个包含内部节点的结构,内部节点基于一个或多个特征将数据集分割成子集。C4.5算法是ID3算法的改进版本,它处理连续属性并能处理缺失值。\n\n3. C4.5算法工作原理\n\nC4.5算法基于信息熵和信息增益来选择最优划分属性。熵是衡量数据纯度的指标,信息增益则是通过划分减少的熵来度量。算法首先选择信息增益最大的属性作为分割点,然后递归地在子集上重复此过程,直到所有实例属于同一类别或没有更多的属性可供划分。\n\n4. 多变量决策树\n\n与单变量决策树不同,多变量决策树在每个内部节点使用多个属性来划分数据。这增加了模型的复杂性,但可能提高分类性能,特别是在属性之间存在相互作用的情况下。\n\n5. 实现与应用\n\n实现C4.5算法通常涉及以下步骤:数据预处理、选择最佳划分属性、创建树结构、剪枝优化。剪枝是为了防止过拟合,通过牺牲部分训练集的准确性来提高泛化能力。\n\n6. 示例与结果\n\n文章中可能会展示使用C4.5算法构建的单变量和多变量决策树的示例,包括它们的构建过程和分类效果。这些例子有助于理解算法的实际应用和性能。\n\n7. 结论\n\nC4.5算法因其易于理解和实施,在许多领域如数据挖掘、机器学习中广泛应用。了解其原理和实现方法对于开发和优化分类系统至关重要。\n\n关键词:C4.5算法,决策树,单变量,多变量,分类,信息熵,信息增益,剪枝"
C4.5 algorithm and Multivariate Decision Trees
Thales Sehn Korting
Image Processing Division, National Institute for Space Research – INPE
S˜ao Jos´e dos Campos – SP, Brazil
tkorting@dpi.inpe.br
Abstract
The aim of this article is to show a brief description
about the C4.5 algorithm, used to create Univariate De-
cision Trees. We also talk about Multivariate Decision
Trees, their process to classify instances using more than
one attribute per node in the tree. We try to discuss how
they work, and how to implement the algorithms that
build such trees, including examples of Univariate and
Multivariate results.
1. Introduction
Describing the Pattern Rec ognition process, the goal
is to learn (or to “teach” a machine) how to classify ob-
jects, through the analysis of an instances set, whose
classes
1
are known [5].
As we know the classes of an instances set (or train-
ing set), we c an use several algorithms to discover the
way the attributes-vector of the instances behaves, to
estimate the classes for new instances. One manner to
do this is through Decision Trees (DT’s).
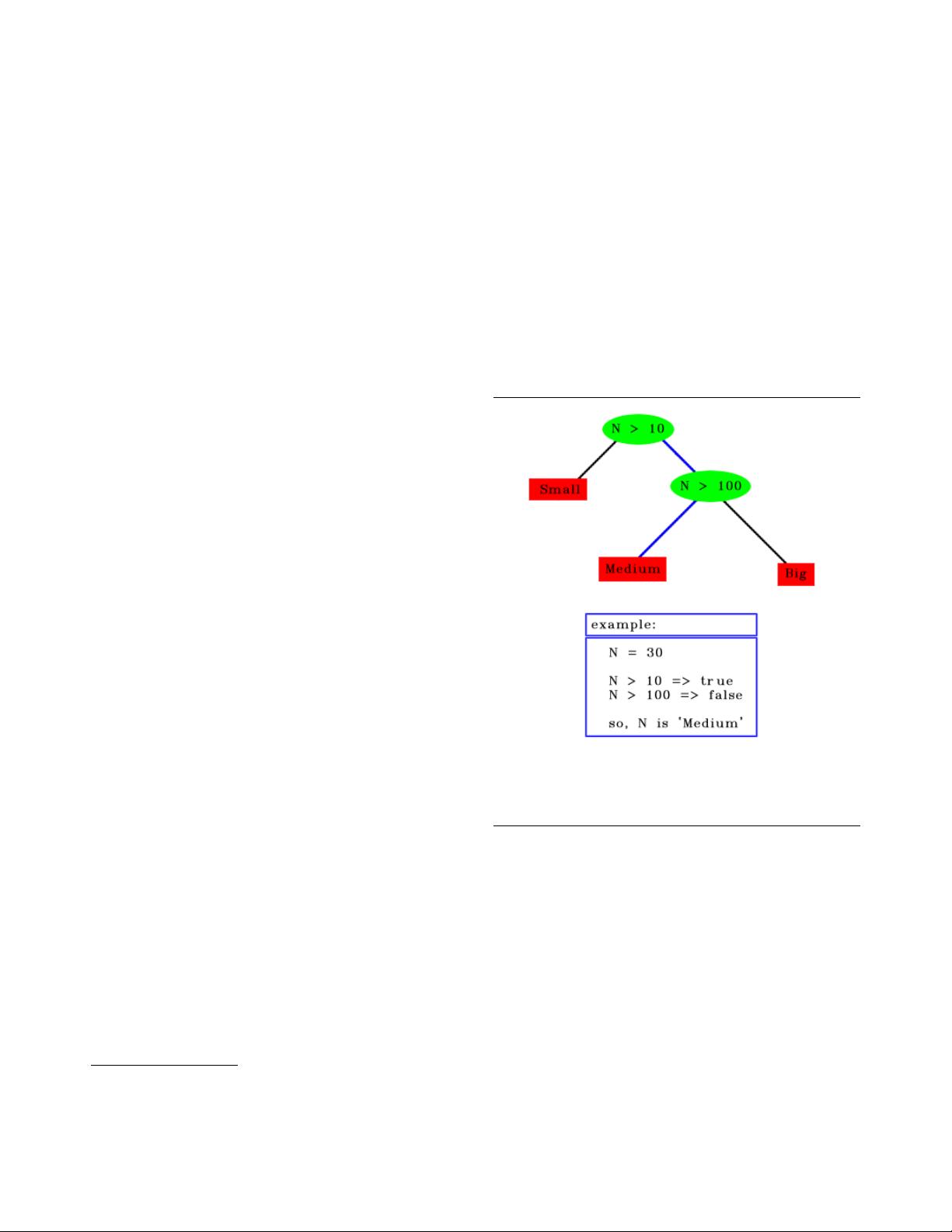
A tree is either a leaf node labeled with a class, or
a structure containing a test, linked to two or more
nodes (or subtrees) [5]. So, to classify some instance,
first we get its attribute-vector, and apply this vec-
tor to the tree. The tests are performed into these at-
tributes, reaching one or other leaf, to complete the
classification process, as in Figure 1.
If we have n attributes for our instances, we’ll have
a n-dimensional space to the classes. And the DT will
create hyperplanes (or partitions) to divide this space
to the classes. A 2D space is shown in Figure 2, and
the lines means the hyperplanes in this dimension.
1 Mutually exclusive labels, such as “buildings”, “deforest-
ment”, etc.
Figure 1. Simple example of a classification pro-
cess.
The DT’s can deal with one attribute per test node
or with more than one. T he former approach is called
Univariate DT, and the second is the Multivariate
method. This article explains the construction of Uni-
variate DT’s and the C4.5 algorithm, used to build such
trees (Section 2). After this, we discuss the Multivari-
ate approach, and how to construct such trees (Section
3). At the end of each approach (Uni and Multivari-
ate), we show some results for different test cases.
2. C4.5 Algorithm
This section explains one of the algorithms used to
create Univariate DT’s. This one, called C4.5, is based
下载后可阅读完整内容,剩余4页未读,立即下载

anthonyjack
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
