无监督多任务学习:GPT2语言模型解析
版权申诉
174 浏览量
更新于2024-06-25
收藏 730KB PDF 举报
"gpt2-language_models_are_unsupervised_multitask_learners.pdf"
这篇论文“Language Models are Unsupervised Multitask Learners”由Alec Radford等人发表,主要探讨了自然语言处理(NLP)任务如何可以利用无监督学习进行多任务学习。传统的NLP任务,如问答、机器翻译、阅读理解以及摘要生成,通常依赖于针对特定任务的监督学习数据集。然而,研究者们展示了在训练了一个名为WebText的新数据集(包含数百万个网页)上的语言模型后,这些任务可以在没有明确监督的情况下被学习。
WebText数据集是这项研究的核心,它为语言模型提供了一个大规模的无标注文本环境,使模型能够在广泛的主题和上下文中学习。通过条件化的方式,即在给定文档和问题的情况下,该语言模型能够生成答案,并在CoQA数据集上达到了55的F1分数,这与或超过了四个基线系统的3/4系统的表现,而这些基线系统使用了127,000多个训练样本。
论文指出,语言模型的能力对于零样本(zero-shot)任务转移至关重要,模型的规模越大,其性能提升越显著,且这种提升在各种任务中呈对数线性关系。他们所提出的最大模型GPT-2是一个拥有15亿参数的Transformer模型,它在无监督设置下,在测试的8个语言建模数据集中有7个达到了最先进的结果。尽管如此,GPT-2仍然未能充分利用WebText数据集,这表明还有进一步优化和学习的空间。
此外,论文还提供了从GPT-2模型生成的样本,这些样本展示出模型在理解和生成语言方面的能力。通过这种方式,GPT-2不仅证明了自身在无监督学习下的多任务学习能力,还揭示了无监督学习在NLP领域的巨大潜力,挑战了传统上依赖大量标注数据的训练方法。
这篇研究强调了无监督学习在自然语言处理中的价值,特别是大容量的语言模型在零样本任务迁移上的有效性,这对于未来NLP技术的发展有着深远的影响。它推动了我们对于如何更有效地训练模型,以及如何利用未标注文本数据的理解,可能预示着一个无需大量标注数据的新时代的来临。
Language Models are Unsupervised Multitask Learners
LAMBADA LAMBADA CBT-CN CBT-NE WikiText2 PTB enwik8 text8 WikiText103 1BW
(PPL) (ACC) (ACC) (ACC) (PPL) (PPL) (BPB) (BPC) (PPL) (PPL)
SOTA 99.8 59.23 85.7 82.3 39.14 46.54 0.99 1.08 18.3 21.8
117M 35.13 45.99 87.65 83.4 29.41 65.85 1.16 1.17 37.50 75.20
345M 15.60 55.48 92.35 87.1 22.76 47.33 1.01 1.06 26.37 55.72
762M 10.87 60.12 93.45 88.0 19.93 40.31 0.97 1.02 22.05 44.575
1542M 8.63 63.24 93.30 89.05 18.34 35.76 0.93 0.98 17.48 42.16
Table 3.
Zero-shot results on many datasets. No training or fine-tuning was performed for any of these results. PTB and WikiText-2
results are from (Gong et al., 2018). CBT results are from (Bajgar et al., 2016). LAMBADA accuracy result is from (Hoang et al., 2018)
and LAMBADA perplexity result is from (Grave et al., 2016). Other results are from (Dai et al., 2019).
<UNK>
which is extremely rare in WebText - occurring
only 26 times in 40 billion bytes. We report our main re-
sults in Table 3 using invertible de-tokenizers which remove
as many of these tokenization / pre-processing artifacts as
possible. Since these de-tokenizers are invertible, we can
still calculate the log probability of a dataset and they can
be thought of as a simple form of domain adaptation. We
observe gains of 2.5 to 5 perplexity for GPT-2 with these
de-tokenizers.
WebText LMs transfer well across domains and datasets,
improving the state of the art on 7 out of the 8 datasets in a
zero-shot setting. Large improvements are noticed on small
datasets such as Penn Treebank and WikiText-2 which have
only 1 to 2 million training tokens. Large improvements
are also noticed on datasets created to measure long-term
dependencies like LAMBADA (Paperno et al., 2016) and
the Children’s Book Test (Hill et al., 2015). Our model is
still significantly worse than prior work on the One Billion
Word Benchmark (Chelba et al., 2013). This is likely due
to a combination of it being both the largest dataset and
having some of the most destructive pre-processing - 1BW’s
sentence level shuffling removes all long-range structure.
3.2. Children’s Book Test
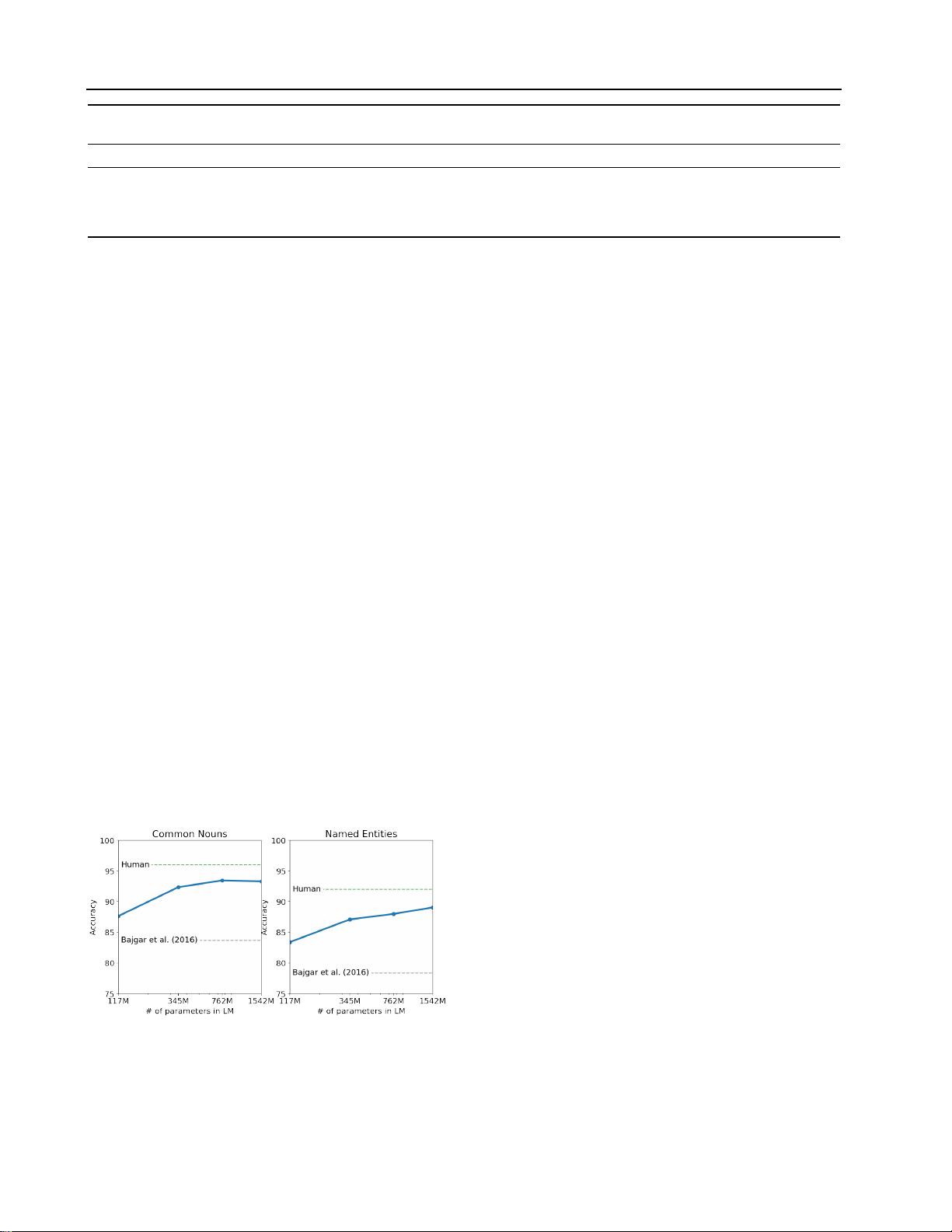
Figure 2.
Performance on the Children’s Book Test as a function of
model capacity. Human performance are from Bajgar et al. (2016),
instead of the much lower estimates from the original paper.
The Children’s Book Test (CBT) (Hill et al., 2015) was
created to examine the performance of LMs on different cat-
egories of words: named entities, nouns, verbs, and preposi-
tions. Rather than reporting perplexity as an evaluation met-
ric, CBT reports accuracy on an automatically constructed
cloze test where the task is to predict which of 10 possible
choices for an omitted word is correct. Following the LM
approach introduced in the original paper, we compute the
probability of each choice and the rest of the sentence con-
ditioned on this choice according to the LM, and predict
the one with the highest probability. As seen in Figure 2
performance steadily improves as model size is increased
and closes the majority of the gap to human performance
on this test. Data overlap analysis showed one of the CBT
test set books, The Jungle Book by Rudyard Kipling, is in
WebText, so we report results on the validation set which
has no significant overlap. GPT-2 achieves new state of the
art results of 93.3% on common nouns and 89.1% on named
entities. A de-tokenizer was applied to remove PTB style
tokenization artifacts from CBT.
3.3. LAMBADA
The LAMBADA dataset (Paperno et al., 2016) tests the
ability of systems to model long-range dependencies in
text. The task is to predict the final word of sentences
which require at least 50 tokens of context for a human to
successfully predict. GPT-2 improves the state of the art
from 99.8 (Grave et al., 2016) to 8.6 perplexity and increases
the accuracy of LMs on this test from 19% (Dehghani et al.,
2018) to 52.66%. Investigating GPT-2’s errors showed most
predictions are valid continuations of the sentence, but are
not valid final words. This suggests that the LM is not
using the additional useful constraint that the word must be
the final of the sentence. Adding a stop-word filter as an
approximation to this further increases accuracy to 63.24%,
improving the overall state of the art on this task by 4%. The
previous state of the art (Hoang et al., 2018) used a different
restricted prediction setting where the outputs of the model
were constrained to only words that appeared in the context.
For GPT-2, this restriction is harmful rather than helpful
http://chat.xutongbao.top
剩余23页未读,继续阅读
192 浏览量
631 浏览量
362 浏览量
1883 浏览量
113 浏览量
2023-08-28 上传
203 浏览量

普通网友
- 粉丝: 1283
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
