Python 3.10.0a4正则表达式(re)详细指南
需积分: 9 137 浏览量
更新于2024-08-05
收藏 970KB PDF 举报
"Python 3.10.0a4 的 re 模块文档提供了关于正则表达式的详细操作指南,适用于 Unicode 字符串和 8 位字节串。该模块提供了与 Perl 语言相似的功能,但需要注意字符串类型的匹配一致性。在编写正则表达式时,反斜杠字符(\)用于特殊符号的转义,可能导致与 Python 字符串字面值的冲突。为了避免这个问题,推荐使用 Python 的原始字符串(r'')表示法。大部分正则表达式功能以模块函数和方法的形式提供,可以直接使用,但也意味着无法自定义某些优化参数。另外,第三方模块 regex 提供了与 re 模块兼容的 API 接口,增加了额外功能和更全面的 Unicode 支持。正则表达式语法复杂,可以通过连接、组合不同的元素来构建匹配特定字符串模式的表达式。"
正则表达式在 Python 中是一个强大的工具,用于处理字符串匹配和搜索。`re` 模块包含了多种函数,如 `match()`、`search()`、`findall()` 和 `sub()`,用于执行不同的匹配和替换操作。正则表达式可以是简单的单个字符,也可以是复杂的模式,包括元字符(如 .、^、$、*、+、?、|、( )、\[ \]、{ } 等)和预定义字符类(如 \d、\D、\s、\S、\w、\W 等),这些元素可以组合起来创建几乎无限的字符串匹配规则。
在 Python 中,正则表达式模式的创建通常通过 `re.compile()` 函数完成,它返回一个正则表达式对象,可以用于多次匹配。这个过程允许设置标志,如 `re.IGNORECASE` (忽略大小写)、`re.DOTALL` (使 '.' 匹配包括换行符的所有字符) 等,以改变匹配行为。如果没有立即使用编译对象,直接调用模块函数也能达到类似效果,只是没有机会自定义这些参数。
正则表达式中的特殊字符需要转义,如 `\.` 用于匹配单个点字符,`\d` 代表数字等。原始字符串(r'')可以避免不必要的转义,使得编写正则表达式更加直观,例如 `r'\d+'` 直接表示一个或多个数字。
`match()` 函数从字符串的开始位置尝试匹配正则表达式,而 `search()` 会在整个字符串中寻找第一个匹配项。`findall()` 返回所有匹配的子串列表,`finditer()` 返回一个迭代器,逐个给出匹配对象。`sub()` 函数用于替换匹配到的文本,`subn()` 同样替换,但还返回替换次数。
对于 Unicode 字符串和 8 位字节串的处理,`re` 模块提供了相应的支持,但要求匹配时类型一致。如果需要处理 Unicode,确保模式和字符串都是 Unicode 类型;反之,如果是处理字节数据,两者都应为字节串。
最后,虽然 `re` 模块功能强大,但第三方的 `regex` 模块提供了更丰富的功能,如更多的预定义命名组、正向和负向前瞻等,以及更完善的 Unicode 处理。如果需要更高级的正则表达式功能,可以考虑使用 `regex` 替代 `re`。
2021/1/19 re --- 正则表达式操作 — Python 3.10.0a4 文档
https://docs.python.org/zh-cn/3.10/library/re.html#regular-expression-syntax 3/11
这个例子搜索一个跟随在连字符后的单词:
在
3.5
版
更改
: 添加定长组合引用的支持。
(?<!…)
匹配当前位置之前不是 ... 的样式。这个叫 negative lookbehind assertion (后视断定取非)。类似正 向后视
断定,包含的样式匹配必须是定长的。由 negative lookbehind assertion 开始的样式可以从字符串搜索开始的
位置进行匹配。
(?(id/name)yes-pattern|no-pattern)
如果给定的 id 或 name 存在,将会尝试匹配 yes-pattern ,否则就尝试匹配 no-pattern,no-pattern 可
选 , 也 可 以 被 忽 略 。 比 如 , (<)?(\w+@\w+(?:\.\w+)+)(?(1)>|$) 是 一 个 email 样 式 匹 配 , 将 匹 配
'<user@host.com>' 或 'user@host.com' , 但 不 会 匹 配 '<user@host.com' , 也 不 会 匹 配
'user@host.com>'。
由 '\' 和一个字符组成的特殊序列在以下列出。 如果普通字 符不是ASCII数 位或者ASCII字母,那么正 则样式将匹
配第二个字符。比如,\$ 匹配字符 '$'.
\number
匹配数字代表的组合。每个括号是一个组合,组合从1开始编号。比如 (.+) \1 匹配 'the the' 或者 '55 55',
但不会匹配 'thethe' (注意 组合后面的空格)。这个特殊序列只能用于匹配前面99个组合。如果 number 的第
一个数位是0, 或者 number 是三个八进 制数,它将不会被看作是一个组合,而是八进制的数字值。在 '[' 和
']' 字符集合内,任何数字转义都被看作是字符。
\A
只匹配字符串开始。
\b
匹配空字符串,但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的 序列。注意,通常 \b 定义
为 \w 和 \W 字符之间,或者 \w 和字符串开始/结尾的边界, 意思就是 r'\bfoo\b' 匹配 'foo', 'foo.',
'(foo)', 'bar foo baz' 但不匹配 'foobar' 或者 'foo3'。
默认情况下,Unicode字母和数字是在Unicode样式中使用的,但是可以用 ASCII 标记来更改。如果 LOCALE
标记被设置的话,词的边界是由当前语言区域设置决定的,\b 表示退格字符,以便与Python字符串文本兼
容。
\B
匹配空字符串,但
不
能在词的开头或者结尾。意思就是 r'py\B' 匹配 'python', 'py3', 'py2', 但不匹配
'py', 'py.', 或者 'py!'. \B 是 \b 的取非,所以Unicode样式的词语是由Unicode字母,数字或下划线构成
的,虽然可以用 ASCII 标志来改变。如果使用了 LOCALE 标志,则词的边界由当前语言区域设置。
\d
对于 Unicode (str) 样式:
匹配任何Unicode十进 制数(就是在Unicode字符目录[Nd]里的字符)。这包括了 [0-9] ,和很多其他的
数字字符。如果设置了 ASCII 标志,就只匹配 [0-9] 。
对于8位(bytes)样式:
匹配任何十进制数,就是 [0-9]。
\D
匹配任何非十进制数字的字符。就是 \d 取非。 如果设置了 ASCII 标志,就相当于 [^0-9] 。
\s
对于 Unicode (str) 样式:
匹配任何Unicode空白字符(包括 [ \t\n\r\f\v] ,还有很 多其他字符,比如不同语言排版规则约定的不
换行空格)。如果 ASCII 被设置,就只匹配 [ \t\n\r\f\v] 。
对于8位(bytes)样式:
匹配ASCII中的空白字符,就是 [ \t\n\r\f\v] 。
\S
匹配任何非空白字符。就是 \s 取非。如果设置了 ASCII 标志,就相当于 [^ \t\n\r\f\v] 。
\w
对于 Unicode (str) 样式:
匹配Unicode词语的字符,包含了可以构成词语的绝大部分字符,也包括数字和下划线。如果设置了
ASCII 标志,就只匹配 [a-zA-Z0-9_] 。
对于8位(bytes)样式:
匹配ASCII字符中的数字 和字母和下划线,就是 [a-zA-Z0-9_] 。如果设置了 LOCALE 标记,就匹 配当前语
言区域的数字和字母和下划线。
\W
匹配非单词字符的字符。这与 \w 正相反。如果使用了 ASCII 旗 标,这就等价于 [^a-zA-Z0-9_]。如果使用了
LOCALE 旗标,则会匹配当前区域中既非字母数字也非下划线的字符。
\Z
只匹配字符串尾。
绝大部分Python的标准转义字符也被正则表达式分析器支持。:
(注意 \b 被用于表示词语的边界,它只在字符集合内表示退格,比如 [\b] 。)
'\u', '\U' 和 '\N' 转义序列只在 Unicode 模式中可被识别。 在 bytes 模式中它们会导 致错误。 未知的 ASCII 字
母转义序列保留在未来使用,会被当作错误来处理。
八进制转义包含为一个有限形式。如果首位数字是 0, 或者有三个八进制数位,那么 就认为它是八进制转义。其
他的情况,就看作是组引用。对于字符串文本,八进制转义最多有三个数位长。
在
3.3
版
更改
: 增加了 '\u' 和 '\U' 转义序列。
在
3.6
版
更改
: 由 '\' 和一个ASCII字符组成的未知转义会被看成错误。
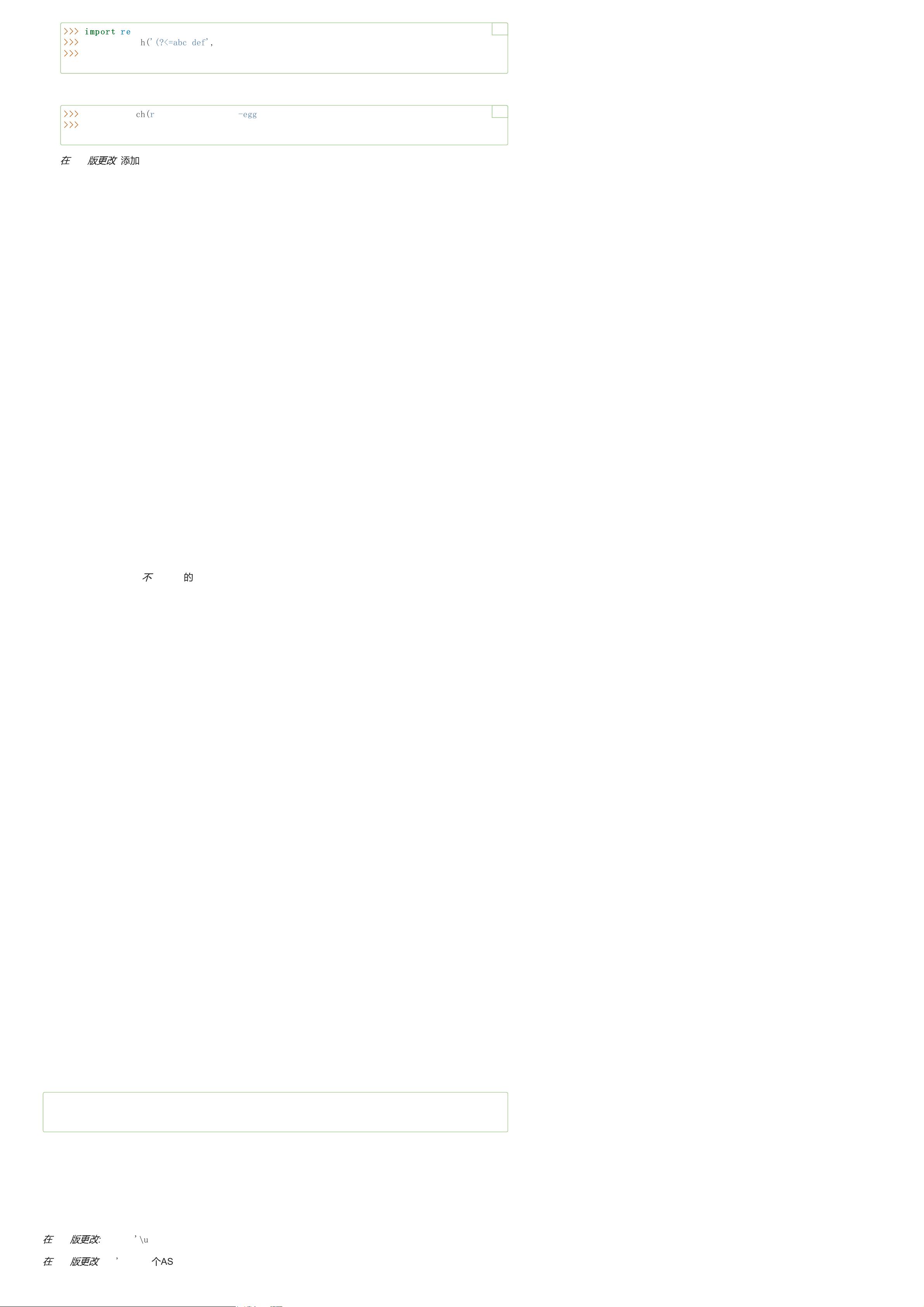
>>> import
re
>>>
m = re.search('(?<=abc)def', 'abcdef')
>>>
m.group(0)
'def'
>>>
>>>
m = re.search(r'(?<=-)\w+', 'spam-egg')
>>>
m.group(0)
'egg'
>>>
\a \b \f \n
\N \r \t \u
\U \v \x \\
剩余10页未读,继续阅读
2021-10-15 上传
2021-10-06 上传
点击了解资源详情
2024-04-08 上传
2024-04-08 上传
2021-12-03 上传
2024-04-08 上传
2024-04-08 上传
2024-04-08 上传

淋风沐雨
- 粉丝: 407
- 资源: 531
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
