Spark2.0性能提升与新特性解析
需积分: 41 10 浏览量
更新于2024-07-18
收藏 259KB DOCX 举报
Spark2.0是Apache Spark的重大更新,带来了许多新特性和性能提升,旨在增强其处理大数据分析的能力。
SparkCore与SparkSQL是此次升级的重点。在API方面,DataFrame和Dataset被统一,DataFrame现在是Dataset[Row]的类型别名,这简化了API的使用并提高了效率。SparkSession成为新的上下文入口,统一了SQLContext和HiveContext,提供了一种新的流式配置API。Accumulator功能得到增强,提供了更便捷的API、WebUI支持,并提升了性能。Dataset的聚合API也有所增强,使得数据处理更加高效。
在SQL支持上,Spark2.0遵循SQL2003标准,实现了对ANSI-SQL和HiveQL的SQL解析器。DDL命令的支持使创建和管理表变得更加方便,同时支持子查询,包括IN/NOT IN、EXISTS/NOT EXISTS等操作。新特性还包括对CSV文件的原生支持,堆外内存管理以优化缓存,以及Hive风格的bucket表。此外,还引入了近似概要统计功能,如近似分位数、布隆过滤器和最小略图。
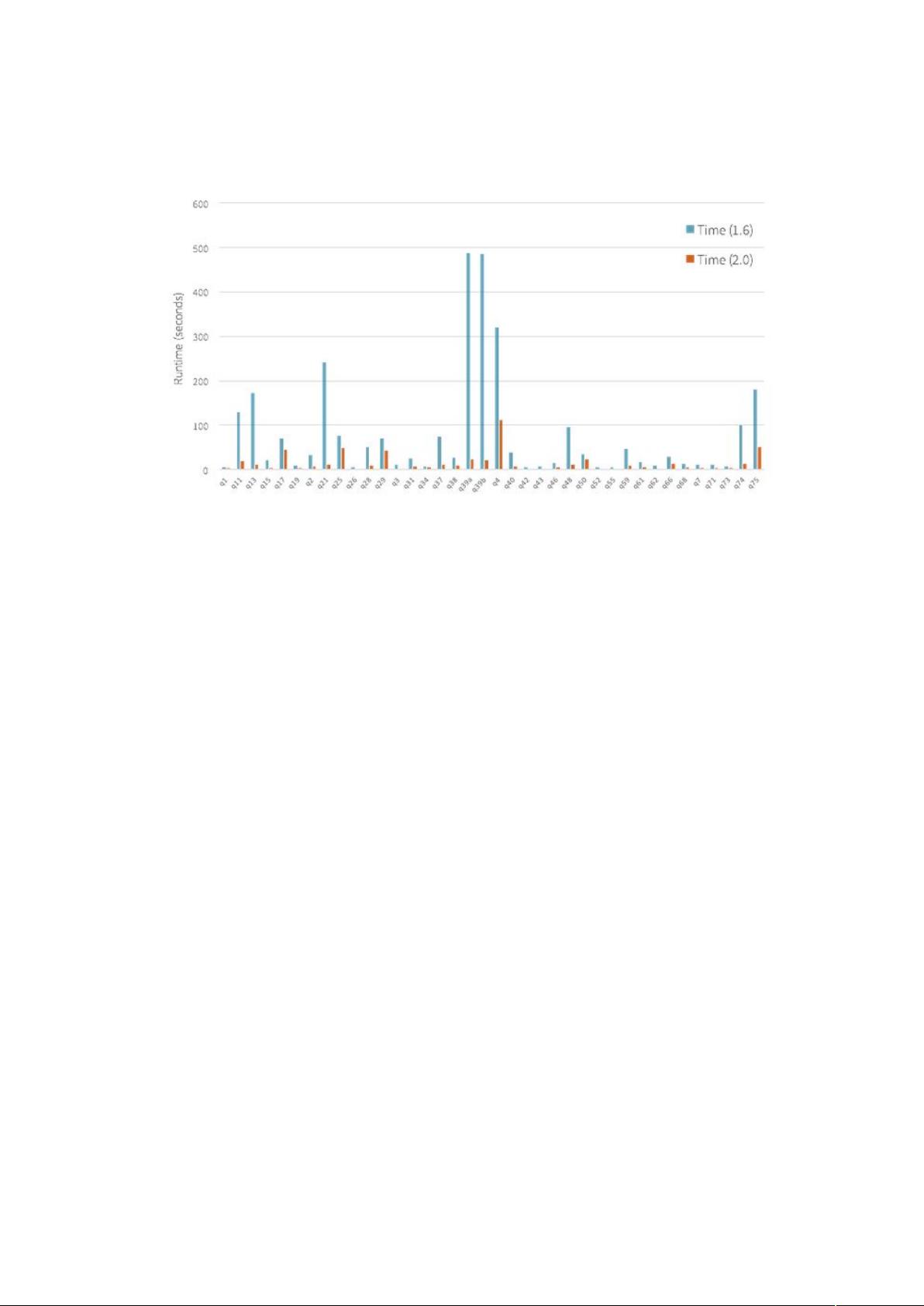
性能提升是Spark2.0的另一个关键亮点。通过全流程代码生成(Whole-Stage Code Generation)技术,Spark SQL和Dataset的执行速度可提高2到10倍。Vectorization技术提升了Parquet文件的扫描吞吐量,ORC文件的读写性能也得到了显著优化。Catalyst查询优化器的性能增强,使得查询计划更加高效。窗口函数通过原生实现方式得到加速,而且系统会自动合并某些数据源的文件,进一步提高了处理效率。
在机器学习(SparkMLlib)领域,Spark2.0倾向于基于Dataset API实现,而基于RDD的API则逐渐过渡到维护阶段。DataFrame API现在支持保存和加载模型及Pipeline。更多算法如二分KMeans、高斯混合、MaxAbsScaler等被添加到基于DataFrame的API中。SparkR和PySpark也增加了对更多MLlib算法的支持,如LDA、高斯混合、泛化线性回归等。向量和矩阵的序列化机制也得到了优化,提高了性能。
在SparkStreaming部分,Spark2.0引入了Structured Streaming的测试版,后续版本中正式发布。Structured Streaming基于Spark SQL和Catalyst引擎,允许用户使用DataFrame进行流处理,使得流计算与批处理保持一致的编程模型。
Spark2.0在API一致性、SQL兼容性、性能优化、机器学习以及流处理等方面都有显著改进,为大数据处理提供了更强大、更灵活的工具。
2.5、SparkR 中的分布式机器学习算法以及 UDF 函数
#/$ 中,为 提供了分布式的机器学习算法,包括经典的 E +
7 ,朴素贝叶斯, ,;& 等。此外 还支持用户自定义的函
数,即 F-G。
3、Spark 2.0-高性能:让 Spark 作为编译器来运行
在一个 #$*H 年的 调查中显示,C*D的 用户是因为 的高性能才选择使用它
的。所以 的性能优化也就是社区的一个重要的努力方向了。*/ 相较于 '
来说,速度已经快了数倍了,但是 #/ 中,还能不能相较于 */ 来说,
速度再提升 *$ 倍呢?
带着这个疑问,我们可以重新思考一下 的物理执行机制。对于一个现代的大数据处
理引擎来说,3F 的大部分时间都浪费在了一些无用的工作上,比如说
,或者从 3F 缓冲区中读写数据。现代的编译器为了减少 浪费在上述工作的时间,
付出了大量的努力。
#/$ 的一个重大的特点就是搭载了最新的第二代 引擎。第二代 引擎
吸取了现代编译器以及并行数据库的一些重要的思想,并且应用在了 的运行机制中。
其中一个核心的思想,就是在运行时动态地生成代码,在这些自动动态生成的代码中,可
以将所有的操作都打包到一个函数中,这样就可以避免多次 ,而且还可
以通过 来读写中间数据,而不是通过 ' 来读写数据。上述技术整体被
称作“' &I,中文也可以叫“全流程代码生成”。
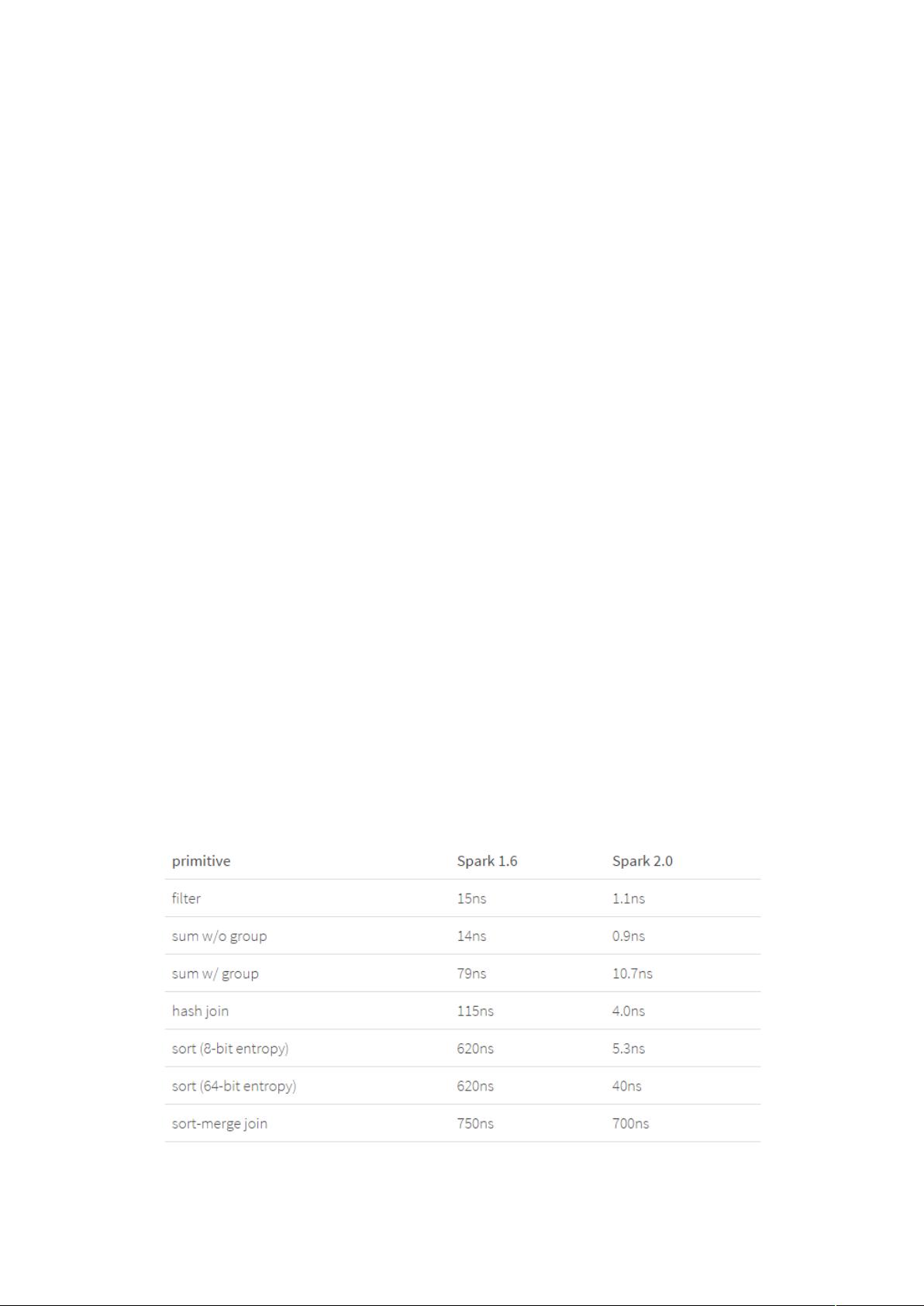
之前有人做过测试,用单个 来处理一行数据,对比了 */A 和 #/$ 的性能。
#/$ 搭载的是 ' & 技术,*/A 搭载的是第一代 引
擎的 技术。测试结果显示,#/$ 的性能相较于 */A 得到
了一个数量级的提升。
剩余25页未读,继续阅读
431 浏览量
215 浏览量
2021-04-14 上传
167 浏览量
131 浏览量
2018-09-27 上传
2021-10-05 上传
130 浏览量

jpdcxz
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







