XPath与XPointer在XML处理中的关键应用与DOM树定位技巧
需积分: 0 73 浏览量
更新于2024-08-04
收藏 734KB DOCX 举报
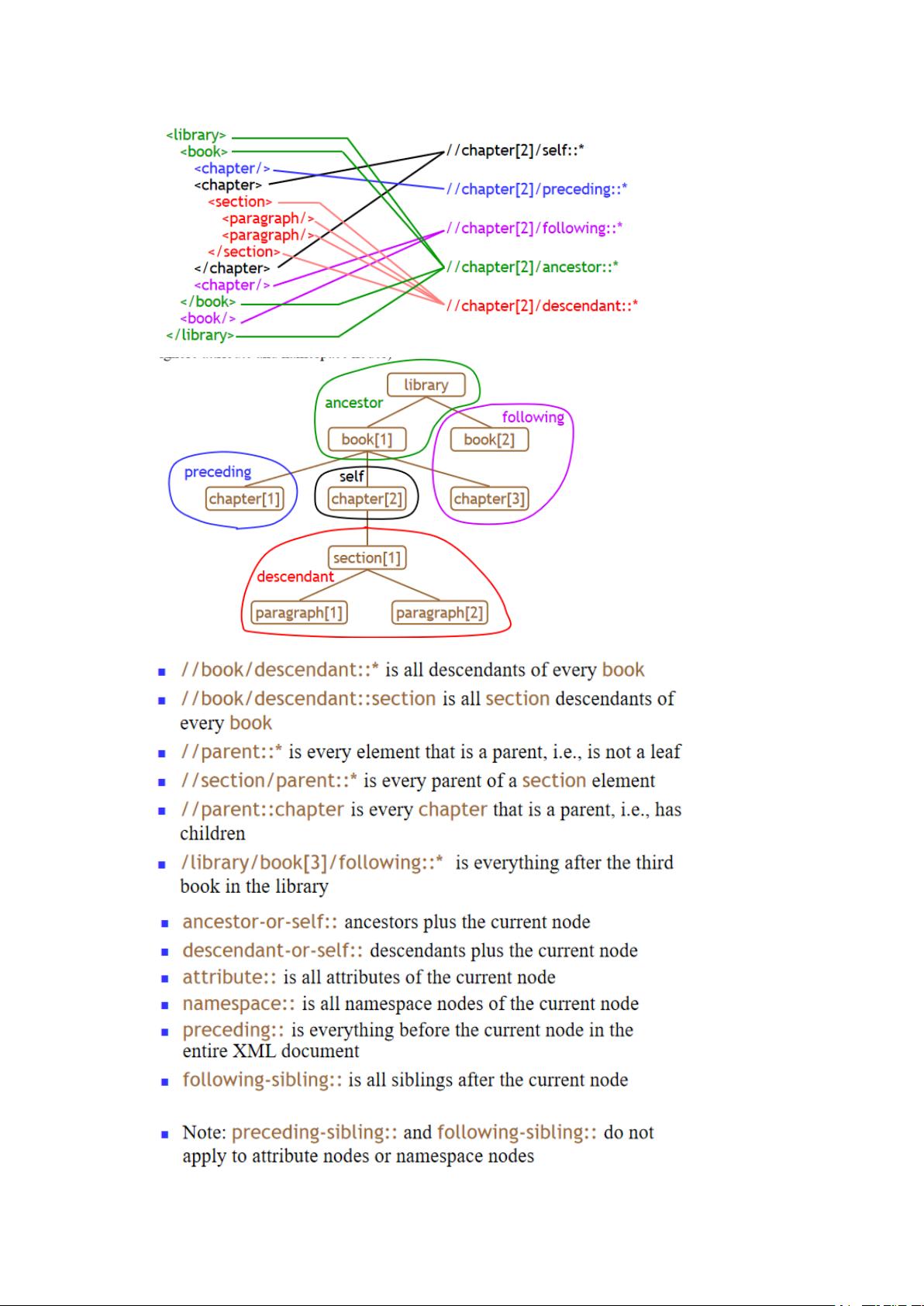
在第二部分1中,主要讨论了关于XML文档对象模型(DOM)树的处理以及XPath和相关技术在HTML和XML文档中的应用。XPath是一种强大的语言,用于在XML文档结构中定位节点和片段,它在XPointer、XPoint、XSLT(可扩展样式表语言转换)和XMLSchema等工具中扮演着关键角色。XPath表达式可以指定从文档根节点(如`/library/book/chapter/section`)出发,通过节点选择器和属性测试来查找特定节点。
例如,XPath表达式`/library/book[1]/chapter[1]/section[2]`表示从library节点的第一个book子节点找到第一个chapter子节点,然后进入第二个section子节点。`last()`函数可以用来获取最后一个匹配的节点,如`book/chapter[last()-1]`。
在DOM树的表示中,需要注意的是,属性和文本都被视为节点,它们都有自己的位置和标识。比如,`//chapter[normalize-space(@num)="3"]`表示查找所有`num`属性值经`normalize-space()`函数处理后等于"3"的`chapter`节点。`normalize-space()`函数在此用于消除比较时的空格影响,使其标准化。
同时,XPath还支持条件选择,如`/catalog/cd[price<10]`用于筛选价格低于10的`cd`元素。更复杂的表达式,如`//title|//price`,用于选择文档中的所有`title`和`price`节点。通过使用`//*`选择器,可以选取所有节点;而`//*[price==9.90]`则只选中price属性值为9.90的`cd`元素。
对于属性的选择,XPath提供了丰富的语法。例如,`//chapter[@country="UK"]`选择所有`country`属性值为"UK"的`chapter`节点,`//chapter[@*]`表示有任意属性的`chapter`,而`//chapter[not(@*)]`则表示没有属性的`chapter`。
在处理XML文档时,特别指出XML属性中的特殊字符,如`<`和`>`,在XPath中不能直接使用,可能需要转义或者采取其他方式处理,这一点在XSLT中尤其要注意,因为它有自己的规则和安全限制。
这部分内容深入讲解了如何利用XPath进行高效且精确的XML文档查询,并强调了DOM树结构的理解对有效使用这些技术的重要性。同时,它也提到了XSLT在转换XML文档时处理属性的要求,确保了在实际开发中的兼容性和安全性。
剩余11页未读,继续阅读
2020-04-03 上传
2010-02-27 上传
2011-03-20 上传

简甜XIU09161027
- 粉丝: 33
- 资源: 310
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
