深度解析:自动编码器原理与应用
自动编码器讲义
自动编码器是一种强大的深度学习工具,它在数据压缩和特征学习领域发挥着核心作用。它的基本原理是设计一个神经网络模型,由两个主要部分组成:编码器和解码器,它们相互协作以重构原始输入。自动编码器的目标是学习数据的潜在低维表示,同时尽量保持这个表示能够准确地重建输入信号。
1. 自动编码器概述:
自编码器的核心概念是,它尝试从输入数据中提取出关键特征,通过编码器(非线性变换)将数据转换成一个简化的表示,即编码或内部表示,然后解码器再尝试从这个表示中恢复原始数据。这是一个有损压缩的过程,因为不是所有的细节都能被完美保留。损失函数,如平方误差或交叉熵,用来衡量重建数据与原始输入之间的差异,目标是最小化这个误差。
2. 不同类型的自编码器:
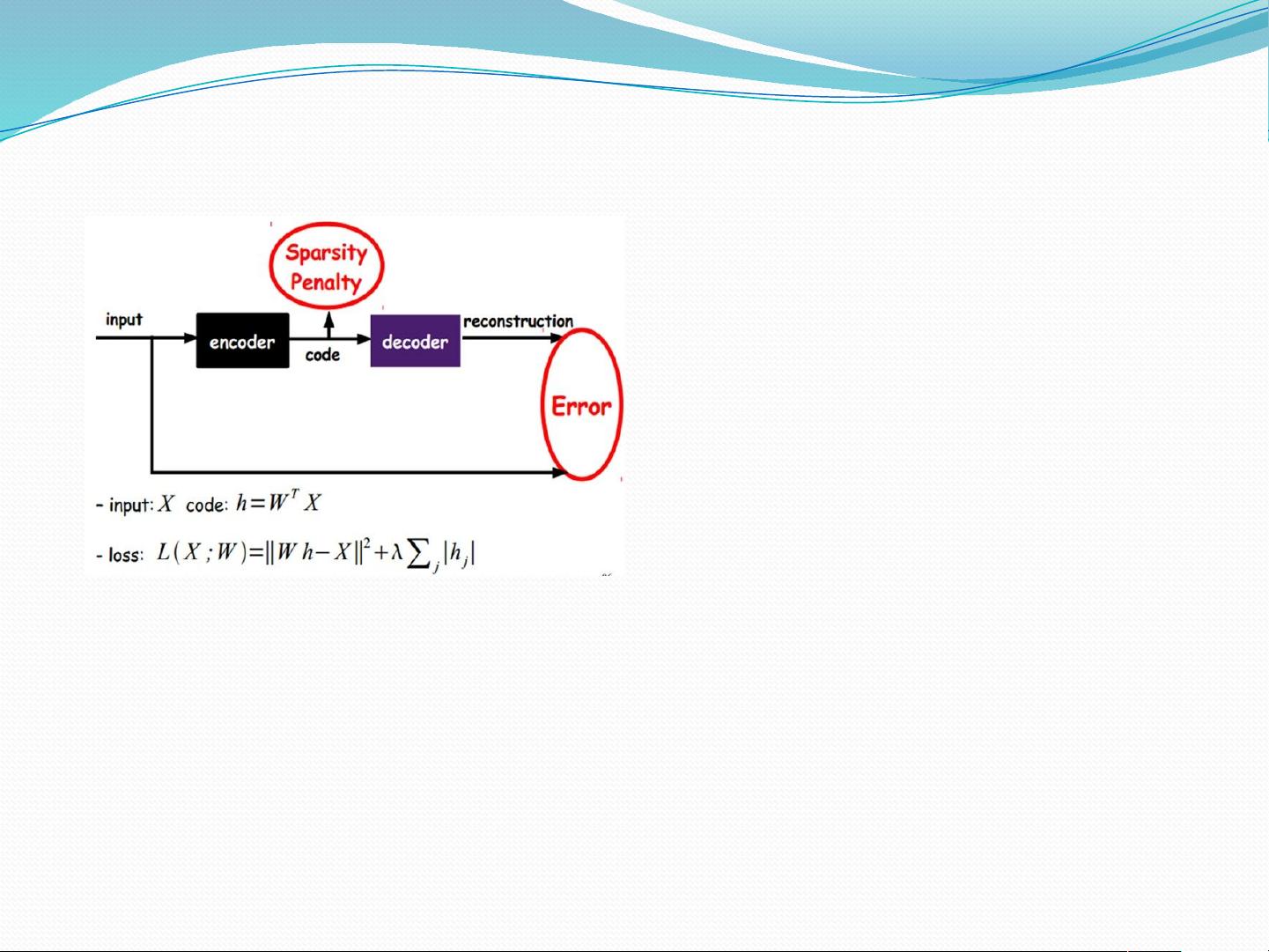
- 稀疏自编码器:引入了稀疏性约束,鼓励编码表示中包含更少的活跃神经元,从而增强模型的表示能力和泛化能力。
- 栈式自编码器:通过堆叠多个自动编码器,形成多层结构,提升对复杂数据的处理能力。
- 去噪自编码器:在输入数据中添加噪声,训练模型在噪声背景下重构数据,增强模型的鲁棒性和对异常值的处理。
- 压缩自编码器(对比性自编码器):通过对比不同的输入版本来学习更有区分性的编码,有助于提高模型的泛化性能。
3. 折中选择:
自动编码器的设计需要在重建误差和模型表达能力之间找到平衡。通过区分需要表示的重要变量,编码器可以在流形方向上保持敏感,而在正交方向上压缩表示,从而避免过拟合。
4. 损失函数的选择:
选择适当的损失函数取决于输入数据的特性。对于连续实值数据,通常使用平方误差;而对于离散的类别数据,交叉熵更为合适,因为它考虑到了每个类别的概率分布。
5. 交叉熵与条件分布:
在训练过程中,解码函数可以看作是对条件分布P(x|h)的估计,而编码函数则对应Q(h|x),两者一起构成了自动编码器的完整学习过程。
总结来说,自动编码器是一种深度学习工具,通过学习数据的压缩表示和重构策略,既实现了数据降维,又提供了对数据潜在结构的理解。通过不同类型的自编码器和合适的损失函数,可以灵活地调整模型的复杂度和泛化能力,使其在实际应用中具有广泛的价值。
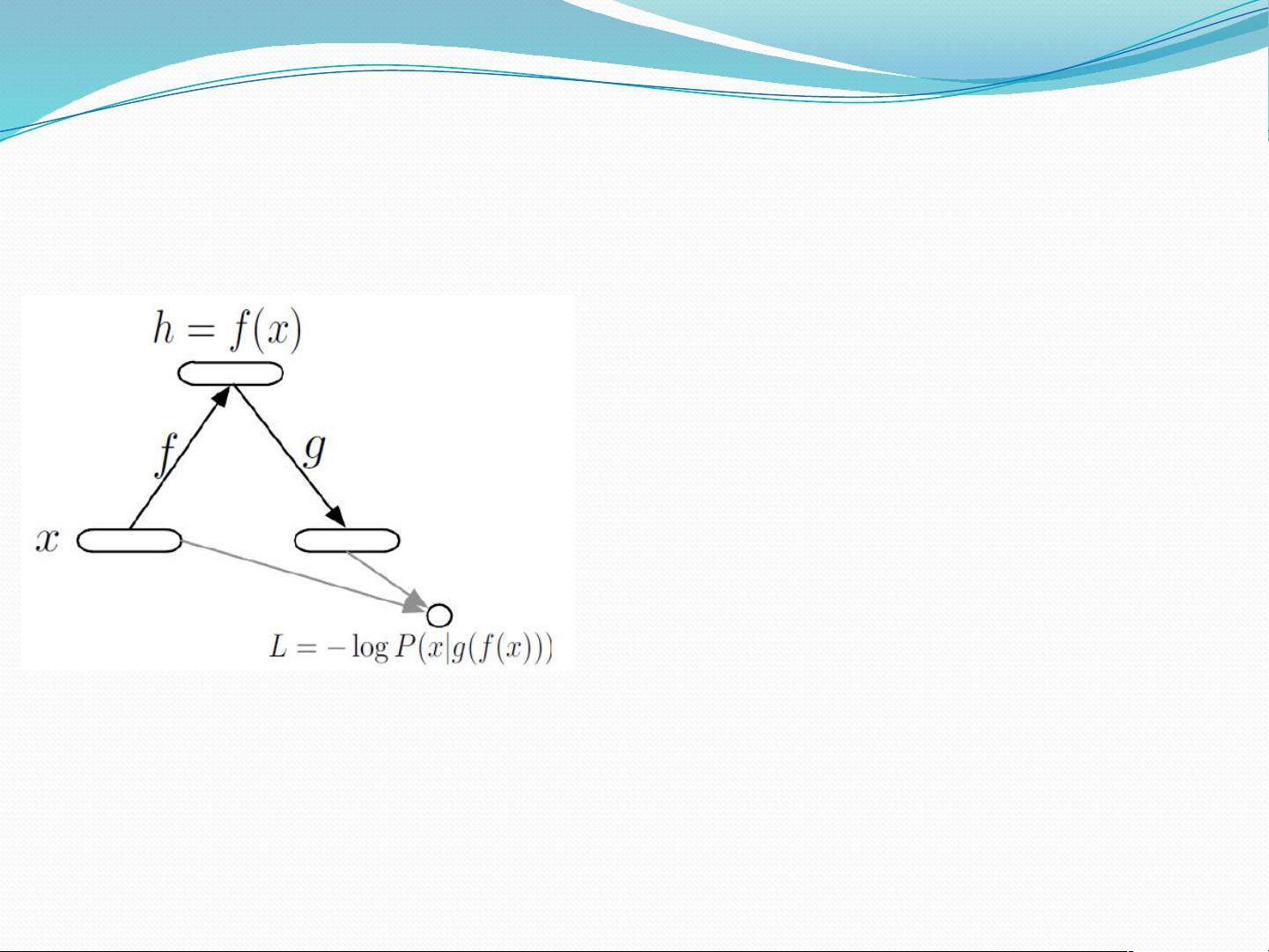
自编码简介( Autoencoder )
重建误差的概率解释
目标函数:
损失函数的选取取决于输入数据的类型:如
果输入是实数值,无界值,损失函数使用平
方差( squared error );如果输入时位矢量,
交叉熵( cross-entropy )更适合做损失函数。
什么是交叉熵?
p 和 q 分布的交叉熵是: p 分
布的信息熵和 p 和 q 的 DL 散度
的和。
我们可以认为训练一个解码函数等同于对
条件分布 P(x|h) 的估计;同样的道理,可
以将编码函数理解为一个条件分布 Q(h|x),
而不仅仅是一个“干巴巴”的函数式子。
log ( | ( ( )))L P x g f x
( , ) [ log ] ( ) ( || )
p KL
H p q E q H p D p q
剩余37页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-11-20 上传
2011-02-15 上传
2023-07-18 上传
2013-10-13 上传
2011-09-10 上传
2022-11-13 上传

wei.yinfu
- 粉丝: 9
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
