Hadoop分布式文件系统:高吞吐量与容错性设计
需积分: 0 198 浏览量
更新于2024-09-16
收藏 88KB DOC 举报
"Hadoop分布式文件系统"
Hadoop分布式文件系统(HDFS)是Apache Hadoop项目的核心组件之一,旨在提供高容错性和高吞吐量的数据访问能力,尤其适用于处理和存储大规模数据集。HDFS设计的目标是能够在经济实惠的商用硬件上运行,考虑到硬件故障的常态性,它强调快速的错误检测和自动恢复机制。
HDFS的设计原则是流式数据访问,这意味着它优化了数据批量处理而非实时交互。文件系统的设计允许应用程序以连续、非随机的方式读取数据,牺牲了一些POSIX标准的严格要求,以换取更高的数据传输速度。因此,HDFS并不适用于需要低延迟访问的应用,而是更适合那些需要大量数据读取的应用,如大数据分析、机器学习和MapReduce作业。
在规模上,HDFS支持存储非常大的文件,从几GB到几TB,甚至更大。这种能力使得它能够在一个集群中扩展到数百个节点,提供大规模的并行处理能力。HDFS通过将文件分割成多个块,并将这些块复制到不同的节点上,实现了高可用性和容错性。默认情况下,每个数据块有三个副本,这样即使有节点故障,系统也能保证数据的可访问性。
HDFS采用了一种简单的一致性模型,即“一次写入,多次读取”(WAL, Write-Once, Read-Many)。文件一旦写入完成,就不再进行修改,这简化了数据一致性管理,并有助于实现高效的读取性能。这种模型特别适合于数据批处理任务,例如地图减少(MapReduce)框架,以及那些需要稳定、不可变数据源的其他应用。然而,未来版本的HDFS计划引入对文件追加写入的支持,以适应更多样化的工作负载需求。
“移动计算比移动数据更划算”是HDFS设计的一个重要理念。由于处理大数据时,网络传输成本高昂,HDFS鼓励将计算任务移动到数据所在的节点执行,而不是将大量数据传输到单个处理中心,从而减少了网络拥堵,提高了整体效率。这种设计原则在分布式计算环境中尤为关键,尤其是在处理PB级别的数据时。
总结来说,HDFS是一个面向大规模数据处理的分布式文件系统,它通过在廉价硬件上构建高可用性和高性能的集群,提供流式数据访问和高吞吐量的数据处理能力。其设计哲学包括容忍硬件故障、优化批量数据处理、支持大规模数据集,并提倡计算接近数据的策略,以满足大数据时代的需求。
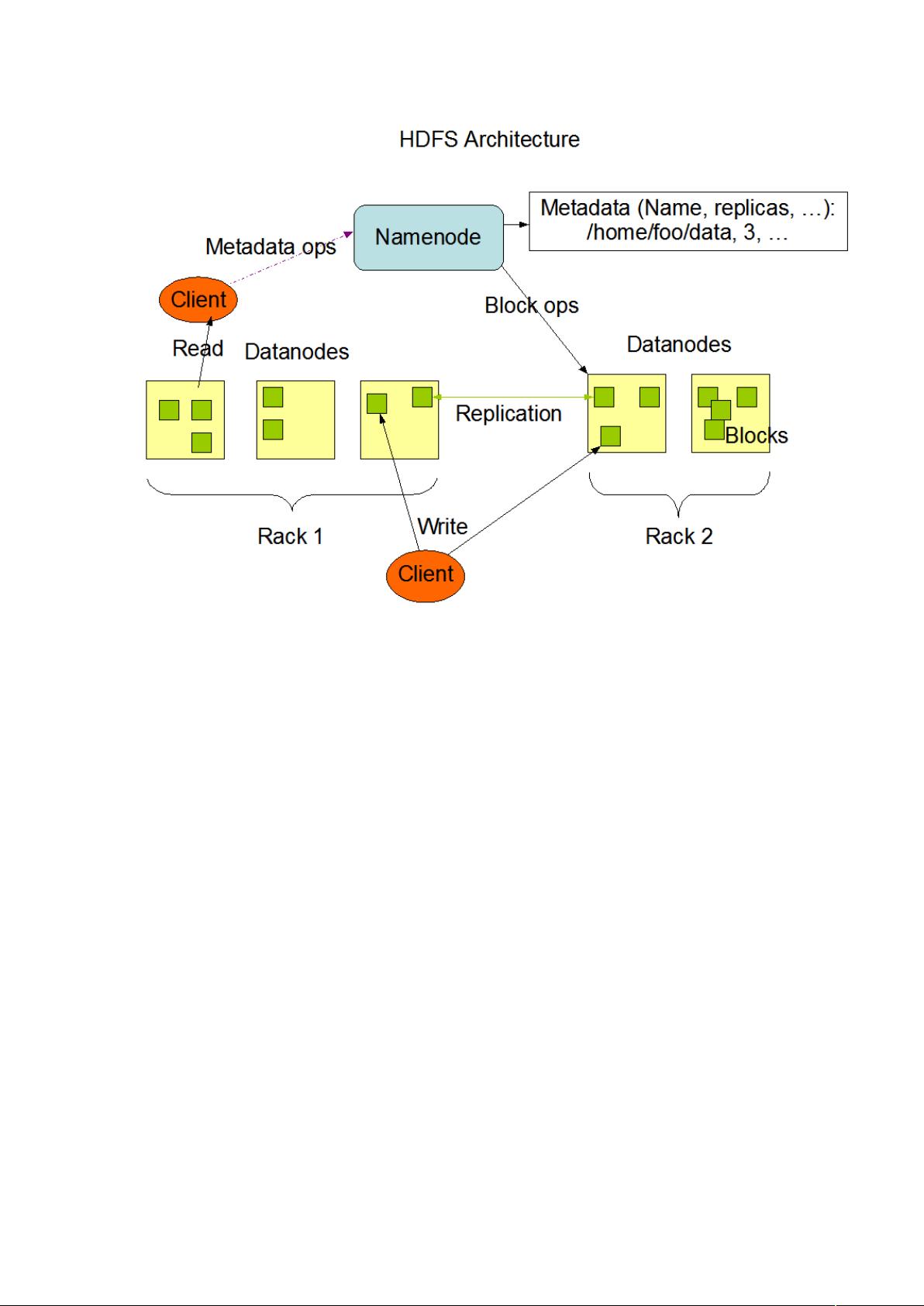
Namenode 和 Datanode 被设计成可以在普通的商用机器上运行。这些机器一般
运行着 GNU/Linux 操作系统(OS)。HDFS 采用 Java 语言开发,因此任何支持
Java 的机器都可以部署 Namenode 或 Datanode。由于采用了可移植性极强的
Java 语言,使得 HDFS 可以部署到多种类型的机器上。一个典型的部署场景是一
台机器上只运行一个 Namenode 实例,而集群中的其它机器分别运行一个
Datanode 实例。这种架构并不排斥在一台机器上运行多个 Datanode,只不过
这样的情况比较少见。
集群中单一 Namenode 的结构大大简化了系统的架构。Namenode 是所有
HDFS 元数据的仲裁者和管理者,这样,用户数据永远不会流过 Namenode。
文件系统的名字空间 (namespace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后
将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统
类似:用户可以创建、删除、移动或重命名文件。当前,HDFS 不支持用户磁盘
配额和访问权限控制,也不支持硬链接和软链接。但是 HDFS 架构并不妨碍实现
这些特性。
剩余10页未读,继续阅读
2017-08-06 上传
2013-10-18 上传
2021-01-30 上传
2021-01-20 上传
2022-08-03 上传

maliang1225
- 粉丝: 56
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
