Lucene深度解析:索引原理与代码剖析
需积分: 19 194 浏览量
更新于2024-07-30
收藏 4.73MB PDF 举报
"Lucene原理与代码分析完整版,涵盖了Lucene的索引原理、组织架构、入门知识,适合初学者及有经验者深入学习。作者为觉先,提供了多个博客链接和邮箱联系方式,便于读者了解更多内容。"
在深入探讨Lucene之前,我们需要理解全文检索的基本原理。全文检索是一种在大量文本数据中快速查找与特定查询语句相关的信息的技术。Lucene,作为Apache软件基金会的开源全文搜索引擎库,是实现这一技术的重要工具。
**全文检索的基本原理:**
1. **总论**:全文检索系统通常包括三个主要部分:索引器(Indexer)、查询处理器(Query Processor)和搜索器(Searcher)。索引器负责从原始文档中提取信息并构建索引,查询处理器处理用户输入的查询,而搜索器则使用索引来找到相关文档。
2. **索引里面究竟存些什么**:索引主要包括词典(Dictionary)和文档倒排索引(Posting List)。词典存储所有唯一词项(Term),而文档倒排索引记录了每个词项在哪些文档中出现及其位置。
3. **如何创建索引**:
- **原文档(Document)**:索引的基础是包含文本信息的文档。
- **分次组件(Tokenizer)**:将文档内容分解成独立的词元(Token)。
- **语言处理组件(LinguisticProcessor)**:对词元进行进一步处理,如去除停用词,词形还原等。
- **索引组件(Indexer)**:将处理后的词元转化为索引结构,包括创建词典和文档倒排列表。
4. **如何对索引进行搜索**:
- **用户输入查询**:用户提交查询字符串。
- **词法分析、语法分析和语言处理**:对查询进行预处理,识别关键词,构造查询解析树,并考虑语言特性。
- **搜索索引**:使用索引找到包含查询词的文档。
- **结果排序**:基于查询词在文档中的出现频率、位置等因素计算相关性,使用如TF-IDF的向量空间模型进行排序。
**Lucene的总体架构**:Lucene的核心组件包括Analyzer(分析器)、IndexWriter(索引写入器)、Directory(目录,用于存储索引)、IndexReader(索引读取器)和IndexSearcher(索引搜索器)。Analyzer负责文本预处理,IndexWriter构建索引,Directory管理磁盘上的索引,IndexReader用于读取索引,而IndexSearcher执行搜索操作。
**代码分析篇**:这部分内容可能涉及Lucene的源码解读,包括索引文件的内部结构、编码方式如前缀后缀规则、差值规则和或然跟随规则,以及如何通过编程接口使用Lucene进行索引和搜索的实例分析。
通过以上分析,我们可以看出Lucene是一个强大且灵活的全文检索工具,它的索引机制和搜索算法使得在海量数据中高效查找信息成为可能。对于想要深入理解或使用Lucene的人来说,理解这些原理和代码分析是非常重要的。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
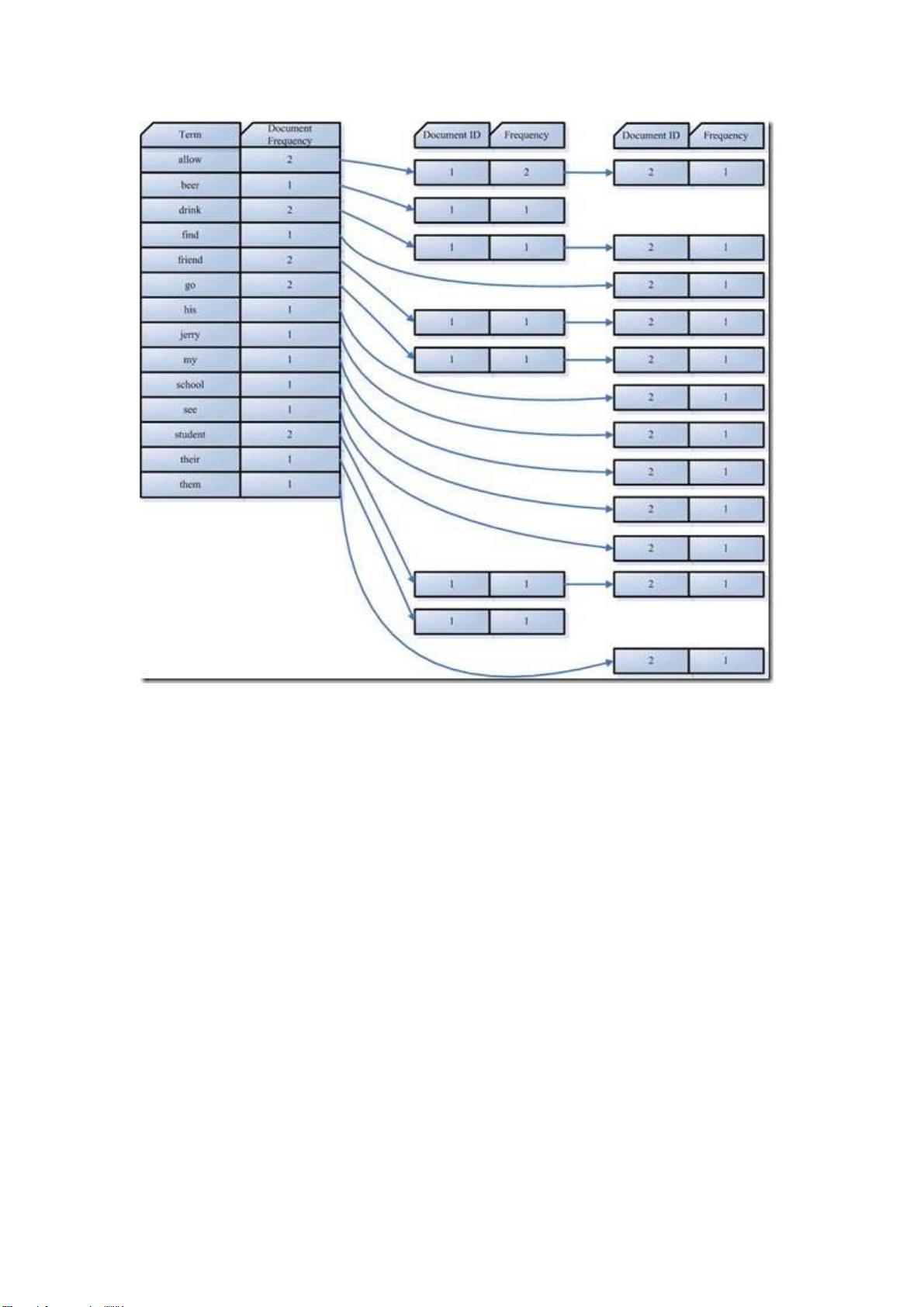
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2


剩余526页未读,继续阅读
145 浏览量
点击了解资源详情
点击了解资源详情
2013-08-14 上传
2017-09-23 上传
124 浏览量
2012-11-04 上传
2022-08-04 上传

chudu
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- HTC G22刷机教程:掌握底包刷入及第三方ROM安装
- JAVA天天动听1.4版:证书加持的移动音乐播放器
- 掌握Swift开发:实现Keynote魔术移动动画效果
- VB+ACCESS音像管理系统源代码及系统操作教程
- Android Nanodegree项目6:Sunshine-Wear应用开发
- Gson解析json与网络图片加载实践教程
- 虚拟机清理神器vmclean软件:解决安装失败难题
- React打造MyHome-Web:公寓管理Web应用
- LVD 2006/95/EC指令及其应用指南解析
- PHP+MYSQL技术构建的完整门户网站源码
- 轻松编程:12864液晶取模工具使用指南
- 南邮离散数学实验源码分享与学习心得
- qq空间触屏版网站模板:跨平台技术项目源码大全
- Twitter-Contest-Bot:自动化参加推文竞赛的Java机器人
- 快速上手SpringBoot后端开发环境搭建指南
- C#项目中生成Font Awesome Unicode的代码仓库
