深度优先与广度优先搜索详解:DFS vs BFS
版权申诉
25 浏览量
更新于2024-09-01
收藏 730KB DOCX 举报
度优先遍历(DFS,Depth First Search)是一种用于遍历或搜索树或图的算法。在树或图中,DFS的策略是尽可能深地探索树的分支,直到达到叶子节点,然后回溯到最近的未访问节点,继续探索。DFS在解决实际问题时,常用于判断是否存在路径、找到所有路径或寻找最小生成树等。
DFS的核心思想可以分为以下步骤:
1. 从根节点(或任意未访问节点)开始。
2. 访问当前节点,并标记为已访问。
3. 对当前节点的所有未访问邻居节点进行DFS。
4. 回溯到上一节点,选择下一个未访问的邻居节点,重复步骤2和3,直至所有节点都被访问。
在图的DFS中,通常有两种实现方式:递归和栈。递归方法是自然的DFS实现,直接调用自身来处理邻居节点。栈方法则需要自己管理递归调用栈,将待访问的节点压入栈中,每次从栈顶取出节点进行访问。
广度优先遍历(BFS,Breath First Search)与DFS不同,它首先访问离起点近的节点,然后再访问离起点更远的节点。BFS采用队列数据结构,按层次顺序遍历节点。其基本步骤如下:
1. 将起始节点放入队列,并标记为已访问。
2. 当队列非空时,取出队首节点,访问该节点。
3. 将该节点的所有未访问邻居节点加入队列,并标记为已访问。
4. 重复步骤2和3,直至队列为空。
DFS和BFS各有优缺点。DFS通常适用于寻找最深的路径、解决迷宫问题或解决一些递归问题,其内存消耗较小,但可能需要较长的运行时间。BFS适用于寻找最短路径、解决图的层次问题,如二叉树的层次遍历,其运行时间相对较短,但可能需要较大的内存。
搜索算法的解题流程通常包括以下步骤:
1. 问题抽象:将实际问题转化为搜索树模型。
2. 设定初始状态:确定搜索的起点。
3. 定义目标状态:明确搜索的目标。
4. 选择搜索策略:根据问题特性选择DFS或BFS等搜索算法。
5. 实现扩展规则:定义如何从一个节点生成其子节点。
6. 实施剪枝策略:利用问题约束条件减少无效搜索。
7. 检查目标状态:判断是否达到目标状态,若是则返回解决方案,否则继续搜索。
在搜索中,常用术语包括节点(代表问题的状态)、边(表示状态之间的转移)、初始节点(搜索开始的地方)、目标节点(搜索的目标)、路径(从初始节点到目标节点的节点序列)以及解空间(所有可能状态的集合)。
搜索算法的优化通常涉及剪枝、记忆化搜索、启发式搜索等技术。剪枝通过提前终止某些分支的搜索来减少不必要的计算。记忆化搜索(如动态规划)存储子问题的解,避免重复计算。启发式搜索则利用估计函数评估节点的潜在价值,以指导搜索方向。
最后,通过习题演练,可以加深对DFS和BFS的理解,实践是检验理论的最好方式。通过解决实际问题,你可以更好地掌握这两种搜索算法的运用,并提高解决问题的能力。
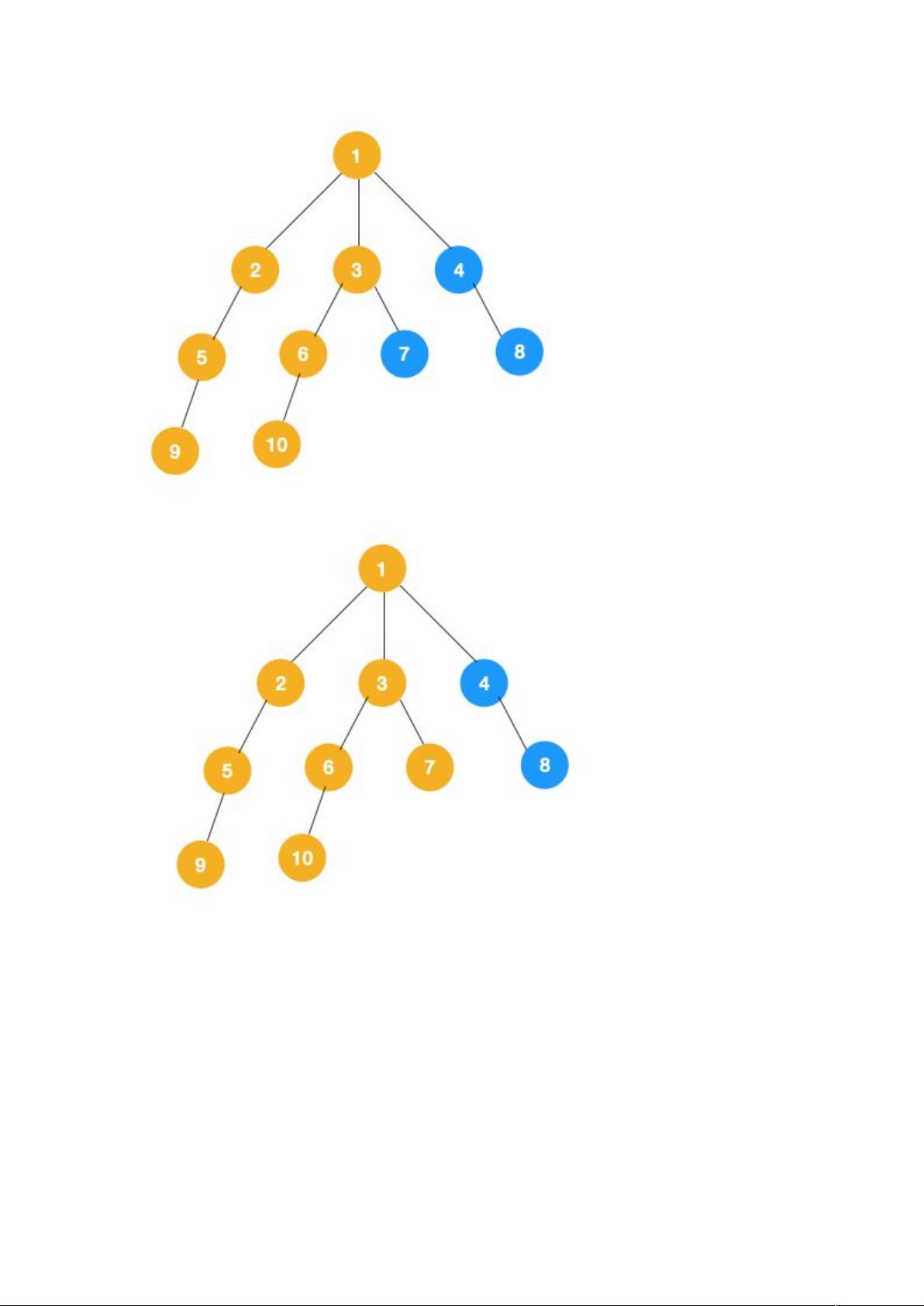
3、同理从 10 开始往上回溯到 6, 6 没有除 10 以外的子节点,再往上回溯,发现 3 有除 6 以外的子点 7,所以此时会遍历 7。
4、从 7 往上回溯到 3, 1,发现 1 还有节点 4 未遍历,所以此时沿着 4, 8 进行遍历,这样就遍历完成了。
完整的节点的遍历顺序如下(节点上的的蓝色数字代表):
剩余13页未读,继续阅读
2022-05-02 上传
2021-08-04 上传
2022-05-31 上传
2021-11-25 上传
2022-06-10 上传
2021-09-14 上传
2022-12-17 上传
2024-05-01 上传
2021-09-14 上传

10247D
- 粉丝: 959
- 资源: 111
 我的内容管理
展开
我的内容管理
展开







最新资源
- Haskell编写的C-Minus编译器针对TM架构实现
- 水电模拟工具HydroElectric开发使用Matlab
- Vue与antd结合的后台管理系统分模块打包技术解析
- 微信小游戏开发新框架:SFramework_LayaAir
- AFO算法与GA/PSO在多式联运路径优化中的应用研究
- MapleLeaflet:Ruby中构建Leaflet.js地图的简易工具
- FontForge安装包下载指南
- 个人博客系统开发:设计、安全与管理功能解析
- SmartWiki-AmazeUI风格:自定义Markdown Wiki系统
- USB虚拟串口驱动助力刻字机高效运行
- 加拿大早期种子投资通用条款清单详解
- SSM与Layui结合的汽车租赁系统
- 探索混沌与精英引导结合的鲸鱼优化算法
- Scala教程详解:代码实例与实践操作指南
- Rails 4.0+ 资产管道集成 Handlebars.js 实例解析
- Python实现Spark计算矩阵向量的余弦相似度
