"腾讯深度学习流水线优化:磁盘、CPU、GPU资源利用与耗时大幅减少"
需积分: 0 155 浏览量
更新于2024-01-18
收藏 2.43MB DOCX 举报
腾讯在深度学习领域的平台化和应用实践中,引入了数据并行和模型并行的概念。在深度学习的训练过程中,涉及到从磁盘读取训练数据、训练数据预处理、CNN训练等环节,这些环节都消耗大量的磁盘、CPU和GPU资源,并且耗时较长。为了提高训练效率,腾讯引入了流水线的概念。
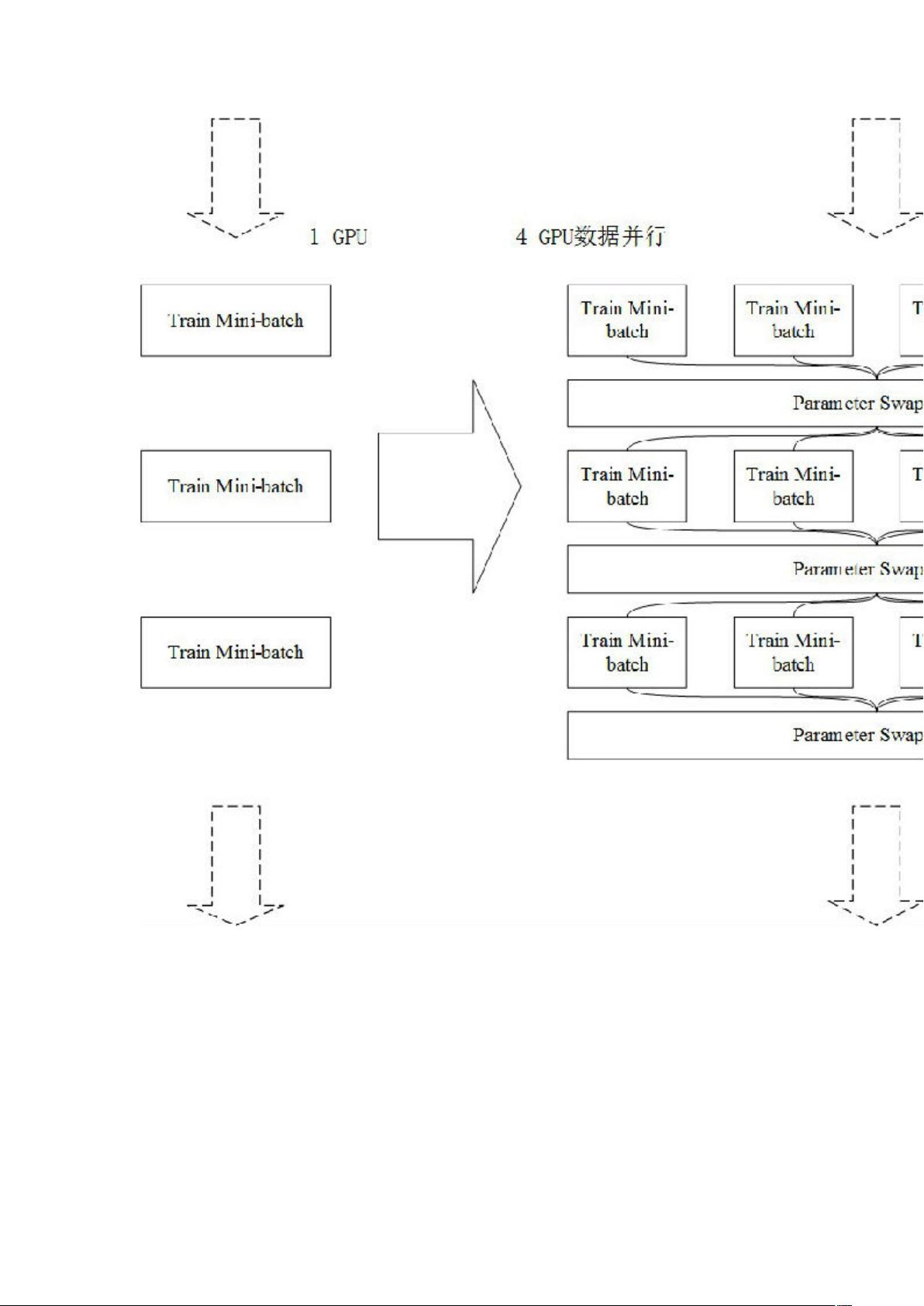
首先,引入数据并行和模型并行可以将训练数据分成多个部分并行处理,从而充分利用GPU资源并加快训练速度。数据并行是指将数据划分成几个块,分配到不同的GPU上进行训练,在训练过程中,各个GPU之间可以互相通信,共享模型参数,并对模型进行更新。模型并行是指将一个模型划分成几个部分,分配到不同的GPU上进行训练,每个GPU只负责模型的一部分,然后将所有GPU的结果合并,得到最终的训练结果。
其次,在训练过程中,磁盘、CPU和GPU资源的占用情况需要合理分配,以提高训练效率。由于磁盘读取速度较慢,会成为训练过程的瓶颈,因此可以采用数据预加载的方式,将部分数据提前读入内存中,以减少磁盘IO的时间开销。此外,CPU负责数据预处理等计算密集型任务,可以通过并行计算和优化算法来提高处理速度。而GPU则是深度学习的关键,通过并行计算能力,可以大大加速神经网络的训练过程。
最后,引入流水线的概念可以进一步提高训练效率。流水线可以将训练过程中的不同环节串联起来,形成一个连续不断的流动,以减少任务间的等待时间。例如,在数据并行的训练中,可以将数据的读取和预处理、模型的训练以及参数的更新等环节连接起来,以实现流水线式的训练。这样做的好处是可以将各个环节的计算任务重叠进行,提高了计算资源的利用率,从而进一步加速训练过程。
在腾讯的深度学习平台Marina中,这些技术和概念得到了广泛的应用。通过引入数据并行和模型并行,结合流水线的设计,有效地利用了磁盘、CPU和GPU资源,并大大加快了深度学习的训练速度。这不仅提高了腾讯在深度学习领域的应用效果,也为其他企业和研究机构提供了有益的借鉴和参考。在未来,随着技术的不断发展和深度学习的广泛应用,腾讯在深度学习领域的平台化和应用实践将继续取得更大的突破和成就。

现有的加速方法
Mariana 技术团队在语音识别研究中率先引入了 GPU 技术用于 DNN 训练,获得了良好的
成果,相比单台 CPU 服务器达到千倍加速比。随着训练数据集扩充、模型复杂度增加,即
使采用 GPU 加速,在实验过程中也存在着严重的性能不足,往往需要数周时间才能达到模
型的收敛,不能满足对于训练大规模网络、开展更多试验的需求。目前服务器上安装多个
GPU 卡已经非常普遍,在通用计算领域使用多 GPU 并行加速技术[3]扩展计算密集型应用
程序的并行性、提高程序性能也是越来越热门的发展方向。
由于语音业务中 DNN 模型采用多层全连接的网络结构,Mariana 技术团队在单机多 GPU
模型并行的实践中发现拆分其模型存在较大的额外开销,无论采用普通模型拆分还是流式控
制,扩展性有限:相比 GPU 的计算能力,如果模型参数量不能匹配,模型并行不能有效地
利用多个高计算能力的GPU 卡,表现为使用2GPU 时已有较好的性能提升,但使用更多GPU
却无法取得更好效果。
Mariana 技术团队考虑到上述问题,在 Mariana 的 DNN 多 GPU 并行训练框架中,选择了
数据并行的技术路线,完成了升级版的单机多 GPU 数据并行版本。
本文描述了多 GPU 加速深度神经网络训练系统的数据并行实现方法及其性能优化,依托多
GPU 的强大协同并行计算能力,结合数据并行特点,实现快速高效的深度神经网络训练。


剩余80页未读,继续阅读
2022-08-03 上传
2018-07-10 上传
2018-09-05 上传
2019-07-17 上传
2022-10-18 上传
2023-09-12 上传
2019-02-15 上传

以墨健康道
- 粉丝: 33
- 资源: 307
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
