大数据量下数据库优化:分库分表策略详解
下载需积分: 0 | PDF格式 | 598KB |
更新于2024-08-05
| 86 浏览量 | 举报
在IT行业中,随着业务的不断增长,数据库优化成为至关重要的环节。当你遇到写入数据量急剧增加、单表数据量庞大、查询性能下降、磁盘空间压力增大以及高并发写入请求等问题时,数据库优化方案中的“分库分表”策略显得尤为重要。本篇文章将深入探讨在数据库优化过程中如何实施分库分表,以应对系统发展带来的挑战。
首先,当数据量达到千万甚至亿级别,传统的单表存储无法满足性能需求。即使使用索引,索引空间也会随着数据量增加而占用更多磁盘空间,这可能导致频繁的磁盘I/O,降低查询效率。提升查询性能的关键在于合理设计表结构和索引策略,可能需要采用分区或分片的方式,将数据分散到多个独立的物理存储区域,减少对单一索引的依赖。
其次,随着数据量的增大,数据库备份和恢复时间延长,影响系统的可用性和稳定性。为支持大数据量,可以考虑使用分布式存储和备份策略,比如分布式数据库或者实时的数据冗余,确保在主库故障时,备份库或从库能够快速接管服务,减少中断时间。
再者,为了实现不同模块数据的隔离,避免单点故障影响全局,分库分表需要按照业务逻辑进行数据划分,例如用户数据和用户关系数据分开存储在不同的数据库中。这样即使一个模块的数据库出现问题,其他模块仍能正常运行,提高系统的容错性和可靠性。
最后,针对数据库写入性能较弱的问题,特别是高并发写入场景,可以通过水平扩展来应对。通过增加数据库服务器的数量,将写入请求分散到多个服务器,每个服务器负责一部分数据的写入,从而降低单台服务器的压力。此外,还可以考虑使用更高效的数据库引擎、优化事务处理策略等手段,提高写入性能。
总结来说,分库分表是数据库优化的一种常见策略,旨在通过数据分布和资源调度,解决高并发、大数据量带来的性能和可用性问题。理解并熟练应用这一技术,有助于企业级应用在快速增长的业务环境中保持稳定和高效。在实际操作中,应根据具体业务场景灵活选择和调整分库分表的方法,以达到最佳的数据库优化效果。
09-数据库优化⽅案(⼆):写⼊数据量增加时,如何实现分库分表?09-数据库优化⽅案(⼆):写⼊数据量增加时,如何实现分库分表?
你好,我是唐扬。
前⼀节课,我们学习了在⾼并发下数据库的⼀种优化⽅案:读写分离,它就是依靠主从复制的技术使得数据
库实现了数据复制为多份,增强了抵抗⼤量并发读请求的能⼒,提升了数据库的查询性能的同时,也提升了
数据的安全性,当某⼀个数据库节点,⽆论是主库还是从库发⽣故障时,我们还有其他的节点中存储着全量
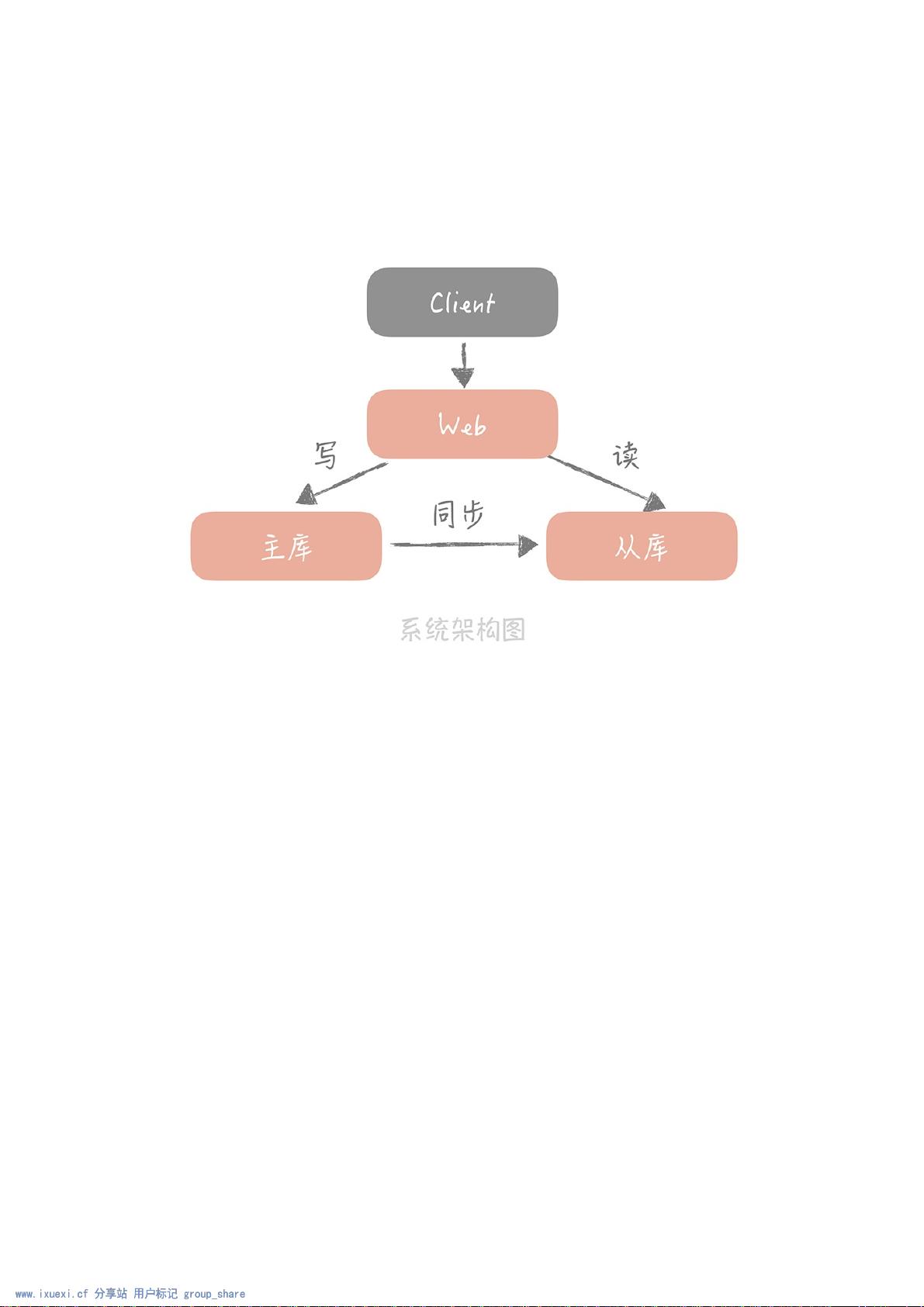
的数据,保证数据不会丢失。此时,你的电商系统的架构图变成了下⾯这样:
这时,公司CEO突然传来⼀个好消息,运营推⼴持续带来了流量,你所设计的电商系统的订单量突破了五千
万,订单数据都是单表存储的,你的压⼒倍增,因为⽆论是数据库的查询还是写⼊性能都在下降,数据库的
磁盘空间也在报警。所以,你主动分析现阶段⾃⼰需要考虑的问题,并寻求⾼效的解决⽅式,以便系统能正
常运转下去。你考虑的问题主要有以下⼏点:
1.系统正在持续不断地的发展,注册的⽤⼾越来越多,产⽣的订单越来越多,数据库中存储的数据也越来越
多,单个表的数据量超过了千万甚⾄到了亿级别。这时即使你使⽤了索引,索引占⽤的空间也随着数据量的
增⻓⽽增⼤,数据库就⽆法缓存全量的索引信息,那么就需要从磁盘上读取索引数据,就会影响到查询的性
能了。那么这时你要如何提升查询性能呢?那么这时你要如何提升查询性能呢?
2.数据量的增加也占据了磁盘的空间,数据库在备份和恢复的时间变⻓,你如何让数据库系统⽀持如此⼤的你如何让数据库系统⽀持如此⼤的
数据量呢?数据量呢?
3.不同模块的数据,⽐如⽤⼾数据和⽤⼾关系数据,全都存储在⼀个主库中,⼀旦主库发⽣故障,所有的模
块⼉都会受到影响,那么如何做到不同模块的故障隔离呢?那么如何做到不同模块的故障隔离呢?
4.你已经知道了,在4核8G的云服务器上对MySQL5.7做Benchmark,⼤概可以⽀撑500TPS和10000QPS,
你可以看到数据库对于写⼊性能要弱于数据查询的能⼒,那么随着系统写⼊请求量的增⻓,数据库系统如何数据库系统如何
来处理更⾼的并发写⼊请求呢?来处理更⾼的并发写⼊请求呢?
这些问题你可以归纳成,数据库的写⼊请求量⼤造成的性能和可⽤性⽅⾯的问题,要解决这些问题,你所采
取的措施就是对数据进⾏分⽚,对数据进⾏分⽚,可以很好地分摊数据库的读写压⼒,也可以突破单机的存
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐



独角兽邹教授
- 粉丝: 39
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- java文本比较器.rar
- 传输线:使用Phaser制作的2018年全球Game Jam游戏
- MechaCar_Statistical_Analysis
- OCR文字识别.rar
- matlab代码做游戏-One::scissors::clipboard:精选的超赞列表
- 凝结顺序
- DiscGolf:飞盘高尔夫网站
- vue-phaser-starter:一个游戏入门项目,使用Phaser,Vue,ES6,Webpack
- ZFPlayer:支持任何播放器SDK和控制层的自定义(支持定制任何播放器SDK和控制层)
- GridTreeCtrl.7z
- mysql-5.6.13-winx64.zip
- noteful-server
- cargamos_test
- xcom串口调试助手2.5+2.0..rar
- phaser-3-snake-game:基于Phaser World#85发布的“ Snake Plissken”教程的Phaser 3演示项目
- 三菱FR-A500系列变频器资料.rar
