滴滴出行:从混乱到有序——千亿消息队列升级历程
81 浏览量
更新于2024-08-28
收藏 1.3MB PDF 举报
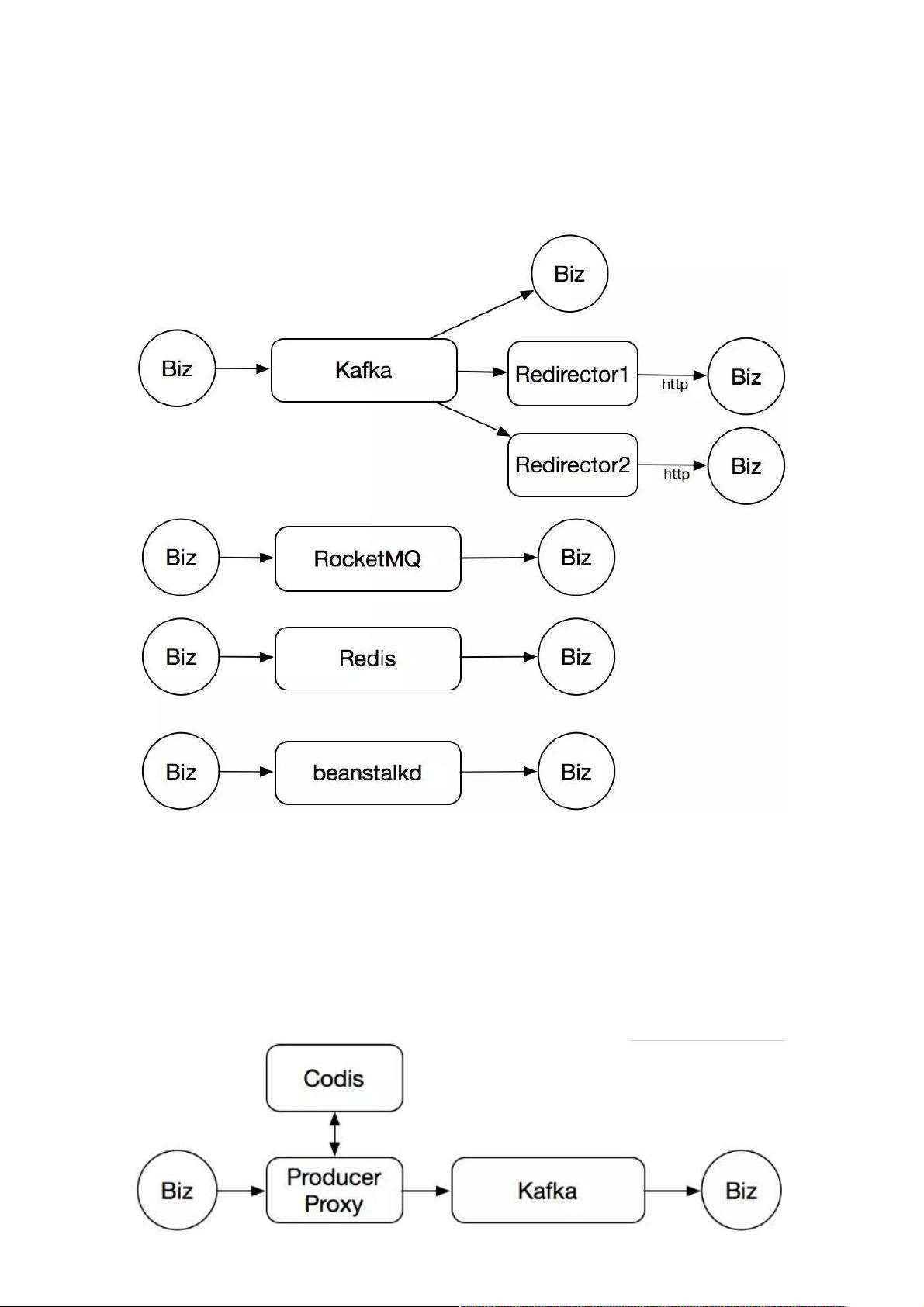
滴滴出行在构建其千亿级消息队列系统的过程中,经历了早期的混乱与挑战。起初,由于公司内部没有专门维护消息队列服务的团队,各种技术栈混杂,包括Kafka、RocketMQ、Redis的list和非主流的beanstalkd。这种混乱导致了资源浪费和维护困难,特别是核心业务使用的Kafka出现了严重的数据写入抖动问题,且由于版本限制(Kafka 0.8.2的bug),机械硬盘的I/O压力过大。
为了解决这些问题,滴滴出行决定自建消息队列服务。首先,他们采取了渐进式迁移策略,引入了代理层和Codis缓存,以解决Kafka的写入失败问题。当Kafka写入失败时,数据会被暂存到Codis中,并在后续尝试写入直到成功。
在选型过程中,经过深思熟虑和多方考量,最终选择了RocketMQ。RocketMQ被选中的理由可能包括其稳定性和高吞吐量,以及对多语言环境的支持和满足特定业务需求的能力。此外,为了提供更好的服务化体验,滴滴出行还设计了统一的平台界面供业务部门申请和使用资源。
演进中的架构变得更加清晰,包含多语言生产客户端、生产代理服务、RocketMQ为核心的消息存储层,以及还在迁移过程中的Kafka和Chronos等其他组件。整个系统朝着标准化、高效和易管理的方向发展,实现了业务的稳定运行和资源的有效利用。
在整个历程中,滴滴出行不仅解决了原有的问题,还在功能迭代、性能优化和服务化等方面取得了显著进步,为大规模消息传递提供了坚实的基础。
滴滴出行千亿级消息队列炼成记!滴滴出行千亿级消息队列炼成记!
滴滴出行的消息技术选型
1.1 历史
初期,公司内部没有专门的团队维护消息队列服务,所以消息队列使用方式较多,主要以Kafka为主,有业务直连的,也有通
过独立的服务转发消息的。另外有一些团队也会用RocketMQ、Redis的list,甚至会用比较非主流的beanstalkkd。导致的结果
就是,比较混乱,无法维护,资源使用也很浪费。
1.2 为什么弃用Kafka
一个核心业务在使用Kafka的时候,出现了集群数据写入抖动非常严重的情况,经常会有数据写失败。
主要有两点原因:
随着业务增长,Topic的数据增多,集群负载增大,性能下降;
我们用的是Kafka0.8.2那个版本,有个bug,会导致副本重新复制,复制的时候有大量的读,我们存储盘用的是机械盘,导致
磁盘IO过大,影响写入。
所以我们决定做自己的消息队列服务。
下载后可阅读完整内容,剩余8页未读,立即下载
2016-07-15 上传
2024-09-29 上传
2022-03-04 上传
2021-10-19 上传
2018-02-14 上传
2020-11-25 上传
点击了解资源详情
点击了解资源详情

weixin_38744778
- 粉丝: 7
- 资源: 917
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
