Python实现自组织映射SOM算法详解
版权申诉
"本文介绍了如何使用Python实现自组织映射(SOM)算法,这是一种无监督的聚类方法,常用于数据降维和可视化。"
在机器学习领域,自组织映射(Self-Organizing Map, SOM)是一种由芬兰科学家Teuvo Kohonen提出的神经网络模型。SOM算法的主要目标是将高维度数据映射到一个低维度的网格结构上,同时保持数据原有的拓扑关系。这种算法特别适用于非线性数据聚类和数据的可视化。
在Python中实现SOM,首先需要理解其基本步骤:
1. **初始化**:权重向量通常用较小的随机值初始化,同时对输入样本向量和权重进行归一化,确保它们在相同的尺度上。归一化可以使用欧几里得范数(Euclidean norm)来实现。
2. **竞争阶段**:每个输入样本都会与输出层的所有神经元比较。计算样本向量与权重向量的点积或欧几里得距离,找出距离最近的神经元,即最佳匹配单元(BMU, Best-Matching Unit)。
3. **权值更新**:一旦确定了BMU,它的权重以及其拓扑邻域内的神经元权重会被更新。更新公式通常包含一个学习率η和一个依赖于时间和神经元距离的衰减因子。学习率η随着时间递减,以逐渐减小权重的调整幅度,直到最终算法收敛。
4. **邻域定义**:邻域通常定义为一个二维网格,随着训练的进行,邻域范围会逐渐缩小,这有助于逐渐减小权重的更新范围。
5. **收敛条件**:算法继续运行直到满足某个停止条件,如学习率下降到一个极小值ηmin,或者达到预设的最大迭代次数。
在给出的Python代码中,`SOM`类的构造函数接受输入样本`X`、输出层神经元数量`output`、迭代次数`iteration`和批量大小`batch_size`。类内部可能会实现上述步骤,并在每次迭代时更新权重和学习率。代码可能还包含了绘制学习率和邻域大小变化的图像,以便于理解算法的动态过程。
实际应用中,SOM算法可用于多种场景,如数据可视化(通过二维或三维网格展示高维数据)、异常检测(通过识别与网格中其他区域明显不同的区域)、特征选择(通过分析哪些神经元对输入数据敏感)等。在处理非结构化数据,如图像、文本或声音数据时,SOM能提供有用的洞察力。
Python实现SOM算法需要对神经网络的基本概念有深入理解,同时掌握如何使用Python的科学计算库(如NumPy)进行数值计算和数据处理。通过这个实现,用户可以根据自己的需求调整参数,适应不同复杂度的数据集。
python实现实现SOM算法算法
主要为大家详细介绍了python实现SOM算法,聚类算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一
下
算法简介算法简介
SOM网络是一种竞争学习型的无监督神经网络,将高维空间中相似的样本点映射到网络输出层中的邻近神经元。
训练过程简述:在接收到训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成
为竞争获胜者,称为最佳匹配单元。然后最佳匹配单元及其邻近的神经元的权向量将被调整,以使得这些权向量与当前输入样
本的距离缩小。这个过程不断迭代,直至收敛。
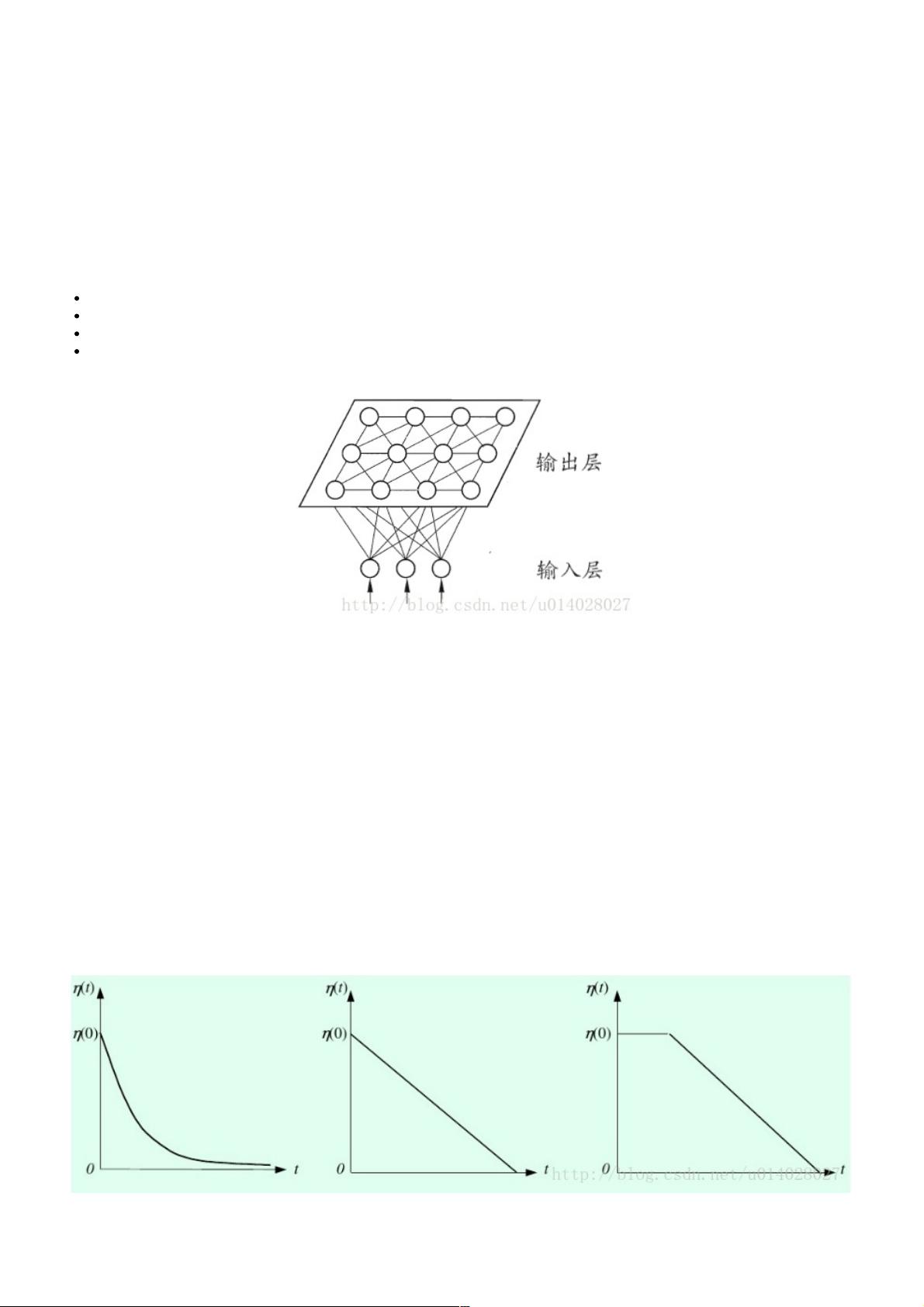
网络结构:输入层和输出层(或竞争层),如下图所示。
输入层:假设一个输入样本为X=[x1,x2,x3,…,xn],是一个n维向量,则输入层神经元个数为n个。
输出层(竞争层):通常输出层的神经元以矩阵方式排列在二维空间中,每个神经元都有一个权值向量。
假设输出层有m个神经元,则有m个权值向量,Wi = [wi1,wi2,....,win], 1<=i<=m。
算法流程:
1. 初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X' = X/||X||
ω'i= ωi/||ωi||, 1<=i<=m
||X||和||ωi||分别为输入的样本向量和权值向量的欧几里得范数。
2.将样本输入网络:样本与权值向量做点积,点积值最大的输出神经元赢得竞争,
(或者计算样本与权值向量的欧几里得距离,距离最小的神经元赢得竞争)记为获胜神经元。
3.更新权值:对获胜的神经元拓扑邻域内的神经元进行更新,并对学习后的权值重新归一化。
ω(t+1)= ω(t)+ η(t,n) * (x-ω(t))
η(t,n):η为学习率是关于训练时间t和与获胜神经元的拓扑距离n的函数。
η(t,n)=η(t)e^(-n)
η(t)的几种函数图像如下图所示。
4.更新学习速率η及拓扑邻域N,N随时间增大距离变小,如下图所示。
5.判断是否收敛。如果学习率η<=ηmin或达到预设的迭代次数,结束算法。
下载后可阅读完整内容,剩余3页未读,立即下载
2020-12-16 上传
2021-05-06 上传
2021-02-12 上传
2023-04-26 上传
2023-04-04 上传
2023-03-25 上传
2023-05-31 上传
2023-08-25 上传
2023-05-13 上传

weixin_38584148
- 粉丝: 10
- 资源: 1000
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
