ARM的MLProcessor:AI芯片的‘just enough’策略剖析
版权申诉
66 浏览量
更新于2024-08-28
收藏 773KB DOCX 举报
"ARM的MLProcessor在AI芯片领域的应用与探讨"
在AI芯片的激烈竞争中,ARM的MLProcessor因其“just enough”的设计理念引发了业界的关注。MLProcessor是ARM针对机器学习任务设计的一种专用处理器架构,旨在提供高效能和能效比。在深入分析ARM的MLProcessor之前,我们需要理解当前AI芯片市场的背景。
AI芯片市场正在迅速发展,各大公司如NVIDIA、Intel、Google等都在推出自家的定制化芯片以满足深度学习的需求。这些芯片通常拥有高度的计算能力,能够快速处理大量的神经网络运算。然而,对于许多边缘设备和物联网(IoT)应用来说,高能耗和复杂的硬件可能并不适用。这时,ARM提出的“just enough”理念显得尤为重要,它旨在提供适合这些场景的适度计算性能,同时保持低功耗。
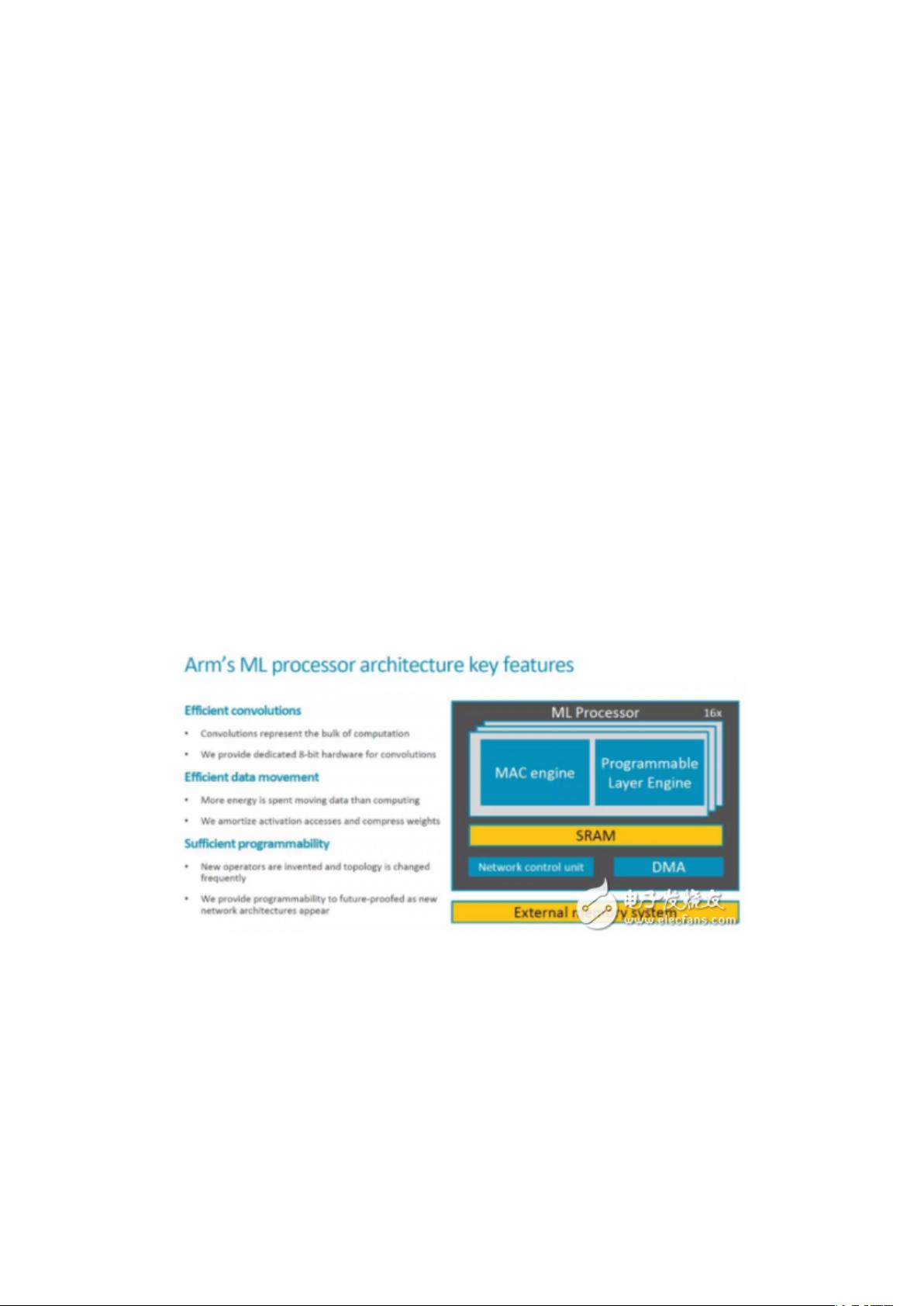
ARM的MLProcessor在架构上具有以下特点:
1. **硬件加速器设计**:MLProcessor拥有本地静态随机存取内存(SRAM),通过ACE-Lite接口与外部通信,确保高效的数据交换。这一设计减少了对外部存储器的依赖,降低了数据传输的延迟和功耗。
2. **数据与控制流管理**:MLProcessor采用独立的控制单元和同步单元,配合直接存储器访问(DMA)引擎,确保数据的流畅处理。数据流由绿色箭头表示,控制流则用红色箭头表示,展示了其内部高效的工作流程。
3. **卷积运算与处理**:MLProcessor的核心是MACConvolutionEngine(MCE),负责执行卷积运算,配合InputFeatureMapRead和WeightRead模块,对输入特征图和权重进行预处理。ProgrammableLayerEngine(PLE)则负责后续的处理,包括激活函数和其他层的操作。
4. **广播接口与并行计算**:Broadcast接口允许特征图数据在多个ComputeEngine(CE)之间广播,实现多CE间的并行运算。这种设计提高了运算效率,尤其是在处理大型卷积层时。
5. **可编程性**:PLE的存在使得MLProcessor具有一定的灵活性,可以根据不同算法需求进行调整,适应多样化的机器学习任务。
尽管ARM的MLProcessor设计理念旨在平衡效能与功耗,但也有其局限性。例如,对于那些需要极高计算密集度或特定硬件加速功能的复杂深度学习模型,MLProcessor可能就显得力不从心。此外,尽管MLProcessor具有一定的可编程性,但相比于通用GPU或FPGA,其灵活性可能稍显不足。
ARM的“just enough”策略在AI芯片领域提供了一种折衷方案,尤其适用于对功耗敏感的边缘计算和物联网设备。然而,随着AI技术的不断发展,如何在性能、功耗和成本之间找到最佳平衡,将是未来芯片设计的一大挑战。ARM的MLProcessor作为这一探索的一部分,将继续在AI芯片大战中扮演重要的角色。
AI 芯片大战后,ARM 的“justenough”是否真是最合适的
选择?
最近,(ARM)进一步公开了 MLProcesor 的一些信息。EE(Ti)
mes 的文章“ArmGivesGli(mps)eof(AI)Core”[1]和 Anand
(Te)ch 的文章
“ARMDetails“ProjectTrillium”MachineLearningProcessorArch
itecture”分别从不同角度进行了介绍,值得我们仔细分析。
ARM 公开它的 MLProcessor 是在今年春节前夕,当时公布的信
息不多,我也简单做了点分析(AI 芯片开年)。
这次 ARM 公开了更多信息,我们一起来看看。首先是关键的
Feature 和一些重要信息,2018 年中会 Release。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-26 上传

ziyoudianzi15
- 粉丝: 0
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
