"Hadoop2.6.0集群安装配置教程_Ubuntu/CentOS详解"
 已收录资源合集
已收录资源合集
需积分: 0 96 浏览量
更新于2024-03-12
收藏 2.7MB PDF 举报
Hadoop是一个分布式计算框架,能够高效处理大规模数据,广泛应用于大数据分析领域。为了搭建一个Hadoop集群,需要进行一系列的安装和配置步骤。本教程将详细介绍如何在Ubuntu或CentOS操作系统上安装和配置Hadoop2.6.0版本的集群环境。
首先,我们需要确保系统环境的准备工作。在安装Hadoop之前,需要安装和配置Java JDK、SSH、以及设置主机名等。接着,我们将下载Hadoop2.6.0的安装包,并解压到指定的目录。在解压后,需要配置Hadoop的环境变量,以便系统能够正确识别Hadoop的命令。
接下来,我们需要修改Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml等。在这些配置文件中,我们将设置Hadoop的一些重要参数,如NameNode和DataNode的地址、HDFS的副本数、以及YARN的资源管理器等。这些参数的设置将影响到集群的性能和稳定性。
在配置文件修改完成后,我们需要格式化HDFS文件系统,并启动Hadoop集群的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager等。通过启动这些组件,Hadoop集群将能够正常工作,并能够处理用户提交的作业。
最后,我们将进行一系列的测试,以确保Hadoop集群的正常运行。通过运行一些示例作业,我们可以验证集群的性能和可用性。同时,我们也可以通过Web页面查看集群的运行情况,包括作业的运行状态、集群资源的使用情况等。
通过本教程的学习和实践,读者将掌握如何在Ubuntu或CentOS上安装和配置Hadoop2.6.0版本的集群环境。这将为他们今后在大数据分析领域的工作中提供一个强大的工具,帮助他们高效处理海量数据,分析出有价值的信息。同时,通过搭建Hadoop集群的过程,读者也可以学习到分布式计算的原理和技术,提升自己在大数据领域的技术水平。
2016/1/8
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS_给力星
http://www.powerxing.com/install-hadoop-cluster/ 6/27
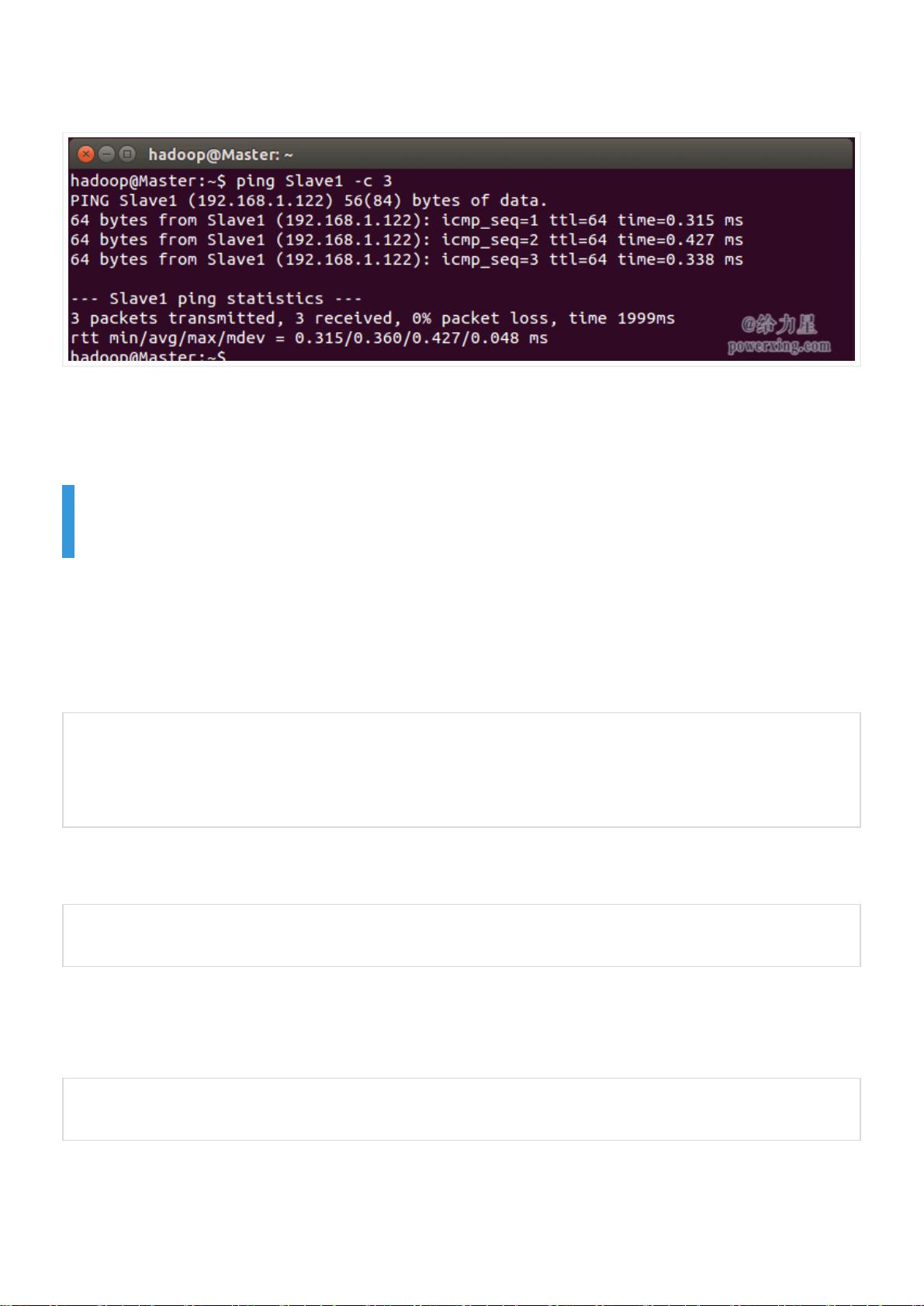
例如我在 Master 节点上
ping Slave1
,ping 通的话会显示 time,显示的结果如下图所
示:
检查是否ping得通
继续下一步配置前,请先完成所有节点的网络配置,修改过主机名的话需重启才能生效。
SSH无密码登陆节点
这个操作是要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上。
首先生成 Master 节点的公匙,在 Master 节点的终端中执行(因为改过主机名,所以还需
要删掉原有的再重新生成一次):
.
$ cd ~/.ssh #
如果没有该目录,先执行一次
ssh localhost
.
$ rm ./id_rsa* #
删除之前生成的公匙(如果有)
.
$ ssh-keygen -t rsa #
一直按回车就可以
让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
.
$ cat ./id_rsa.pub >> ./authorized_keys
完成后可执行
ssh Master
验证一下(可能需要输入 yes,成功后执行
exit
返回原来的
终端)。接着在 Master 节点将上公匙传输到 Slave1 节点:
.
$ scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
剩余26页未读,继续阅读
105 浏览量
2022-03-20 上传
1247 浏览量
2022-03-20 上传
2022-03-20 上传
2022-03-20 上传
2022-08-03 上传

城北伯庸
- 粉丝: 35
- 资源: 315
 我的内容管理
展开
我的内容管理
展开







最新资源
- 适合做手机展示的点击图片放大效果
- opencv-3.4.3.rar
- P-SCAN接口EMC设计标准电路与技术资料-综合文档
- Programacion-III-Proyecto-Final
- sahmieyab:Sahmieyab
- flutter_boost:FlutterBoost是一个Flutter插件,可以以最少的工作量将Flutter混合集成到您现有的本机应用程序中
- WAH壁挂式控制箱产品电子样本.zip
- 图片墙桌面效果
- 通讯录源码java-protobuf-AddressBook:GoogleProtobuf和Java。来源:https://github.co
- laravel-shop:Laravel商店套餐
- 基卡德
- OpenIoTHub::sparkling_heart:一个免费的物联网(IoT)平台和私有云。 [一个免费的物联网和私有云平台,支持内网穿透]
- Ajax-ljq_weixin.zip
- jquery实现图片放大效果
- 精通direct3d图形及动画程序设计源代码下载
- JRoll:平滑滚动移动网络
