多语言适应开源OCR引擎Tesseract:通用化与定制详解
本文档深入探讨了如何对开源光学字符识别(OCR)引擎Tesseract进行适应,以便支持多语言和多脚本的场景。Tesseract是一个由Google维护的强大工具,主要用于识别图像中的文本,最初是为英语设计的。然而,为了使其适用于多种语言和书写系统,作者们对这一引擎进行了针对性的改进。
首先,文章指出,这项工作主要集中在实现通用的多语言操作,目的是尽可能减少对新语言的支持需求,仅需提供足够的训练文本数据即可。这意味着在添加新的语言时,除了提供相应的语言样本,大部分定制化的工作都是围绕物理布局分析(如字符间距、行距等)、字体处理以及语言特定的后处理步骤展开,而非核心的字符识别模块。
在字符分类器方面,尽管对于像简化汉字这样的非拉丁字母系统,确实需要对一些参数进行调整,但整体上,Tesseract的适应性很强,这使得它能够轻松扩展到不同字符集。作者强调,经过改造后的Tesseract在诸如英语、包含欧洲语言元素的混合文本,以及俄语等语言上的测试结果显示出良好的性能。
值得注意的是,这份报告是基于2009年在巴塞罗那举行的国际多语言OCR研讨会论文发表,该论文的在线版本链接为:http://doi.acm.org/10/1145/1577802.1577804。这表明了作者们的研究是在不断发展的OCR技术背景下进行的,旨在保持Tesseract在面对全球化文本识别需求时的竞争力。
这篇文章提供了一个实用的指南,展示了如何利用现有的开源工具进行适应性开发,以便在全球范围内更广泛地应用OCR技术,同时保持系统的灵活性和易用性。这对于那些希望扩展Tesseract功能或开发自己的多语言OCR解决方案的开发者来说,具有很高的参考价值。
©ACM, 2009. This is the authors’ version of the work. It is posted here by permission of ACM for your personal use. Not for
redistribution. The definitive version was published in Proceedings of the International Workshop on Multilingual OCR 2009, Barcelona,
Spain July 25, 2009. http://doi.acm.org/10/1145/1577802.1577804.
Adapting the Tesseract Open Source OCR Engine for
Multilingual OCR
Ray Smith Daria Antonova Dar-Shyang Lee
Google Inc., 1600 Amphitheatre Pkwy, Mountain View, CA 94043, USA.
Abstract
We describe efforts to adapt the Tesseract open source OCR
engine for multiple scripts and languages. Effort has been
concentrated on enabling generic multi-lingual operation such
that negligible customization is required for a new language
beyond providing a corpus of text. Although change was required
to various modules, including physical layout analysis, and
linguistic post-processing, no change was required to the
character classifier beyond changing a few limits. The Tesseract
classifier has adapted easily to Simplified Chinese. Test results on
English, a mixture of European languages, and Russian, taken
from a random sample of books, show a reasonably consistent
word error rate between 3.72% and 5.78%, and Simplified
Chinese has a character error rate of only 3.77%.
Keywords
Tesseract, Multi-Lingual OCR.
1. Introduction
Research interest in Latin-based OCR faded away more than a
decade ago, in favor of Chinese, Japanese, and Korean (CJK)
[1,2], followed more recently by Arabic [3,4], and then Hindi
[5,6]. These languages provide greater challenges specifically to
classifiers, and also to the other components of OCR systems.
Chinese and Japanese share the Han script, which contains
thousands of different character shapes. Korean uses the Hangul
script, which has several thousand more of its own, as well as
using Han characters. The number of characters is one or two
orders of magnitude greater than Latin. Arabic is mostly written
with connected characters, and its characters change shape
according to the position in a word. Hindi combines a small
number of alphabetic letters into thousands of shapes that
represent syllables. As the letters combine, they form ligatures
whose shape only vaguely resembles the original letters. Hindi
then combines the problems of CJK and Arabic, by joining all the
symbols in a word with a line called the shiro-reka.
Research approaches have used language-specific work-arounds
to avoid the problems in some way, since that is simpler than
trying to find a solution that works for all languages. For instance,
the large character sets of Han, Hangul, and Hindi are mostly
made up of a much smaller number of components, known as
radicals in Han, Jamo in Hangul, and letters in Hindi. Since it is
much easier to develop a classifier for a small number of classes,
one approach has been to recognize the radicals [1, 2, 5] and infer
the actual characters from the combination of radicals. This
approach is easier for Hangul than for Han or Hindi, since the
radicals don't change shape much in Hangul characters, whereas
in Han, the radicals often are squashed to fit in the character and
mostly touch other radicals. Hindi takes this a step further by
changing the shape of the consonants when they form a conjunct
consonant ligature. Another example of a more language-specific
work-around for Arabic, where it is difficult to determine the
character boundaries to segment connected components into
characters. A commonly used method is to classify individual
vertical pixel strips, each of which is a partial character, and
combine the classifications with a Hidden Markov Model that
models the character boundaries [3].
Google is committed to making its services available in as many
languages as possible [7], so we are also interested in adapting the
Tesseract Open Source OCR Engine [8, 9] to many languages.
This paper discusses our efforts so far in fully internationalizing
Tesseract, and the surprising ease with which some of it has been
possible. Our approach is use language generic methods, to
minimize the manual effort to cover many languages.
2. Review Of Tesseract For Latin
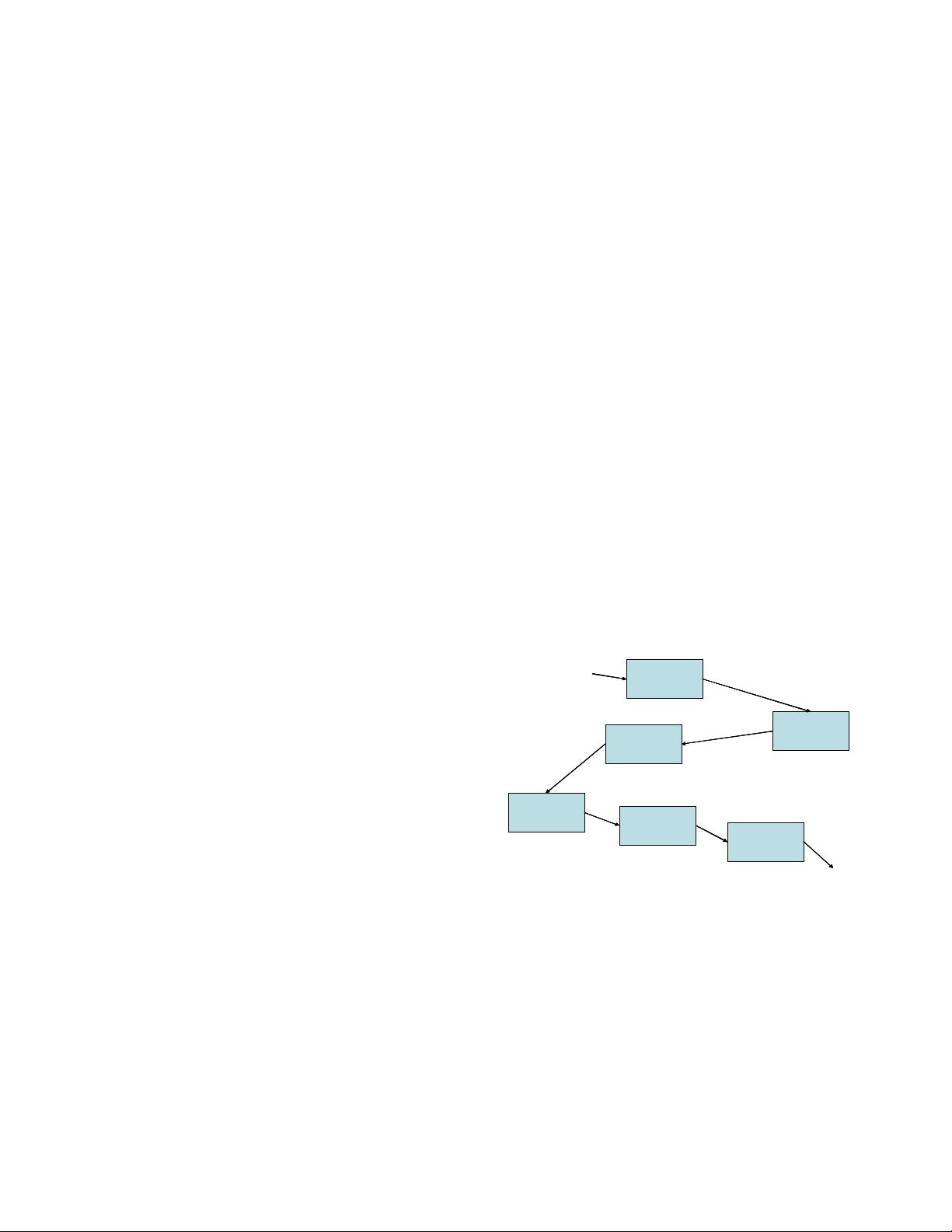
Fig. 1 is a block diagram of the basic components of Tesseract.
The new page layout analysis for Tesseract [10] was designed
from the beginning to be language-independent, but the rest of the
engine was developed for English, without a great deal of thought
as to how it might work for other languages. After noting that the
commercial engines at the time were strictly for black-on-white
text, one of the original design goals of Tesseract was that it
should recognize white-on-black (inverse video) text as easily as
black-on-white. This led the design (fortuitously as it turned out)
in the direction of connected component (CC) analysis and
operating on outlines of the components. The first step after CC
Find Text
Lines and
Words
Recognize
Word
Pass 1
Fuzzy Space &
x-height
Fix-up
Recognize
Word
Pass 2
Page Layout
Analysis
Blob Finding
Input: Binary Image
Component Outlines
In Text Regions
Character
Outlines
In Text Regions
Character
Outlines
Organized
Into Words
Output: Text
Find Text
Lines and
Words
Recognize
Word
Pass 1
Fuzzy Space &
x-height
Fix-up
Recognize
Word
Pass 2
Page Layout
Analysis
Blob Finding
Input: Binary Image
Component Outlines
In Text Regions
Character
Outlines
In Text Regions
Character
Outlines
Organized
Into Words
Output: Text
Figure 1. Top-level block diagram of Tesseract.
下载后可阅读完整内容,剩余7页未读,立即下载
2014-03-17 上传
2021-06-02 上传
2014-06-10 上传
2021-05-11 上传
2024-09-16 上传
2024-06-18 上传
2017-06-24 上传

yoyoshuang2013
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
