Hadoop与Spark:存储与处理对比分析
需积分: 0 52 浏览量
更新于2024-08-05
收藏 870KB PDF 举报
Spark技术与Hadoop的对比主要围绕大数据处理的效率、易用性和扩展性展开。Hadoop最初由Apache开发,主要用于解决大规模数据的可靠存储(HDFS)和并行计算(MapReduce)。HDFS设计用于在廉价硬件上提供高容错性的文件系统,通过复制数据块实现数据的冗余备份,确保即使部分节点故障也能保持服务连续性。MapReduce则提供了一种编程模型,让用户能够将复杂的计算任务分解成一系列Mapper和Reducer操作,这些操作在分布式环境中并行执行,从而大幅度提升处理速度。
然而,Hadoop的局限性在于其编程抽象层次较低,程序员需要编写较多底层细节代码,这使得它对于初学者来说学习曲线较陡峭。此外,MapReduce在处理迭代计算、实时分析和内存密集型任务时性能较差,因为它的设计主要关注一次性的批处理作业。
相比之下,Spark是由LinkedIn开源的一种新型大数据处理框架,旨在解决Hadoop的这些痛点。Spark引入了内存计算的概念,它可以将中间结果缓存到内存中,显著减少了磁盘I/O,提高了处理速度。Spark支持多种计算模式,包括批处理(Batch)、交互式查询(SQL)和流处理(Stream),这使得它在实时分析和迭代计算方面具有优势。
Spark的API更加高级,提供了更简洁的接口,比如DataFrame和RDD(弹性分布式数据集),使得数据处理更加直观和易于使用。此外,Spark还支持机器学习库MLlib,使得在大数据集上进行复杂的机器学习任务变得更加便捷。
总结来说,Spark是对Hadoop的补充和升级,它通过优化内存管理和计算模型,提供更高的性能和更友好的用户界面。然而,选择Spark还是Hadoop取决于具体的应用场景和需求,Hadoop适合于长期稳定的大规模批处理任务,而Spark则更适合于实时分析、迭代计算和需要高效内存处理的任务。
12/23/2019 (3 封私信 / 4 条消息) 与 Hadoop 对比,如何看待 Spark 技术? - 知乎
https://www.zhihu.com/question/26568496 3/12
(图片来源:Real World Hadoop)
因此,在Hadoop推出之后,出现了很多相关的技术对其中的局限进行改进,如Pig,Cascading,
JAQL,OOzie,Tez,Spark等。
Apache Pig
Apache Pig也是Hadoop框架中的一部分,Pig提供类SQL语言(Pig Latin)通过MapReduce来处理大
规模半结构化数据。而Pig Latin是更高级的过程语言,通过将MapReduce中的设计模式抽象为操作,
如Filter,GroupBy,Join,OrderBy,由这些操作组成有向无环图(DAG)。例如如下程序:
visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(visits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
描述了数据处理的整个过程。
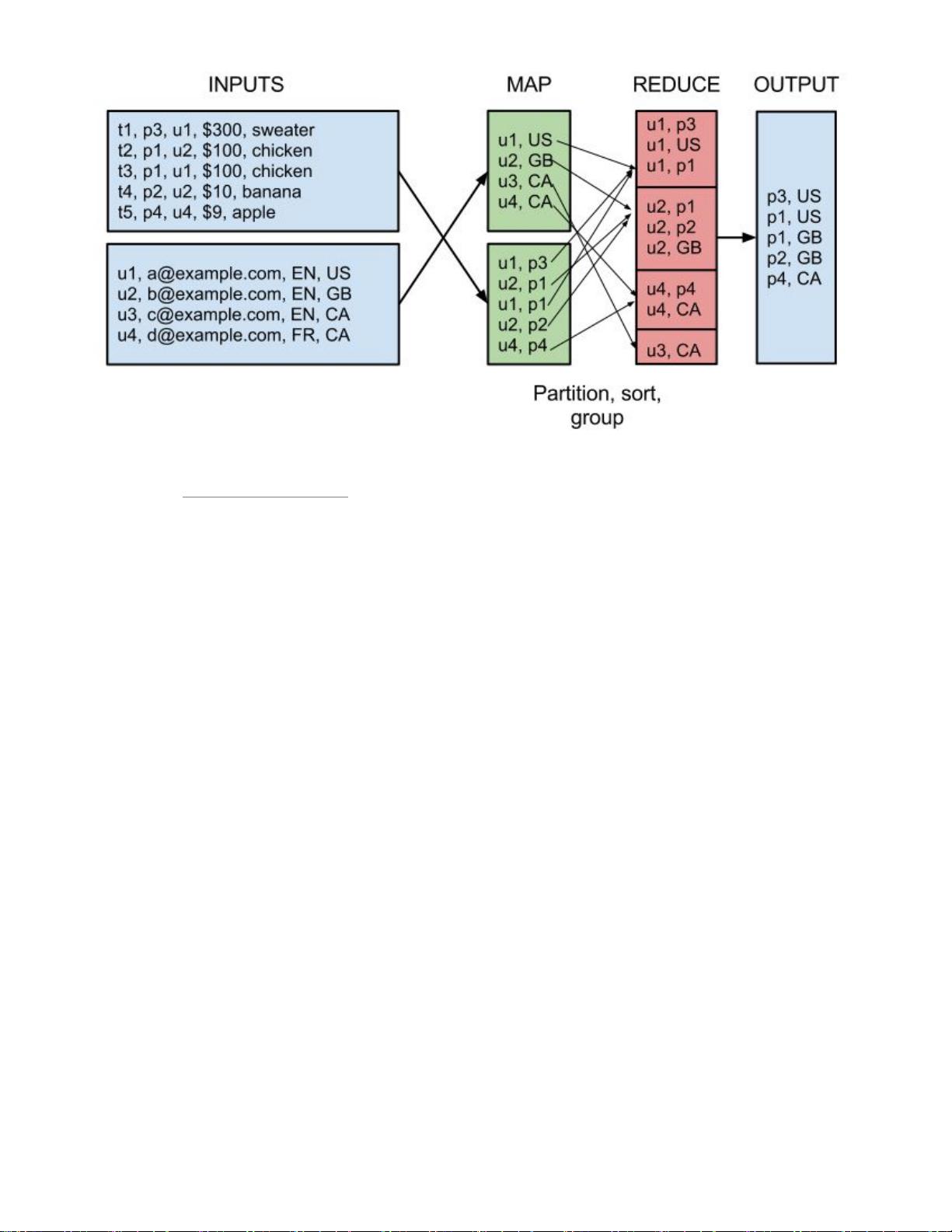
而Pig Latin又是通过编译为MapReduce,在Hadoop集群上执行的。上述程序被编译成MapReduce
时,会产生如下图所示的Map和Reduce:
剩余11页未读,继续阅读
2019-09-17 上传
2022-08-08 上传
2021-10-14 上传
2021-03-11 上传
2022-07-09 上传
2024-04-08 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

天眼妹
- 粉丝: 29
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- 温特线性matlab代码-matlab_NS_solvers:旧的研究代码。主要是涡量公式中的2DNS求解器
- 行业文档-设计装置-一种切纸机的双位刀头.zip
- Lora-32-Connect-by-Wifi
- 视图:场景模块的界面,为发送到渲染器的显示对象提供用户交互输入输出和剔除管理
- omniauth-rails_csrf_protection:在Rails应用程序的OmniAuth请求端点上提供CSRF保护
- ryanatkn
- 基于神经网络的人脸识别.zip
- derrobott.github.io:没事了
- matlab导弹落点代码-missile_simulation_matlab:导弹仿真Matlab代码
- iains:TestAccount
- xlog:xlog是netcontext感知HTTP应用程序的记录器
- 自动驾驶汽车案例研究
- 「基于图像识别的收银台」客户端软件,基于OpenCV + Qt,需要搭配「基于图像识别的收银台」后端服务使用。.zip
- darwish-rainmeter
- CSCI3800_Sp15_Team8:CSCI3800 Spring 2015 Team 8项目
- blog
