线性分类器与神经网络分类器比较
15 浏览量
更新于2024-08-30
1
收藏 260KB PDF 举报
该文主要讨论了线性分类器与神经网络分类器之间的对比,并以一个简单的二维数据集为例,展示了如何使用线性分类器进行训练。文中涉及到的基础概念包括训练数据的生成、线性分类器的训练以及数据可视化。
在机器学习领域,分类器是用来对数据进行分类的模型。线性分类器,如逻辑回归或支持向量机,是基于特征之间的线性关系来做出预测的模型。它们通常易于理解和实现,计算效率高,但可能无法处理非线性的复杂数据分布。
神经网络分类器则更为复杂,它们由多层神经元构成,能够通过学习权重和偏置来建立复杂的非线性关系。反向传播是神经网络中的一种关键算法,用于更新网络的参数,以最小化损失函数。然而,对于初学者来说,反向传播的概念可能较为抽象,需要深入学习和理解。
文中提供的代码示例生成了一个包含三个类别的二维数据集,每个类别由N个点组成,分布在不同的圆环上。这种数据集可以用来直观地比较线性和非线性分类器的效果。线性分类器在这样的数据集上可能会遇到困难,因为它试图找到一个超平面将不同类别的点分开,而在这个例子中,超平面并不存在,因为类别之间是连续分布的。
训练线性分类器的部分展示了如何用Python的NumPy库构建和训练模型。尽管没有展示完整的训练过程和评估结果,但可以想象,对于这个特定的数据集,线性分类器可能无法完美地将所有点正确分类。
对比线性分类器和神经网络分类器,神经网络由于其内在的非线性能力,通常更适合处理更复杂的数据模式。然而,它们的训练过程更加耗时,且需要更多的计算资源。此外,神经网络容易出现过拟合问题,需要使用正则化等技术来避免。
总结来说,线性分类器适合处理线性可分的问题,简单快速;而神经网络分类器能处理非线性问题,但需要更多调参和资源。选择哪种分类器取决于具体任务的复杂性、可用资源以及对模型解释性的需求。对于初学者,理解反向传播和神经网络的工作原理是非常重要的,这需要进一步的学习和实践。
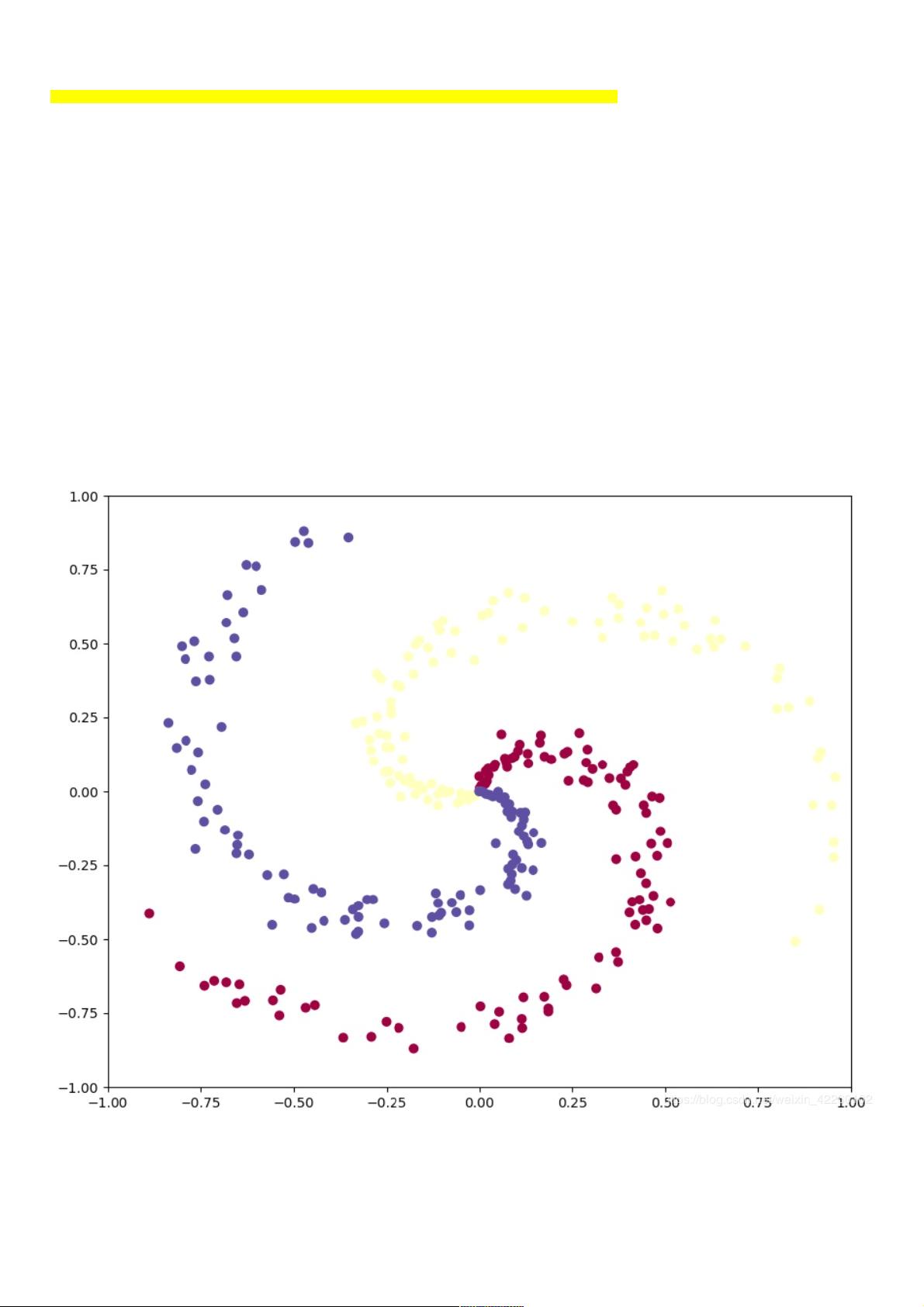
线性分类器和神经网络分类器的对比线性分类器和神经网络分类器的对比
在这部分对反向传导不是很理解,觉得我以后得 再看其他书籍了,这个视频课真的只适合入门的简单了解
1. 训练数据训练数据
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
np.random.seed(0)
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D))
y = np.zeros(N*K, dtype='uint8')
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] y[ix] = j
fig = plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim([-1,1])
plt.ylim([-1,1])
plt.show()
运行结果:
2.使用线性分类器使用线性分类器
#Train a Linear Classifier
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D))
下载后可阅读完整内容,剩余4页未读,立即下载
2021-08-15 上传
2021-03-16 上传
2018-08-10 上传
2022-06-20 上传
2024-05-01 上传
2021-04-28 上传
点击了解资源详情
点击了解资源详情

weixin_38677725
- 粉丝: 5
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
