Python BeautifulSoup库入门与HTML/XML解析实例
PDF格式 | 103KB |
更新于2024-08-29
| 125 浏览量 | 举报
Python爬虫库BeautifulSoup是一个强大的工具,用于解析HTML和XML文档,使得从网页中提取数据变得更加简单和灵活。它在Python爬虫领域中扮演着关键角色,因为它无需依赖复杂的正则表达式,提供了友好的API来遍历和操作网页结构。
首先,我们来了解一下BeautifulSoup的基本概念。它是一个基于Python的库,支持多种解析器,如lxml、html.parser等,可以根据需求选择最适合的解析引擎。其设计初衷是为了简化HTML文档的解析过程,使得开发者能够轻松地定位、提取和操作网页中的数据,例如文本、链接、标签属性等。
在快速入门部分,我们通过一个简单的例子展示了如何创建BeautifulSoup对象。通过导入`bs4`模块,我们可以直接使用`BeautifulSoup`类,并传入HTML文档和解析器名称。在这个例子中,HTML文档被存储在一个字符串变量`html_doc`中,然后通过'lxml'解析器创建了一个BeautifulSoup对象`soup`。
接下来,我们探索了几个关键操作:
1. `prettify()`方法可以美化输出的HTML结构,使其更易于阅读。
2. `title`属性用来获取文档的标题,这里返回的是"The Dormouse's story"。
3. `p['class']`获取第一个`<p>`标签的CSS类,这里返回的是`['title']`,表明这个`<p>`标签可能是标题的一部分。
4. `a`表示获取第一个`<a>`(即链接)标签,而`find_all('a')`则返回文档中所有的`<a>`标签列表。
5. `find(id="link3")`则是根据指定ID查找第一个匹配的标签,这里没有ID为"link3"的标签,所以返回`None`。
最后,我们展示了如何使用循环遍历所有`<a>`标签并获取它们的`href`属性,这有助于收集页面上的链接信息。
BeautifulSoup提供了一套强大的API,帮助开发者有效地进行网页抓取和数据提取。无论是简单的文档浏览还是复杂的数据挖掘,BeautifulSoup都是Python爬虫开发者不可或缺的工具。通过深入理解和实践,开发者可以轻松应对各种网页解析任务,进一步提升自动化数据采集的效率。
Python爬虫库爬虫库BeautifulSoup的介绍与简单使用实例的介绍与简单使用实例
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,本文为大家介绍下Python爬虫库BeautifulSoup的介绍
与简单使用实例其中包括了,BeautifulSoup解析HTML,BeautifulSoup获取内容,BeautifulSoup节点操作,BeautifulSoup获
取CSS属性等实例
一、介绍
BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页
信息的提取。
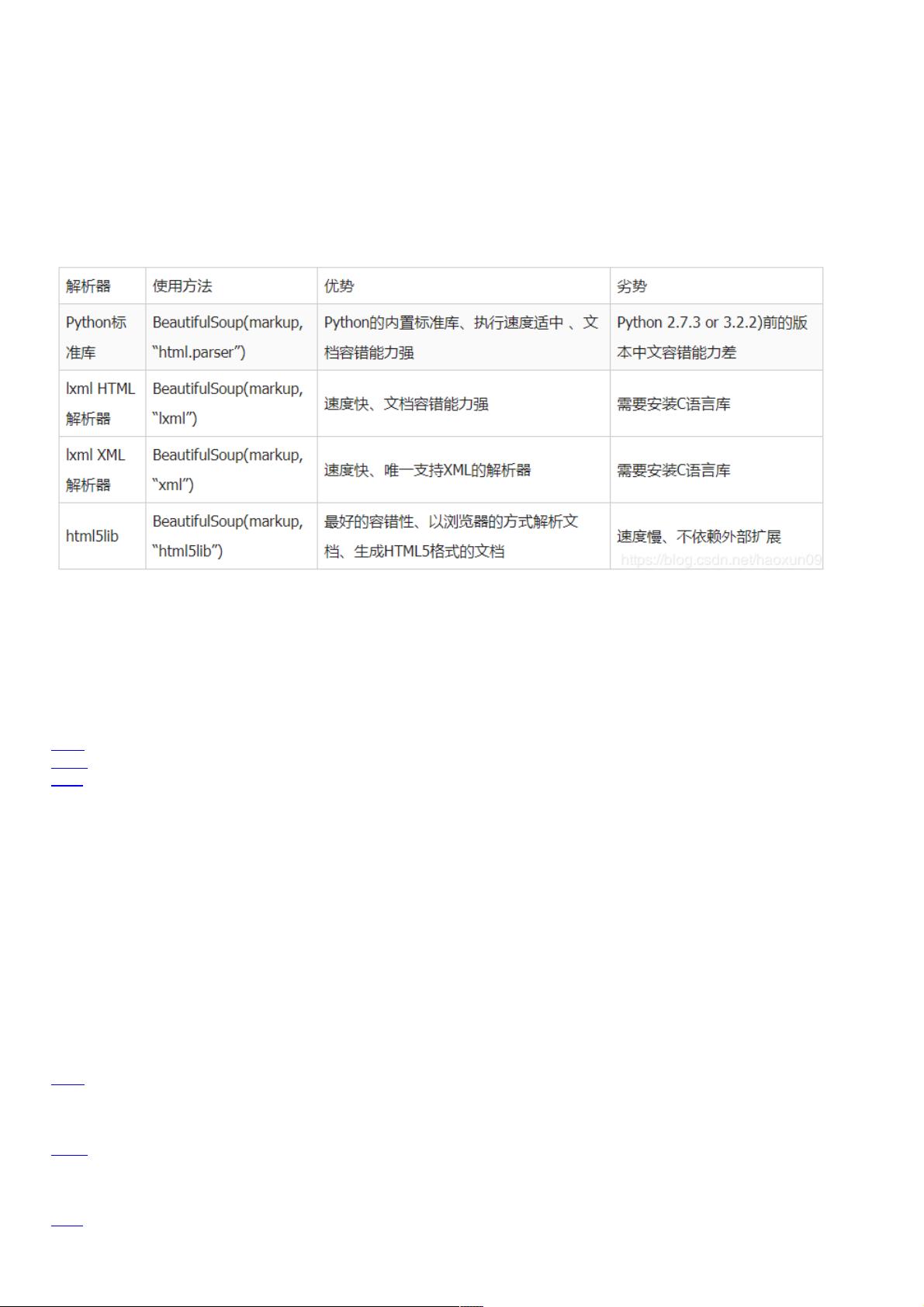
Python常用解析库
二、快速开始
给定html文档,产生BeautifulSoup对象
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc,'lxml')
输出完整文本
print(soup.prettify())
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
下载后可阅读完整内容,剩余5页未读,立即下载
相关推荐



weixin_38626179
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微波网络分析仪详解:概念、参数与测量
- 从Windows到Linux:一个UNIX爱好者的心路历程
- 经典Bash shell教程:深入学习与实践
- .NET平台入门教程:C#编程精髓
- 深入解析Linux 0.11内核源代码详解
- MyEclipse + Struts + Hibernate:初学者快速配置指南
- 探索WPF/E:跨平台富互联网应用开发入门
- Java基础:递归、过滤器与I/O流详解
- LoadRunner入门教程:自动化压力测试实践
- Java程序员挑战指南:BITSCorporation课程
- 粒子群优化在自适应均衡算法中的应用
- 改进LMS算法在OFDM系统中的信道均衡应用
- Ajax技术解析:开启Web设计新篇章
- Oracle10gR2在AIX5L上的安装教程
- SD卡工作原理与驱动详解
- 基于IIS总线的嵌入式音频系统详解与Linux驱动开发
