大数据分析:深入理解Kylin与数据仓库
需积分: 14 39 浏览量
更新于2024-07-09
收藏 4.2MB PDF 举报
"大数据学习资源之Kylin.pdf"
大数据学习资源主要关注的是Kylin技术,它是一种开源的分布式分析引擎,设计用于提供亚秒级的Hadoop之上SQL查询性能。Kylin最初由eBay公司开发,并且现在是Apache软件基金会的顶级项目。本资源主要涵盖了以下几个方面的知识:
1. 数据库与数据仓库的区别:
数据库是面向事务的设计,存储在线的业务数据,用于实时响应业务变化。它们遵循关系数据库的三范式设计,强调数据的一致性和完整性。而数据仓库则面向分析,主要用于存储历史数据,支持企业的决策过程。数据仓库允许数据冗余,以提高多维查询的效率,提供更丰富的观察视角。
2. Kylin的学习目标:
学习Kylin的目标包括理解其核心概念,如数据仓库、OLAP与OLTP的区别,以及维度和度量的概念。此外,还会涉及星型模型和雪花模型这两种常见的数据仓库建模方式。
3. 数据仓库(DW)与商业智能(BI):
数据仓库是BI系统的基础,它整合来自不同数据源的信息,通过多维分析为决策提供支持。数据仓库中的数据通常包含时间属性,以反映数据随时间的变化。
4. OLAP(在线分析处理)与OLTP(在线事务处理):
OLAP专注于对大量历史数据进行多维度分析,适合复杂查询和分析,而OLTP则关注日常业务操作,如插入、删除、更新和查询,确保快速处理事务。
5. 维度与度量:
维度是数据分析中的关键概念,代表观察数据的角度,如时间、地点等属性。度量则是基于数据计算出的数值,如总销售额、用户数量等,用于衡量业务性能。在SQL查询中,`GROUP BY`子句中的字段通常是维度,而聚合函数(如`SUM()`)计算的结果为度量。
举例说明:
考虑一个数据集,包含年份、商场名、类别、物品和总销售额等字段。一个SQL查询可能如下所示:
```sql
SELECT category, SUM(sales)
FROM dataset
GROUP BY category;
```
在这个例子中,“类别”是维度,`SUM(sales)`是度量。这将显示不同商品类别的总销售额,帮助分析各类别的销售表现。
6. Kylin与Hive的关系:
在大数据领域,Hive通常作为数据仓库的首选工具。Kylin构建于Hadoop之上,与Hive紧密集成,提供预计算和立方体构建功能,以实现快速的OLAP查询。通过预先计算并存储汇总数据,Kylin能够在大数据量下提供高效的分析性能。
通过深入学习这些概念,读者可以掌握如何利用Kylin进行大数据分析,并提升在大规模数据集上的查询效率。这对于企业实施数据驱动决策和构建高效BI系统至关重要。

2.7.3. 两者间的区别
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要
高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。
正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL 、以及后期的维护都要复杂一
些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
2.8.
Kylin
的由来
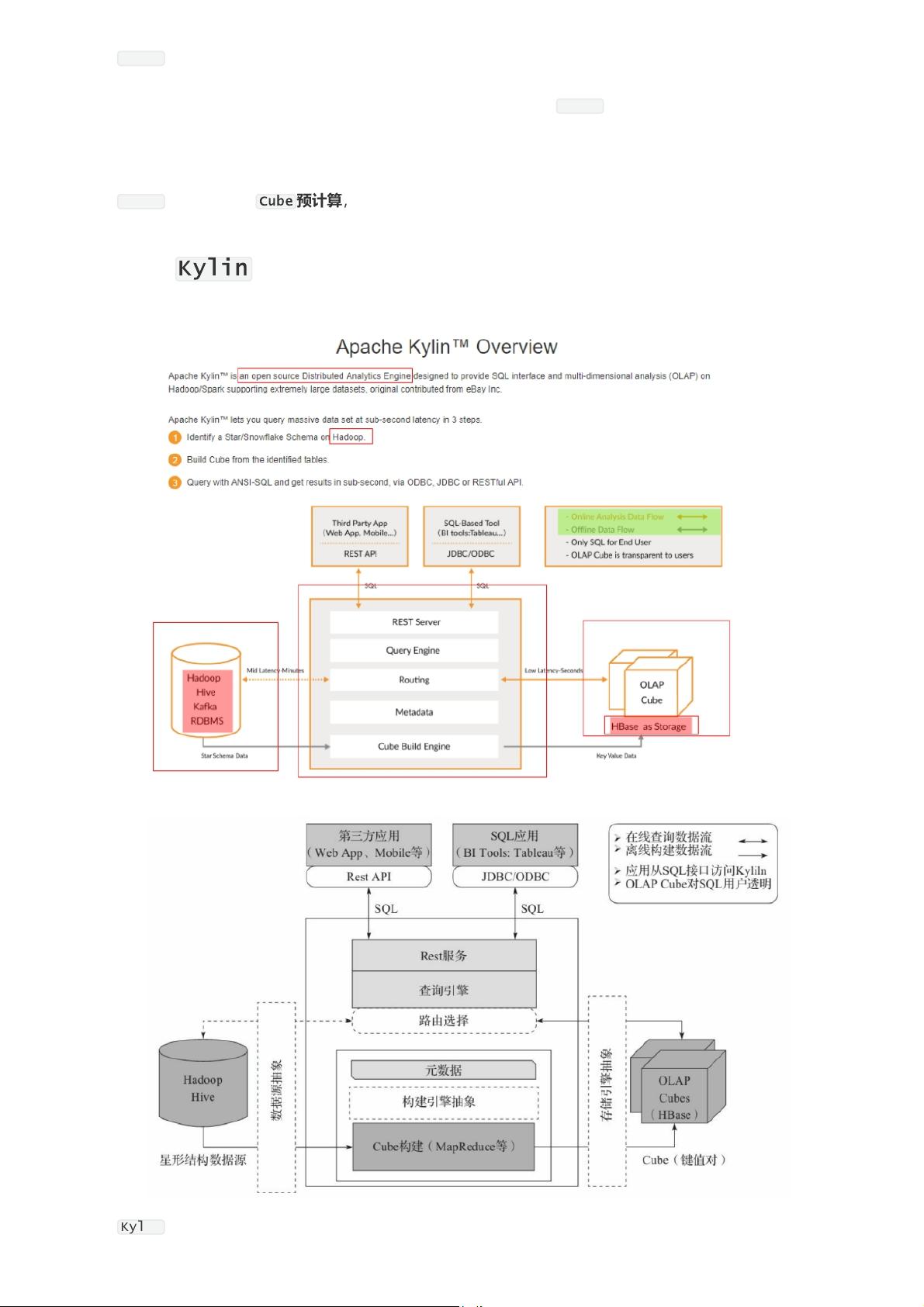
Apache Kylin ( Extreme OLAP Engine for Big Data )是一个开源的分布式分析引擎,为 Hadoop
等大型分布式数据平台之上的超大规模数据集通过标准 SQL 查询及多维分析( OLAP )功能,提供亚秒
级的交互式分析能力。
Apache Kylin ,中文名麒麟,是 Hadoop 动物园中的重要成员。 Apache Kylin 是一个开源的分布式
分析引擎,最初由 eBay 开发贡献至开源社区。它提供 Hadoop 之上的 SQL 查询接口及多维分析
( OLAP )能力以支持大规模数据,能够处理 TB 乃至 PB 级别的分析任务,能够在亚秒级查询巨大的
Hive 表,并支持高并发。
Apache Kylin 于2014年10月在 github 开源,并很快在2014年11月加入 Apache 孵化器,于 2015年
11月正式毕业成为 Apache 顶级项目,也成为首个完全由中国团队设计开发的 Apache 顶级项目。于
2016年3月, Apache Kylin 核心开发成员创建了 Kyligence 公司,力求更好地推动项目和社区的快速
发展。
2.9. 为什么使用它
在大数据的背景下, Hadoop 的出现解决了数据存储问题,但如何对海量数据进行 OLAP 查询,却一直令
人十分头疼。企业中大数据查询大致分为两种:即席查询和定制查询。
即席查询
Hive 、 SparkSQL 等 OLAP 引擎,虽然在很大程度上降低了数据分析的难度,但它们都只适用于即席查
询的场景。它们的优点是查询灵活,但是随着数据量和计算复杂度的增长,响应时间不能得到保证。
定制查询
多数情况下是对用户的操作做出实时反应, Hive 等查询引擎很难满足实时查询,一般只能对数据仓库
中的数据进行提前计算,然后将结果存入 Mysql 等关系型数据库,最后提供给用户进行查询。
在上述背景下, Apache Kylin 应运而生。不同于大规模并行处理 Hive 等架构, Apache Kylin 采用"
预计算"的模式,用户只需要提前定义好查询维度, Kylin 将帮助我们进行计算,并将结果存储到
HBase 中,为海量数据的查询和分析提供亚秒级返回,是一种典型的空间换时间的解决方案。
Apache Kylin 的出现不仅很好地解决了海量数据快速查询的问题,也避免了手动开发和维护提前计算
程序带来的一系列麻烦。
2.10.
Kylin
的工作原理
上面章节所描述的对数据模型做 Cube 预计算就是 Kylin 的工作原理,典型的空间换时间的例子。利用
cube 计算的结构加速我们的查询。具体过程如下。
1. 指定数据模型,定义维度和度量。
2. 预计算 Cube ,计算所有 Cuboid 并保存为物化视图。
3. 执行查询时,读取 Cuboid ,运算,产生查询结果。
剩余30页未读,继续阅读
2023-05-18 上传
2021-10-02 上传
2022-06-15 上传
2022-12-24 上传
2019-06-05 上传
2019-08-06 上传
2022-06-21 上传
2022-11-19 上传
2023-09-05 上传

weixin_44229058
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







