Hbase大数据实战:从概念到架构解析
195 浏览量
更新于2024-08-27
收藏 261KB PDF 举报
"大数据干货|Hbase设计与开发实战"
在大数据时代,传统的关系型数据库在处理大规模、非结构化或半结构化数据时显得力不从心。Hbase作为NoSQL数据库的一员,应运而生,旨在解决这一问题。Hbase设计的核心理念是提供对大规模数据的高效存储和检索,特别适合处理TB至PB级别的数据,同时能应对高并发访问。
1. **大数据与NoSQL的兴起**
随着互联网公司的崛起,如Google和Facebook,以及金融和电信行业的数据增长,传统的ACID(原子性、一致性、隔离性和持久性)保证的关系型数据库已无法满足需求。NoSQL数据库的出现,放弃了部分ACID特性,以换取更高的可扩展性和性能,特别是对于非结构化数据的处理。Hbase就是这类数据库中的一个典型代表,它强调强一致性,允许数据在写入后立即被读取。
2. **Hbase的特性**
- **键值API**:Hbase提供键值接口,简化了数据操作。
- **分布式存储**:基于Hadoop的分布式存储机制,可在多节点集群上运行,提供高可用性。
- **透明性**:对客户端应用透明,降低开发难度。
- **高性能**:针对海量数据和高并发进行了优化。
- **数据模型**:Hbase采用表格形式存储数据,由行键、列簇、列限定符和时间戳组成,这种模型适合半结构化数据的存储。
3. **Hbase架构**
Hbase的架构设计是为了解决水平扩展性问题。数据以行键进行分区,分布在不同的RegionServer上。每个RegionServer负责一部分行键范围内的所有数据。当Region过大时,会自动分裂成两个新的Region,保证系统的负载均衡。此外,Hbase利用Zookeeper进行集群协调和元数据管理,确保数据的一致性。
4. **Hbase与Hadoop生态**
作为Hadoop生态的一部分,Hbase利用HDFS(Hadoop Distributed File System)进行数据存储,通过Hadoop的DataNode实现数据冗余,以保障数据安全。MapReduce则用于批处理任务,处理Hbase中的大数据量。
5. **列族与时间戳**
数据在Hbase中按照列族(Column Family)组织,列族内可以有多个列(Column Qualifier),每个列都可以有多个时间戳版本,这允许存储历史数据并进行版本控制。
6. **开发与应用**
开发者可以利用Hbase的Java API或其他语言的客户端库进行数据操作,包括增删改查。Hbase广泛应用于日志分析、实时监控、用户行为追踪等多个领域。
Hbase作为一种分布式、面向列的NoSQL数据库,是处理大规模非结构化数据的理想选择。其设计理念和架构特性使其在大数据环境下表现出色,为企业提供了高效的数据存储和处理能力。
大数据干货大数据干货|Hbase设计与开发实战设计与开发实战
1 Hbase概述
大数据及 NoSQL 的前世今生
传统的关系型数据库处理方式是基于全面的ACID保证,遵循SQL92的标准表设计模式(范式)和数据类型,基于SQL语言的
DML数据交互方式。长期以来这种基于关系型数据库的IT信息化建设中发展良好,但受制于关系型数据库提供的数据模型,对
于逐渐出现的,为预先定义模型的数据集,关系型数据库不能很好的工作。越来越多的业务系统需要能够适应不同种类的数据
格式和数据源,不需要预先范式定义,经常是非结构化的或者半结构化的(如用户访问网站的日志),这需要系统处理比传统
关系型数据库高几个数量级的数据(通常是TB及PB规模级别)。传统关系型数据库能够纵向扩展到一定程度(如Oracle的
RAC,IBM的pureScale)。但这通常意味着高昂的软件许可费用和复杂的应用逻辑。
基于系统需求发生了巨大变化,数据技术的先驱们不得不重新设计数据库,基于大数据的NoSQL的曙光就这样出现了,大数
据及NoSQL的使用首先在google、facebook等互联网公司,随后是金融、电信行业,众多Hadoop&NoSQL的开源大数据项目
如雨后春笋般发展,被互联网等公司用于处理海量和非结构化类型的数据。一些项目关注于快速key-value的键值存储,一些
关注内置数据结构或者基于文档的抽象化,一些NoSQL数据管理技术框架为了性能而牺牲当前的数据持久化,不支持严格的
ACID,一些开源框架甚至为了性能放弃写数据到硬盘……
Hbase就是NoSQL中卓越的一员,Hbase提供了键值API,承诺强一致性,所以客户端能够在写入后马上看到数据。HBase依
赖Hadoop底层分布式存储机制,因此能够运行在多个节点组成的集群上,并对客户端应用代码透明,从而对每个开发人员来
说设计和开发Hbase的大数据项目变得简单易行。Hbase被设计来处理TB到PB级的数据,并针对该类海量数据和高并发访问
做了优化,作为Hadoop生态系统的一部分,它依赖Hadoop其他组件提供的重要功能,如DataNode数据冗余和MapReduce批
注处理。
2 Hbase架构及框架简介
本文中我们简要介绍下Hbase的架构及框架,Hbase是一种专门为半结构化数据和水平扩展性设计的数据库。它把数据存储在
表中,表按“行健,列簇,列限定符和时间版本”的四维坐标系来组织。Hbase是无模式数据库,只需要提前定义列簇,并不需
要指定列限定符。同时它也是无类型数据库,所有数据都是按二进制字节方式存储的,对Hbase的操作和访问有5个基本方
式,即Get、Put、Delete和Scan以及Increment。Hbase基于非行健值查询的唯一途径是通过带过滤器的扫描。
由于Hbase针对PB、TB存储级别,亿级行数据的海量表记录的高并发,极限性能查询检索的设计初衷,Hbase在物理架构方
面设计成一个依靠HadoopHDFS的全分布式的存储集群,并基于Hadoop的MapReduce网格计算框架,用以支持高吞吐量数
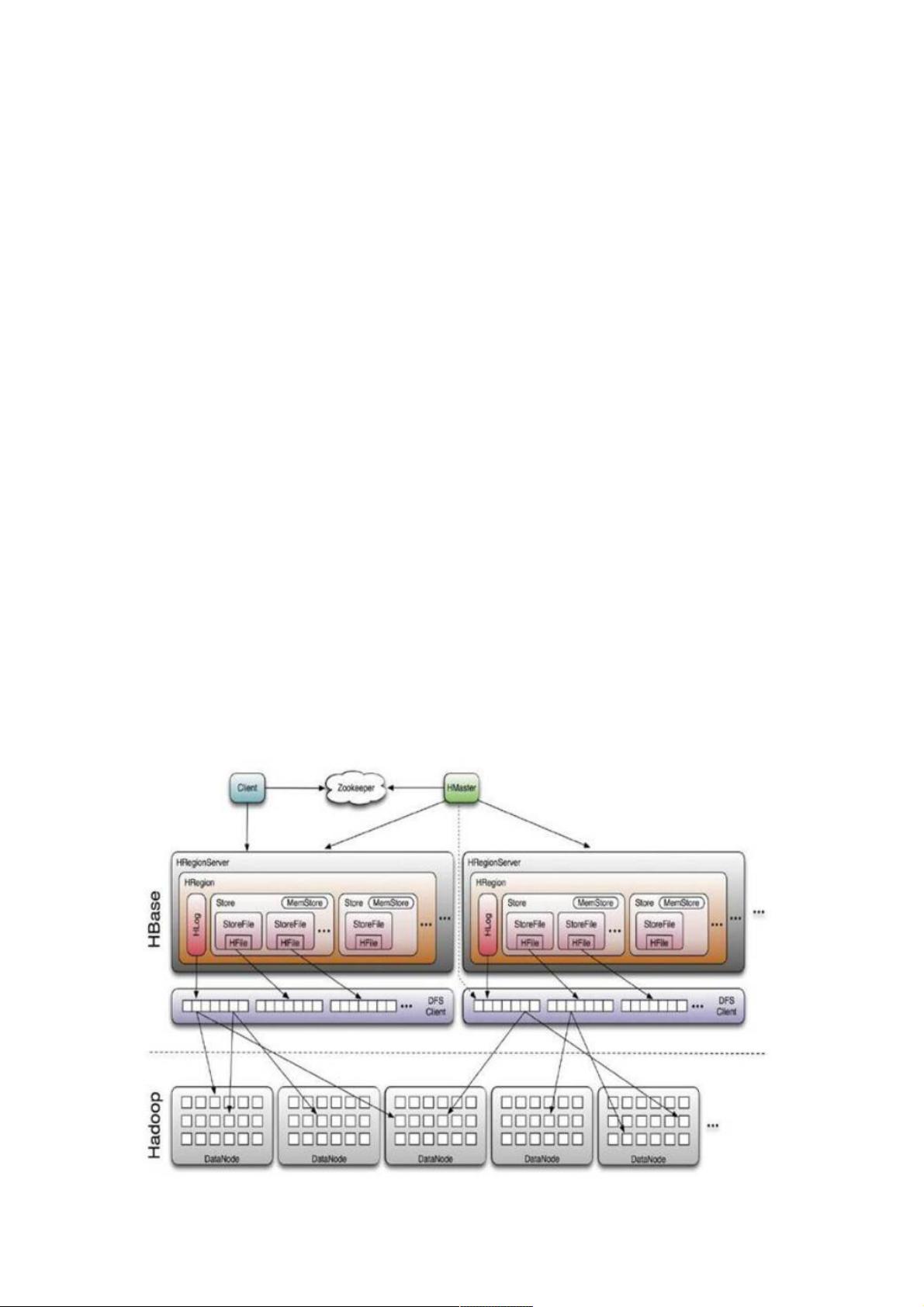
据访问,支持可用性和可靠性,其整体架构如下图所示:
图1.Hbase整体架构图
从上图我们可以看出Hbase的组成部件,HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认
一个HRegion超过256M就要被分割成两个,由HRegionServer管理,管理哪些HRegion由HMaster分配。
HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族(ColumnFamily)创建一个Store实例,每个
下载后可阅读完整内容,剩余6页未读,立即下载
2022-04-17 上传
2019-09-24 上传
点击了解资源详情
2021-02-25 上传
2021-10-14 上传
2018-11-11 上传
2017-07-31 上传
2023-02-23 上传
2022-07-26 上传

weixin_38692836
- 粉丝: 4
- 资源: 974
 我的内容管理
展开
我的内容管理
展开







最新资源
- 编程之道全本 by Geoffrey James
- JBoss4.0 JBoss4.0 JBoss4.0 JBoss4.0 JBoss4.0
- DWR中文文档,DWR中文文档
- 汉诺塔问题 仅限11个盘子 效率较高
- 生化免疫分析仪——模数转换模块设计
- ajax基础教程.PDF
- symbian S60编程书
- 智能控制\BP神经网络的Matlab实现
- matlabziliao
- PowerBuilder8.0中文参考手册.pdf
- NNVVIIDDIIAA 图形处理器编程指南(中文)
- UMl课件!!!!!!!!!
- 电工学试卷及答案(电工学试卷2007机械学院A卷答案)
- 高质量C++编程指南.pdf
- 大公司的Java面试题集.doc
- 基于UBUNTU平台下ARM开发环境的建立
