Flink架构:统一流批处理,高效支持高吞吐与低延迟
88 浏览量
更新于2024-08-28
收藏 1.89MB PDF 举报
Apache Flink是一个强大的开源流处理和批处理框架,其核心优势在于其独特的设计,将流处理和批处理视为同一个运行时环境下的两种表现形式。Flink的主要特点是能够在同一套系统中支持高吞吐量、低延迟的实时流处理,以及对批处理的支持,通过定义有界和无界的输入数据流来实现这一点。
Flink流处理特性包括:
1. ** Exactly-once保证**:Flink提供有状态计算的Exactly-once语义,确保在处理过程中数据的一致性和可靠性,这对于实时业务场景尤其重要。
2. **多窗口操作**:支持带有事件时间的窗口,如time-based、count-based、session和data-driven窗口,这允许根据数据的特性进行复杂的时间窗口分析。
3. **Backpressure机制**:Flink采用持续流模型,具备回压功能,能够动态调整处理速率以适应输入数据流的波动,防止由于数据流量过大导致系统崩溃。
4. **容错性**:通过轻量级分布式快照技术,Flink能够在出现故障时进行恢复,确保处理的连续性和稳定性。
5. **多模式处理**:Flink的运行时支持Batch on Streaming(批处理在流处理中)和Streaming处理两种模式,允许用户灵活选择最适合的应用场景。
6. **内存管理和性能优化**:Flink在JVM内有自己的内存管理系统,能有效利用资源。它还自动优化程序,避免不必要的Shuffle和排序操作,通过缓存中间结果提高性能。
7. **编程接口**:提供了DataStream API和DataSet API,分别用于构建并行数据流图,其中DataSet API使用optimizer进行更深入的优化,而DataStream API则依赖streambuilder进行直观的构建。
8. **扩展性与部署**:Flink支持多种部署选项,如本地、远程和YARN等,使得在不同环境中部署变得简单。同时,还有一系列配套库,如Table用于处理逻辑表查询,FlinkML支持机器学习,Gelly用于图像处理,以及复杂的事件处理能力。
Flink以其灵活的架构和高效的功能,成为现代大数据处理中的关键组件,适用于各种实时和批量数据处理场景,帮助企业实现高效率的数据处理和分析。
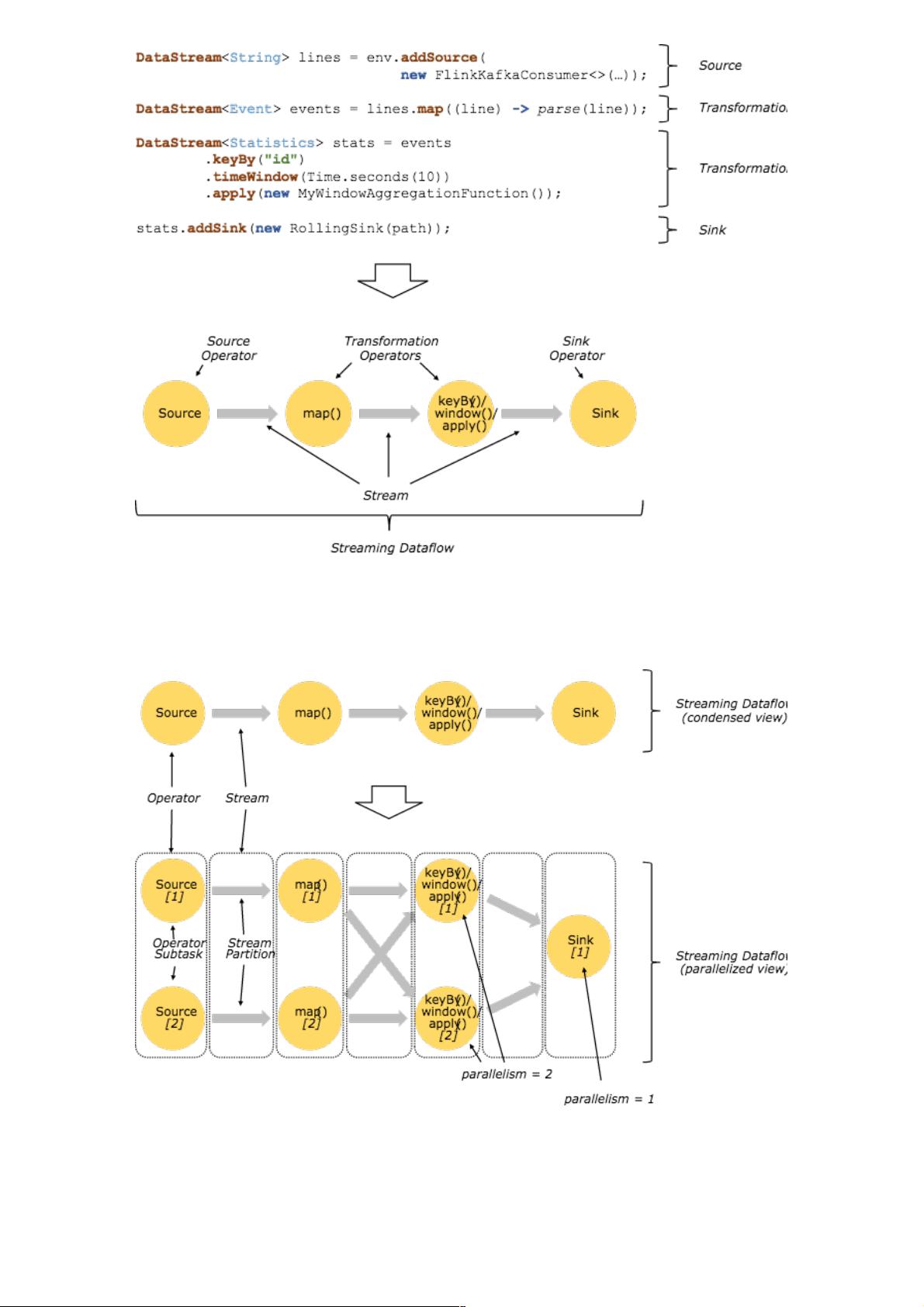
2. 并行数据流
一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask,每一个
Operator Subtask是在不同的线程中独立执行的。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行
度总是等于生成它的Operator的并行度。
One-to-one模式
比如从Source[1]到map()[1],它保持了Source的分区特性(Partitioning)和分区内元素处理的有序性,也就是说map()[1]的
Subtask看到数据流中记录的顺序,与Source[1]中看到的记录顺序是一致的。
Redistribution模式
这种模式改变了输入数据流的分区,比如从map()[1]、map()[2]到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],
剩余12页未读,继续阅读
2019-07-04 上传
2019-07-07 上传
2021-03-01 上传
2019-05-08 上传
2019-03-24 上传
2018-11-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38704565
- 粉丝: 6
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- 常用算法设计 强烈推荐
- Ant使用指南(不管你用没用过看了以后都有收益)
- 好的论文 洗衣机控制器
- cmd 命令大全 初学者
- 网络管理员----电子教程
- 计算机专科专业英语试卷
- head first c# 第二章(中文版)
- I2C总线规范(中文)
- 附录6-TurboC常用库函数.doc
- 无线传感器网络自组网协议的实现方法.pdf
- 无线Adhoc网络中QoS路由协议的研究.pdf
- 无线Adhoc网络MAC层吞吐量分析.pdf
- 双重认证Adhoc网络安全路由协议设计.pdf
- 基于多维Hash链的无线Ad_hoc安全路由数字签名方案.pdf
- 基于AdHoc的网络管理的研究与实现.pdf
- Linux内核源码情景分析.pdf
