谷歌MapReduce实现与数据处理概述
需积分: 0 106 浏览量
更新于2024-06-30
收藏 408KB DOCX 举报
"MapReduce是一种编程模型,用于大规模数据集的并行计算。它简化了在大规模集群上处理数据的流程,主要包含映射(Map)和规约(Reduce)两个核心步骤。用户只需编写Map和Reduce函数,Map将输入数据拆分成中间键值对,Reduce则对相同键的中间值进行聚合。论文描述了MapReduce在谷歌计算环境中的实现,该环境包括大量的联网机器,每个机器具有一定的计算和存储能力,以及一个分布式文件系统来管理和保证数据的可靠性和可用性。执行过程中,输入数据会被自动分割并分配给多个机器并行处理,而Reduce则通过分区函数将数据分布到不同的归约任务上。"
MapReduce的工作流程如下:
1. **编程模型**:MapReduce模型接收一组键值对作为输入,通过用户编写的Map函数处理,产生新的中间键值对。这些中间键值对随后根据用户定义的分区函数(如哈希取模)分布到R个归约任务中,由Reduce函数处理,最终生成输出的键值对集合。
2. **环境与实现**:在谷歌的环境中,MapReduce针对大规模的集群设计,机器通常配备双核CPU、2GB内存,并使用低延迟的网络连接。存储由直接连接到机器的IDE硬盘提供,通过一个分布式文件系统进行管理,确保容错性和可靠性。用户提交的作业由调度系统分配到集群的不同机器上。
3. **执行过程**:作业执行时,MapReduce库首先将输入数据分割成M个分片,每个大小在16MB到64MB之间。这些分片被分配到多台机器上,每台机器并行运行Map任务。Map函数将输入数据转化为中间键值对。接着,中间键值对根据分区函数分发给Reduce任务,Reduce函数接收相同键的所有中间值,执行归约操作,生成最终结果。
4. **容错性**:由于集群中机器可能出现故障,MapReduce实现提供了容错机制,能够检测失败并重新调度任务,确保作业的完整执行。
5. **优化与效率**:为了提高效率,MapReduce可以利用数据本地性原则,将Map任务分配到包含相应输入数据的机器上,减少网络传输。此外,Reduce任务可以通过并行化进一步加速,同时处理多个键的中间值。
6. **扩展性**:MapReduce模型的设计使得它可以轻松地扩展到数千台机器,处理PB级别的数据。随着集群规模的增长,计算能力也随之增强。
MapReduce为处理大规模数据提供了一种抽象和简化的方法,使得程序员可以专注于业务逻辑,而无需关注底层的分布式细节。这种模型在大数据处理领域,尤其是日志分析、搜索引擎索引构建、统计分析等多个场景中得到了广泛应用。
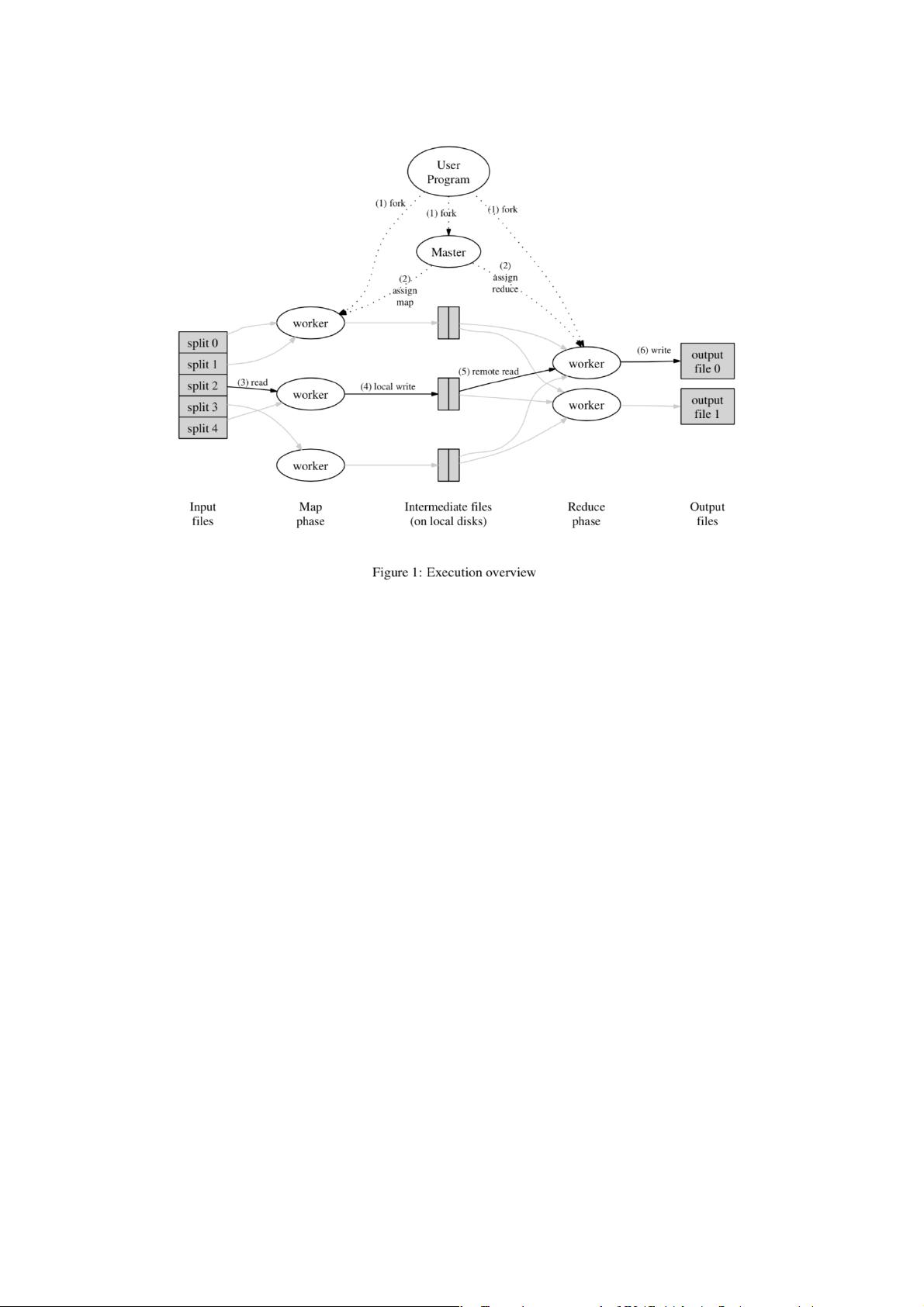
通过自动将输入数据分割成 M 个切片在多机器间分布式地调用 Map 函数
。这些输入分片可以被多台机器并行处理。通过使用分割函数(例如
`hash(key) mod R`)将过渡键分割到 R 个分区中中来分布式地调用归约函数
。分区数和分割函数由用户自定义。
图一展示了我们实现的 MapReduce 操作的基本工作流。当用户程序调用
MapReduce 函数,接下来的一系列动作将会发生:
a. 用户程序的 MapReduce 库首先将输入的文件分割成 M 个分片,每个
分片大小从 16MB 到 64MB 不等(可由用户通过可选参数配置)。然
后该库在集群上开启程序的多个拷贝。
b. 程序有一份拷贝是特殊的——主节点。其余的是工作节点,由主人分
配任务。有 M 个映射任务和 R 个归约任务分配。主人选择空闲的工作
节点,然后给它们分配一个映射或者归约任务。
剩余14页未读,继续阅读
187 浏览量
346 浏览量
218 浏览量
809 浏览量
2025-02-16 上传
2025-02-16 上传

練心
- 粉丝: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- 北京交通大学陈后金版信号与系统课程PPT完整学习资料
- 微信小程序漂流瓶完整毕业设计教程与源码
- 探索atusy:解开宇宙起源之谜
- Python狂野冒险:Sonia-Nottley之旅
- kurtogram V4:MATLAB实现的四阶谱分析工具
- MATLAB实现图像灰度变换提升画质
- 中国1:400万地貌数据及WGS1984坐标系解析
- 掌握Go语言:基础讲义与源代码分析
- 网银支付接口.net操作指南与安全实践
- 单片机设计的抢答器系统与Proteus仿真实现
- Python实践:问题解决与编程练习指南
- 掌握Android-shape标签:打造高大上界面
- MATLAB下的Frecca算法模糊聚类实战应用
- STM32项目在光伏行业电池板监控中的应用
- 深入解析ResHacker 3.5:功能丰富的DLL解包工具
- Stacken:化学考试必备的抽认卡应用程序
