Libra R-CNN:平衡学习目标检测算法解析
需积分: 10 105 浏览量
更新于2024-07-05
收藏 1.6MB PDF 举报
"Libra R-CNN演示文稿(PPT)——一种致力于平衡学习的目标检测模型,由浙江大学、香港中文大学、商汤研究院和悉尼大学的研究人员提出。该模型通过IoU平衡抽样、平衡特征金字塔和平衡L1损失解决训练过程中的不平衡问题,提升了目标检测的性能。已在CVPR 2019发表,并被IJCV采纳其扩展版。代码开源在mmdetection项目下,是OpenMMLab的一部分。"
Libra R-CNN是一种深度学习领域的目标检测算法,其核心目标是解决训练过程中存在的不平衡问题,从而提高检测的准确性和效率。该方法由Jiangmiao Pang等研究人员开发,他们来自浙江大学、香港中文大学、商汤研究院以及悉尼大学。该研究被发表在CVPR 2019,并且在国际期刊IJCV上被采纳了其扩展版。
在目标检测的训练过程中,有三个关键因素影响模型性能:样本选择的代表性、视觉特征的充分利用以及设计目标函数的优化。Libra R-CNN关注这三个层面的不平衡,通过引入三个创新元素进行改进:
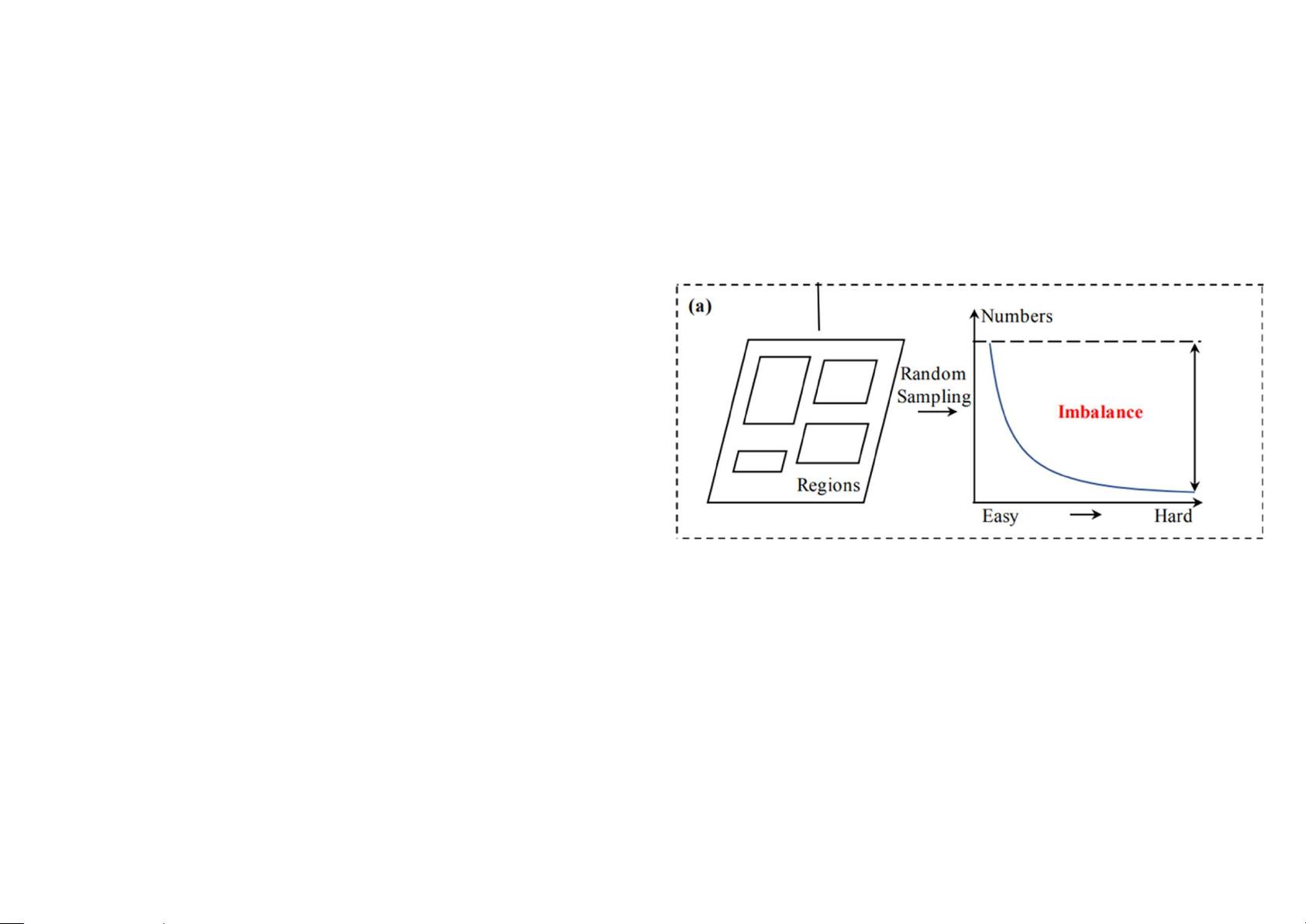
1. IoU平衡抽样(IoU-balanced sampling):针对样本级别的不平衡,传统方法如OHEM(在线 Hard Example Mining)虽然可以处理困难样本,但易受噪声点影响且计算成本高。IoU平衡抽样旨在更公平地对待不同IoU(Intersection over Union)级别的样本,减少难例的过度关注,确保各类别的训练样本均衡。
2. 平衡特征金字塔(balanced feature pyramid):在特征层面,Libra R-CNN通过构建平衡的特征金字塔,确保不同尺度的目标都能得到充分的特征表示,增强模型对多尺度目标的检测能力。
3. 平衡L1损失(balanced L1 loss):在目标函数层面,传统的L1损失可能造成不同损失值之间的不平衡。平衡L1损失旨在调整损失函数,使其对所有预测和真实边界框的差异都保持一致的敏感度,从而提升整体检测性能。
实验结果表明,Libra R-CNN在MS-COCO数据集上的表现优于现有的单一阶段和两阶段目标检测算法,证明了其在缓解训练不平衡问题上的有效性。此外,该研究还提供了开源代码,方便其他研究者和开发者在mmdetection框架下复现和进一步研究Libra R-CNN算法。
Libra R-CNN通过引入平衡策略,从样本、特征和损失函数三个方面系统地解决了目标检测训练过程中的不均衡问题,为提高深度学习目标检测模型的性能提供了一个有效的解决方案。
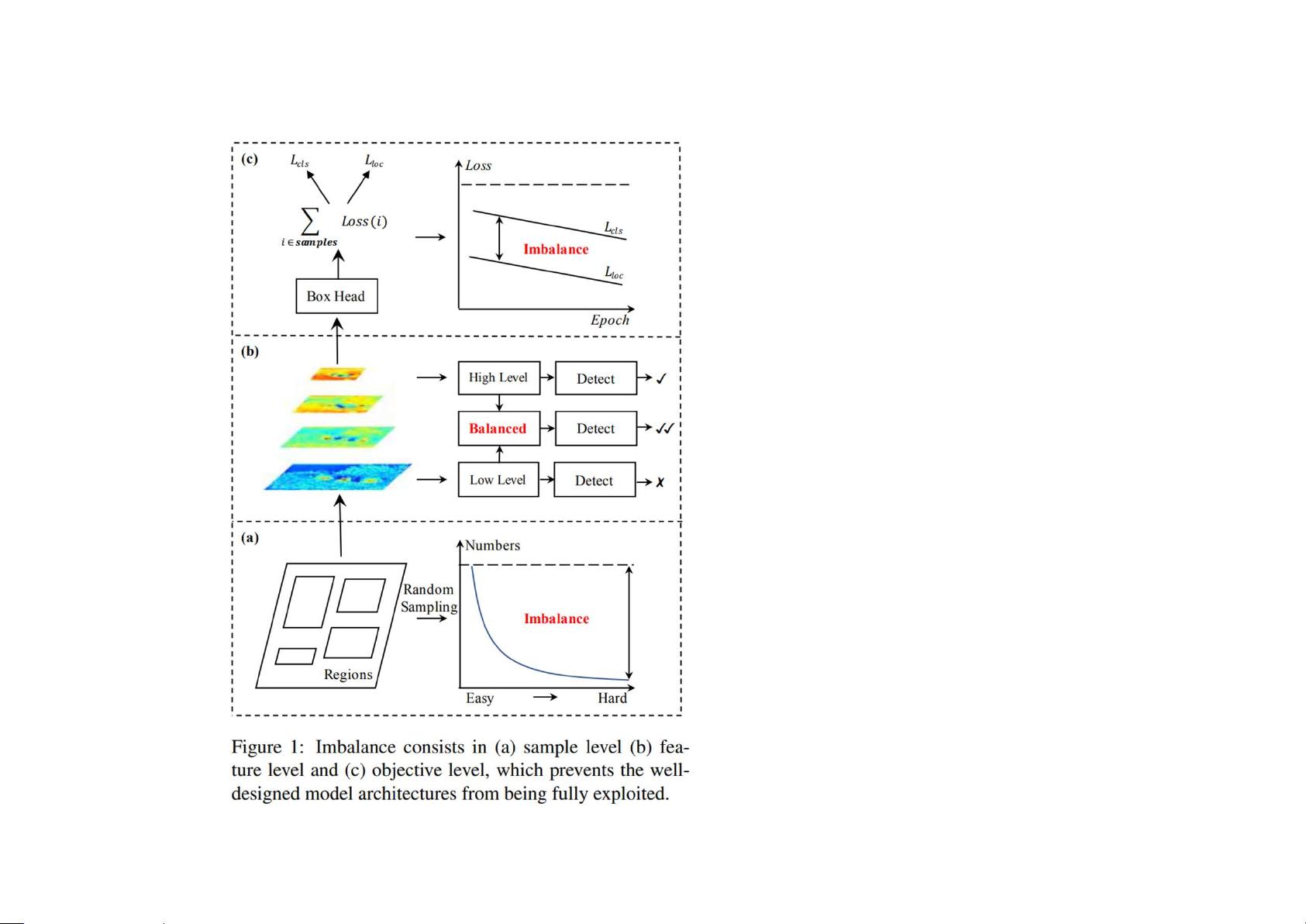
• Objective level imbalance.
• Feature level imbalance.
• Sample level imbalance.
剩余25页未读,继续阅读
2021-10-02 上传
2023-07-28 上传
2013-11-02 上传
2023-09-03 上传
2023-05-12 上传
2023-05-10 上传
2023-05-10 上传
2023-05-14 上传
2023-06-08 上传

today__present
- 粉丝: 45
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
