斯坦福CS229机器学习讲义:房价预测与监督学习
"这是一份来自斯坦福大学的机器学习公开课讲义,由Andrew Ng教授主讲,主要探讨了监督学习这一主题,并通过一个实际的例子——波特兰房屋价格预测,来阐述监督学习的基本概念和应用。"
正文:
监督学习是机器学习的一个重要分支,其核心思想是通过已有的带有标签的数据(即输入与对应正确输出的配对数据)来训练模型,从而使模型能够对新的、未知的数据进行预测。在这个例子中,我们关注的是一个回归问题,具体来说,就是如何根据房屋的居住面积(输入变量x)预测其价格(输出变量y)。
在描述中提到的数据集包含了47个来自波特兰的房屋,每个房屋的居住面积(单位:平方英尺)和售价(单位:千美元)被记录下来。我们可以把这些数据点在二维坐标系中绘制出来,其中x轴表示居住面积,y轴表示价格。这样的数据可视化可以帮助我们直观地理解数据分布和可能存在的关系。
为了建立一个能够预测其他房屋价格的模型,我们需要首先选择一个合适的算法。在监督学习中,常见的算法有线性回归、逻辑回归、决策树、支持向量机(SVM)、神经网络等。对于本例中的连续数值预测问题,线性回归是一个简单且常用的起点,因为它假设价格与面积之间存在线性关系。
线性回归模型可以表示为 y = wx + b,其中w是斜率(或权重),b是截距。在训练过程中,我们的目标是找到最佳的w和b值,使得模型对训练数据的预测误差最小。这通常通过最小化预测值与真实值之间的均方误差(Mean Squared Error, MSE)来实现,这是一个优化问题。
在实际操作中,我们通常会使用梯度下降法或者正规方程来求解这个问题。梯度下降是一种迭代方法,它逐步调整参数以减少损失函数(如MSE);而正规方程则提供了一个直接的解,适用于小规模数据和计算资源充足的场景。
一旦模型训练完成,我们可以用它来预测新房屋的价格。例如,对于一个新的房屋,我们将其居住面积作为输入x,模型将输出一个预测的价格y。需要注意的是,模型的预测能力不仅取决于训练数据的质量和数量,还依赖于模型本身的复杂度以及是否过拟合或欠拟合。在实际应用中,我们可能需要进行交叉验证和调参来优化模型性能。
这份讲义通过实际案例深入浅出地介绍了监督学习的基本概念,特别是线性回归在解决回归问题中的应用,同时也强调了数据预处理、模型选择、训练与验证的重要性。这些知识对于理解和应用机器学习技术具有基础性的指导价值。

16
Part II
Classification and logistic
regression
Lets now talk about the classification problem. This is just like the regression
problem, except that the values y we now want to predict take on only
a small number of discrete values. For now, we will focus on the binary
classification problem in which y can take on only two values, 0 and 1.
(Most of what we say here will also generalize to the multiple-class case.)
For instance, if we are trying to build a spam classifier for email, then x
(i)
may be some features of a piece of email, and y may be 1 if it is a piece
of spam mail, and 0 otherwise. 0 is also called the negative class, and 1
the positive class, and they are sometimes also denoted by the symbols “-”
and “+.” Given x
(i)
, the corresponding y
(i)
is also called the label for the
training example.
5 Logistic regression
We could approach the classification problem ignoring the fact that y is
discrete-valued, and use our old linear regression algorithm to try to predict
y given x. However, it is easy to construct examples where this method
performs very poorly. Intuitively, it also d oesn’t make sense for h
θ
(x) to take
values larger than 1 or smaller than 0 when we know that y ∈ {0, 1}.
To fix this, lets change the form for our hypotheses h
θ
(x). We will choose
h
θ
(x) = g(θ
T
x) =
1
1 + e
−θ
T
x
,
where
g(z) =
1
1 + e
−z
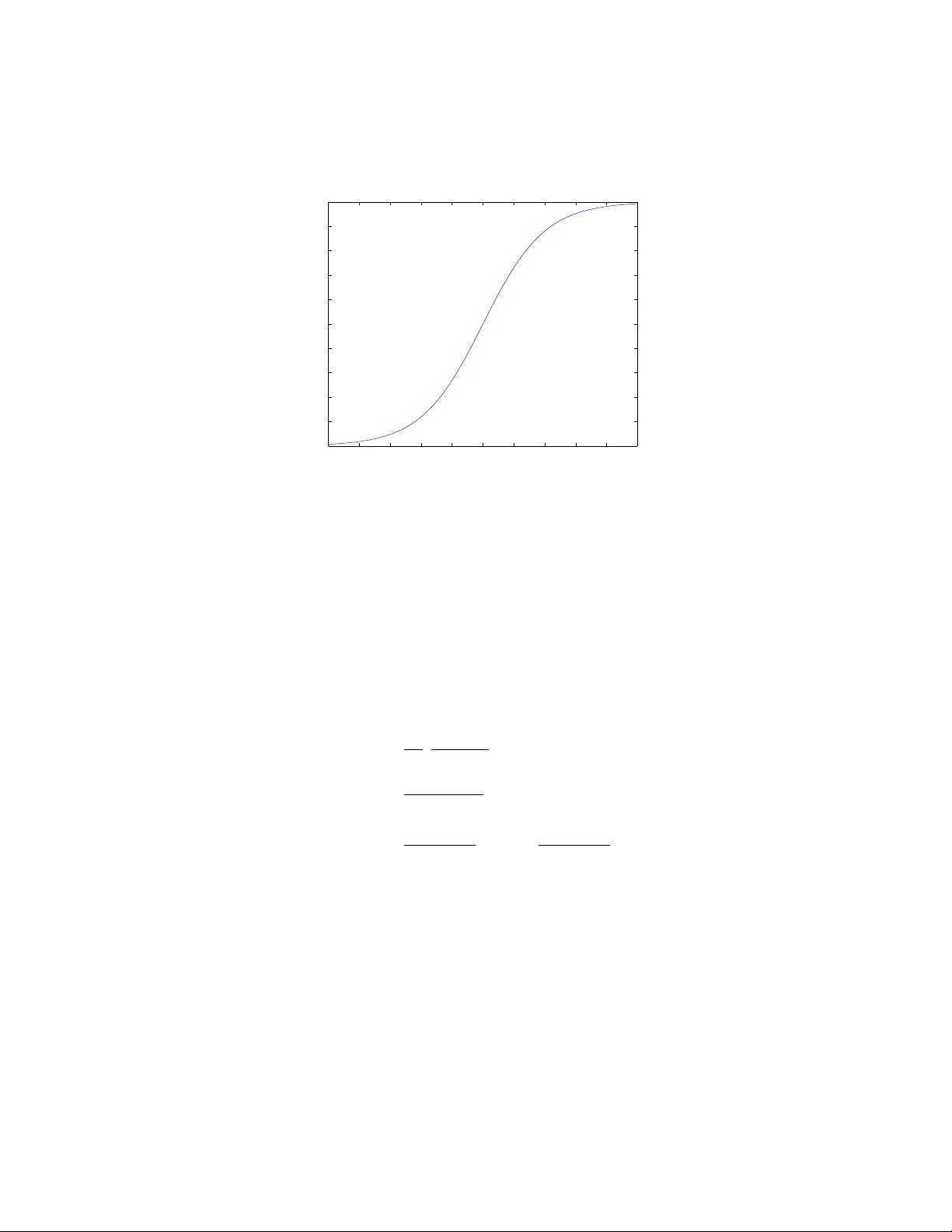
is called the logistic function or the sigmoid function. Here is a plot
showing g(z):



剩余219页未读,继续阅读
2017-12-05 上传
2017-11-24 上传
2019-06-07 上传
284 浏览量
2012-09-03 上传
2012-09-03 上传
2012-09-03 上传

zhongying_xjtu
- 粉丝: 3
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
