YOLOv5与YOLOv3训练自定义数据集全攻略
86 浏览量
更新于2024-06-17
收藏 5.15MB PDF 举报
"yolov5yolov3训练自己的数据集超详细"
本文将详细介绍如何使用YOLOv5和YOLOv3训练自定义数据集的过程。YOLO(You Only Look Once)是一种高效的实时目标检测算法,其最新版本YOLOv5在性能和易用性上都有显著提升。训练自己的数据集对于个性化应用或特定领域的物体检测至关重要。
一、环境配置
首先,要确保安装了正确的软件环境。推荐的配置包括tensorflow-gpu 2.3.0、cuda 10.1、cudnn 7.6.4、torch 1.9.0以及anaconda的python 3.8版本。安装过程中可以参考相关教程,如《Tensorflow-gpu2.1.0+cuda+cudnn+torch安装教程(超详细)》。
二、获取源代码
从GitHub上获取YOLOv5的官方代码,通常是通过克隆仓库完成。你可以访问YOLOv5论文的源代码仓库,选择“Code”选项下载ZIP文件。解压后,建议在单独的文件夹中保存YOLOv5工程代码,以便管理和维护。
三、调试源代码
在代码下载完成后,需安装项目依赖。打开`requirements.txt`文件并根据其中列出的库进行安装。安装完成后,使用Jupyter Notebook打开项目中的`tutorial.ipynb`文件。为了能在当前工程目录下运行Notebook,启动Notebook时需指定工程路径。
在Notebook中,你需要逐行执行代码进行调试。在确保环境配置正确无误的情况下,可以注释掉前几行初始化代码,继续运行后续部分。如果遇到找不到预训练模型`yolov5s.pt`的问题,需要下载这个模型权重文件到相应目录,或者修改代码中的路径指向权重文件的正确位置。
四、数据准备
训练自己的数据集,你需要准备标注好的图像数据。YOLO系列算法通常要求数据集遵循一定的格式,例如YOLO的`.txt`标注文件。每个文件对应一个图像,包含了图像中所有目标的边界框坐标和类别标签。确保每个目标都正确标注,并且数据集分为训练集和验证集。
五、配置文件
修改`config.yaml`配置文件以适应你的数据集。包括设置数据集路径、类别的数量、训练参数等。例如,修改`train`和`val`字段来指定数据集的路径,`nc`字段设置类别数量,`batch_size`和`img_size`则根据硬件资源和需求调整。
六、训练
配置完成后,使用`train.py`脚本来启动训练。命令行中输入相应的参数,如训练集路径、验证集路径、配置文件等。训练过程将生成模型权重文件,你可以定期保存模型以防止训练过程中断。
七、评估与测试
训练结束后,使用`test.py`脚本对模型进行验证和测试。这将计算模型在测试集上的性能指标,如平均精度(mAP)、召回率等。还可以使用`inference.py`来实时检测新的图像或视频。
八、微调与优化
如果模型表现不尽人意,可以通过调整超参数、增加训练迭代次数或进行数据增强来优化模型。数据增强可以帮助模型更好地泛化,提高在新数据上的表现。
九、部署
最后,当模型达到满意的效果后,可以将其部署到实际应用中。这通常涉及模型的轻量化、转换成其他框架(如TensorRT)或集成到现有系统。
通过以上步骤,你应该能够成功地利用YOLOv5或YOLOv3训练自己的数据集,并实现定制化的物体检测解决方案。记住,训练过程可能需要反复调整和优化,耐心和实践是关键。
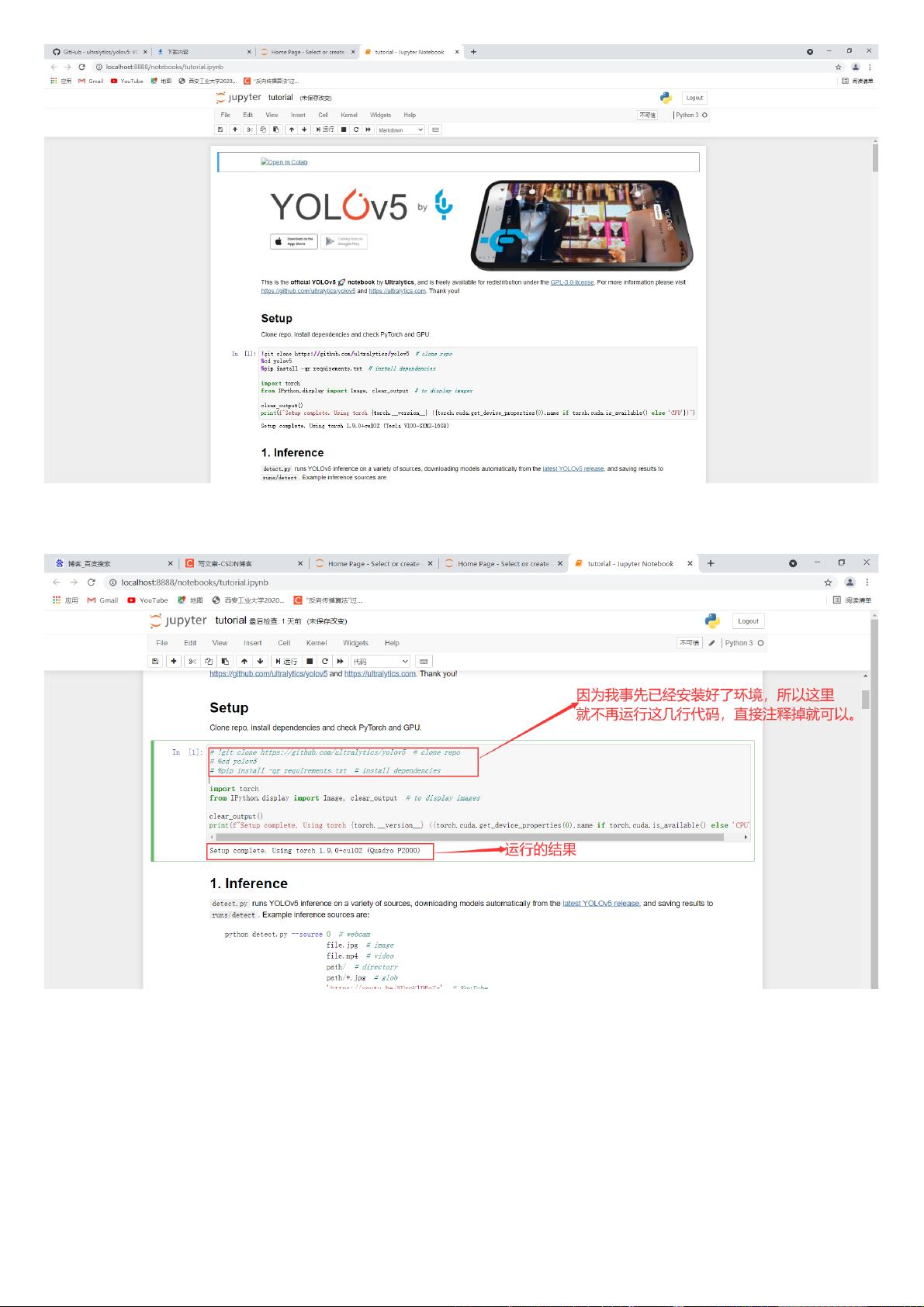
然后按照官⽹的要求进⾏代码调试。如果⼤家事先安装好了环境,并且按照上⾯的步骤打开tutorial.ipynb⽂件,可以注释掉前三⾏代码,
然后运⾏后⾯的代码即可。具体如下图所⽰:
剩余24页未读,继续阅读
2602 浏览量
340 浏览量
4404 浏览量
257 浏览量
248 浏览量
2023-09-16 上传
142 浏览量
233 浏览量
2023-10-18 上传


emma20080101
- 粉丝: 1081
 我的内容管理
展开
我的内容管理
展开







最新资源
- 光盘坏轨专家2.0:实现光盘加密技术新突破
- TG-UV2对讲机写频软件全新升级使用指南
- C#实现的微服务账户管理器
- 定时启动程序V2.1:网页、程序、DOS命令三重启动
- 6种皮肤可选的jQuery悬浮滚动QQ客服代码
- gc-viz:动画可视化垃圾收集算法
- 探索spammer工具:用于收集受损电子邮件地址的方法
- 探索ASKBOT:基于CNPROG的问答网站开源程序
- 基于FFmpeg和SDL的音视频同步技术解析
- HTML5轮播图交互功能实现详解
- KNN模型与k倍交叉验证的性能评估方法
- 服务器内存实时释放的SQL内存自动清理工具
- 原生JSON基准测试:C/C++库性能深度评测
- DirectShow简易播放器开发:无需额外编解码库
- Virtuoso框架:搭建跨平台聊天机器人的简易方案
- C# WebSocket开发实例详解
