Java虚拟机JVM调优:数据类型、堆栈和面向对象
JVM调优总结
在Java虚拟机(JVM)中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。
基本类型包括:byte, short, int, long, char, float, double, Boolean, returnAddress等。这些类型的变量直接存储数值,而不是对象的引用。
引用类型包括:类类型,接口类型和数组。这些类型的变量存储的是对象的引用,而不是对象本身。
在JVM中,堆和栈是程序运行的关键。栈是运行时的单位,而堆是存储的单位。栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
在Java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关信息的。包括局部变量、程序运行状态、方法返回值等等;而堆只负责存储对象信息。
为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?有四个主要的原因:
第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。
因此,在JVM中,数据类型的分类、堆和栈的分离都是非常重要的概念,它们是JVM调优的基础。只有正确地理解了这些概念,才能更好地优化JVM的性能。

串行收集:串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,
实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器
的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量
(100M 左右)情况下的多处理器机器上。
并行收集:并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且
理论上 CPU 数目越多,越能体现出并行收集器的优势。
并发收集:相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,
需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时
会有明显的暂停,而且暂停时间会因为堆越大而越长。
JVM调优总结(四)-垃圾回收面临的问题
博客分类:
java路上
JVM算法多线程面试JNI
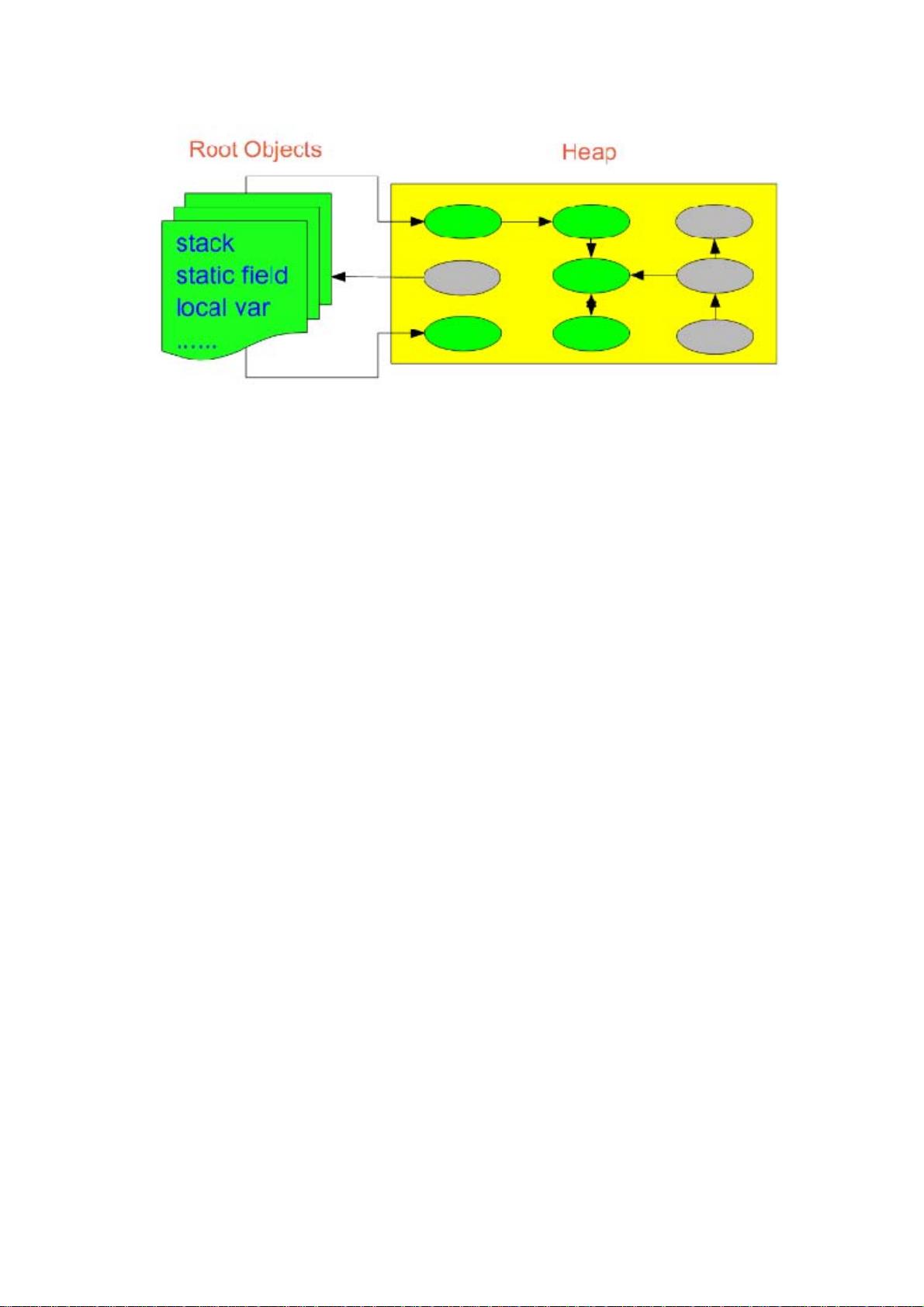
如何区分垃圾
上面说到的“引用计数”法,通过统计控制生成对象和删除对象时的引用数
来判断。垃圾回收程序收集计数为 0 的对象即可。但是这种方法无法解决循环引
用。所以,后来实现的垃圾判断算法中,都是从程序运行的根节点出发,遍历整
个对象引用,查找存活的对象。那么在这种方式的实现中,垃圾回收从哪儿开始
的呢?即,从哪儿开始查找哪些对象是正在被当前系统使用的。上面分析的堆和
栈的区别,其中栈是真正进行程序执行地方,所以要获取哪些对象正在被使用,
则需要从 Java 栈开始。同时,一个栈是与一个线程对应的,因此,如果有多个
线程的话,则必须对这些线程对应的所有的栈进行检查。
剩余44页未读,继续阅读
2020-07-27 上传
2015-06-23 上传
2018-08-25 上传
2020-06-04 上传
2019-06-20 上传
2012-06-10 上传

lxd04603
- 粉丝: 4
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- chatterbox-client
- AlarmClock:使用wifi同步时间的闹钟
- Gaim OSD Plugin-开源
- GeoProxy-crx插件
- SAD
- PI_SNR.zip_matlab例程_Visual_C++_
- torch_scatter-2.0.7-cp37-cp37m-linux_x86_64whl.zip
- NanoSQUID-数据分析软件
- media-queries-and-responsive-design
- Cold BBS-开源
- tmgl.zip_Java编程_Java_
- scale-practice
- rpc:测试rpc服务
- 我的elasticsearch:我学习elasticsearch
- Free Fraud Detection and Prevention-crx插件
- torch_sparse-0.6.12-cp37-cp37m-macosx_10_14_x86_64whl.zip
