北大NLP课程:互联网数据挖掘概述,探索Web挖掘与应用
版权申诉
201 浏览量
更新于2024-07-04
收藏 3.79MB PDF 举报
《互联网数据挖掘课程 - 自然语言处理系列课程 第01章 互联网挖掘概述概要》是针对自然语言处理领域的入门或复习课程,旨在让学生掌握互联网数据挖掘的基础知识。本章主要介绍了以下几个核心知识点:
1. 互联网数据规模:课程强调了互联网的飞速发展,指出全球Web网站数量超过10亿,页面数量接近千亿,数据总量估计达到10万亿GB,表明互联网已成为重要的信息源。
2. Web特点:讲解了Web数据的特性,如数量巨大、类型多样(包括结构化、半结构化和非结构化数据)、链接丰富形成图结构、支持跨平台显示、动态更新、交互性强、信息冗余和噪声问题等。
3. Web数据类型:列举了不同类型的数据,如内容数据(新闻文本、博客、微博)、结构数据(表格、暗网)、用户档案数据、以及日志数据和多媒体信息。
4. Web挖掘任务:定义了Web挖掘的范畴,即通过数据挖掘技术从Web数据中提取有价值的信息和知识,如隐含模式和关系,目的是为了改善检索效果、创造新知识、理解用户行为和满足个性化需求。
5. 相关技术:课程提到了几个关键领域与Web挖掘的关系,包括Web搜索、数据挖掘、自然语言处理、信息检索以及机器学习。列举了一些重要的学术会议,如SIGIR、WWW、KDD等,展示了研究机构如高校和企业的活跃度。
6. Web挖掘应用示例:涵盖了搜索与推荐、舆情与情报分析、未来预测、机器翻译、问答与对话等多个实际场景的应用,如垂直搜索、产品搜索、个性化推荐、舆情监测和情报分析等,并举出了如2013年奥斯卡预测这样的实例。
通过本章的学习,学生将对互联网数据挖掘的基本概念、技术和应用有深入的理解,为进一步深入学习后续章节如信息检索、自然语言处理和数据挖掘打下坚实基础。课程提供全面的资源下载链接,方便学习者获取完整的学习资料。
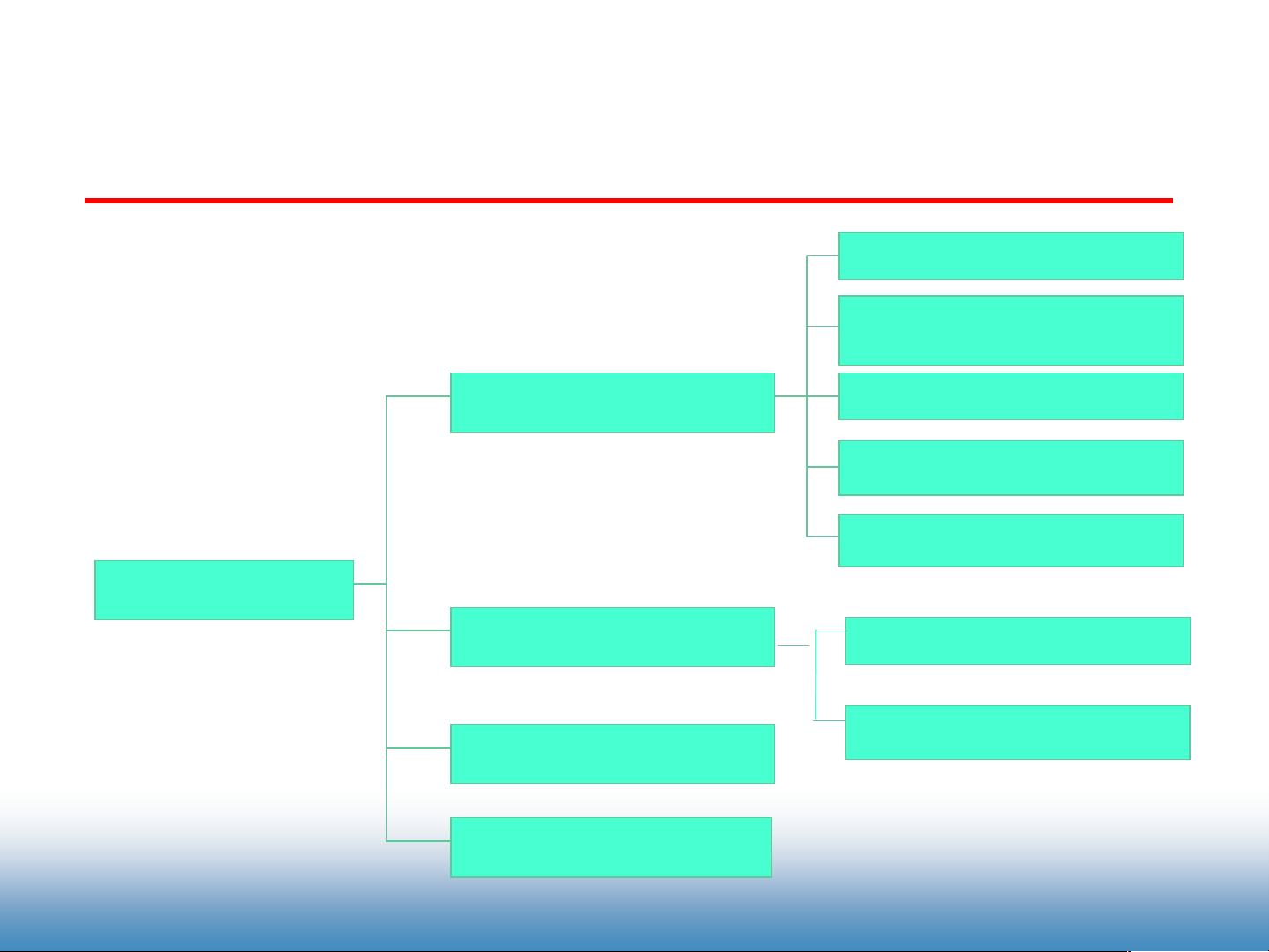
Web数据类型
7
互联网数据
内容数据
结构数据
使用(日志)数据
用户档案数据
新闻文本
半结构化数据(HTML、
XML)
图像、视频、音频
结构化数据(表格、暗网)
博客、微博等
网页链接结构
社交网络关系
剩余39页未读,继续阅读
159 浏览量
2025-01-06 上传
2025-01-06 上传

passionSnail
- 粉丝: 469
- 资源: 7836
 我的内容管理
展开
我的内容管理
展开







最新资源
- 电力负荷和价格预测网络研讨会案例研究:用于日前系统负荷和价格预测案例研究的幻灯片和 MATLAB:registered: 代码。-matlab开发
- SHC公司供应商商行为准则指南
- QtCharts_dev_for_Qt4.8.6.zip
- 一款具有3D封面转动的效果
- selectlist:非空列表,其中始终仅选择一个元素
- ktor-permissions:使用身份验证功能为Ktor提供简单的路由权限
- 数据库课程设计---工资管理系统(程序+源码+文档)
- comparison_of_calbration_transfer_methods.zip:三个数据集校准传递方法的比较-matlab开发
- APQP启动会议
- NLW-后端:后端应用程序级别下一个星期NLW01 Rocktseat
- javascript-koans
- Información Sobre los Peces-crx插件
- COMP9102:COMP9102
- 第三方物流与供应链及成功案例课件
- squeezebox_wlanpoke_plot
- 学习Android Kotlin核心主题
