KMeans算法深度解析:从概念到实现
"大数据十大经典算法讲解,包括Kmeans算法的详细介绍,从概念到实践,以及其在大数据处理中的应用。"
在大数据领域,算法起着至关重要的作用,尤其是对于数据挖掘和分析。其中,Kmeans算法是最常用且基础的聚类算法之一,适用于大量数据的分类和分析。这个算法简单易懂,广泛应用于市场分割、图像分割、文本分类等多种场景。
Kmeans算法的核心思想是通过迭代找到数据集中的聚类中心,将数据点分配到与其最近的聚类中心所属的类别,然后更新聚类中心为该类别所有点的均值,直到聚类中心不再发生变化或者达到预设的迭代次数为止。
算法流程如下:
1. 初始化:随机选择K个数据点作为初始聚类中心。
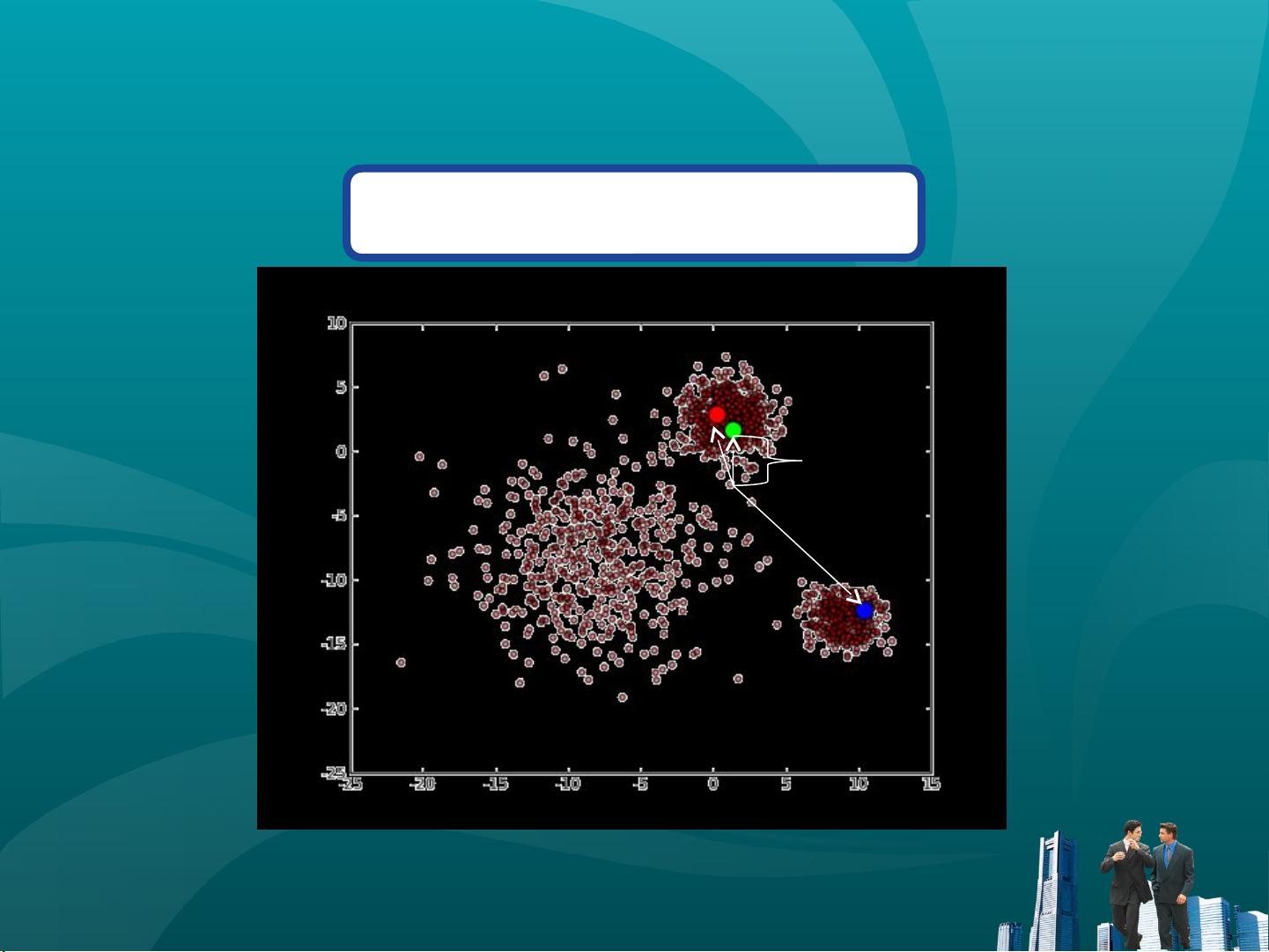
2. 分配数据点:计算每个数据点到K个聚类中心的距离,按照距离最近的原则将数据点分配到对应的簇。
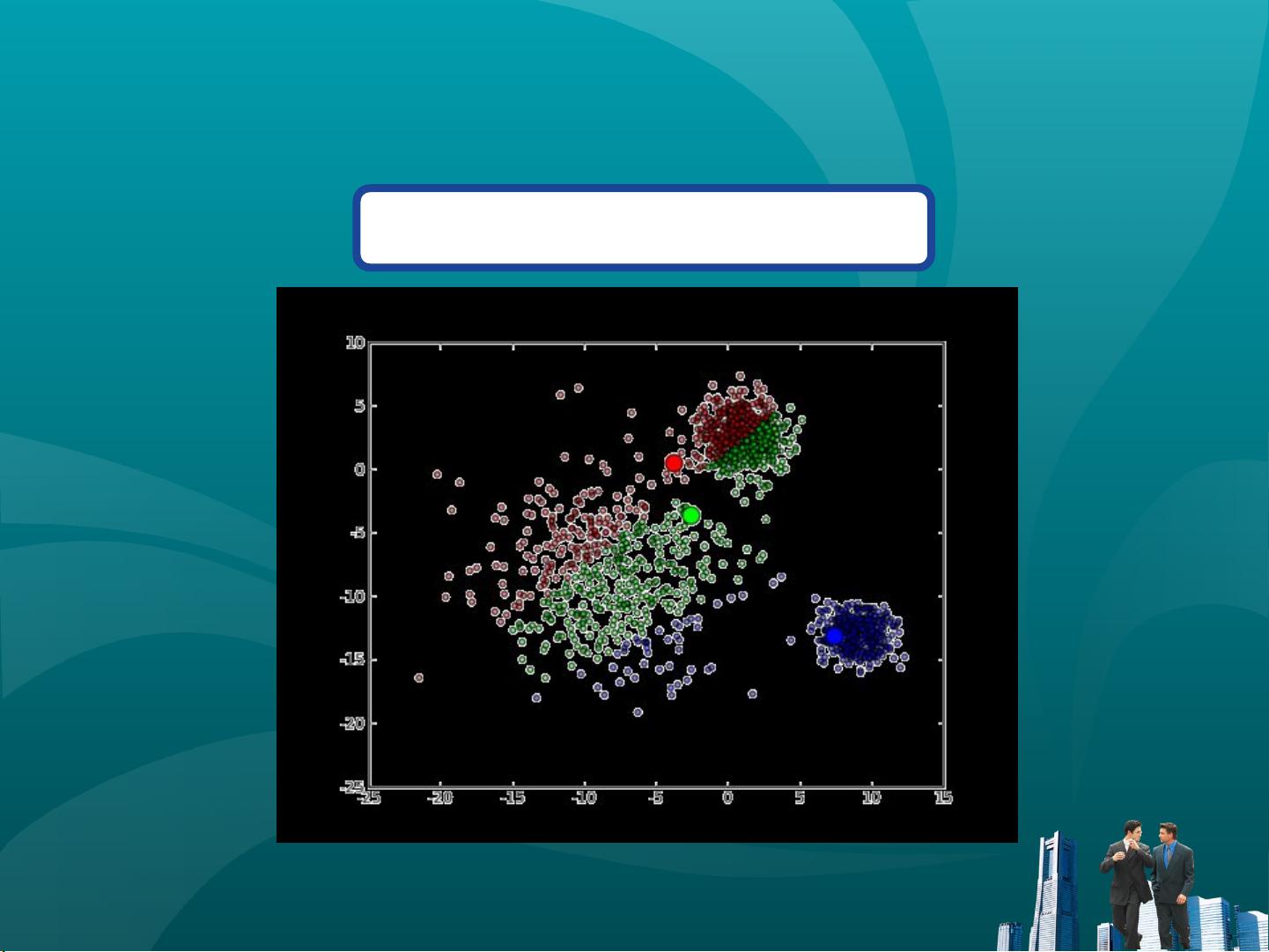
3. 更新中心:重新计算每个簇的几何中心(即所有点的均值),作为新的聚类中心。
4. 迭代:重复步骤2和3,直至聚类中心不再改变或达到最大迭代次数。
5. 结束:当满足停止条件时,算法结束,得到最终的聚类结果。
Kmeans算法的优势在于其效率高,适合大规模数据处理,但也有其局限性:
- 对初始中心点的选择敏感:不同的初始点可能导致不同的聚类结果。
- 需要预先设定K值:确定类别数量可能较为困难,过少可能丢失信息,过多则可能导致过拟合。
- 假设数据分布为凸形:如果数据分布不规则,Kmeans可能无法有效聚类。
- 不适用于非凸形状或大小差异大的簇。
- 对异常值敏感:异常值可能会显著影响聚类中心的位置。
为克服这些缺陷,有许多改进的Kmeans算法,如Elkan算法利用三角不等式减少距离计算,或者采用更灵活的DBSCAN(基于密度的聚类算法)来发现任意形状的簇。
在大数据处理中,Kmeans通常会结合分布式计算框架如Hadoop或Spark进行优化,以处理海量数据。例如,可以使用Spark的MLlib库实现分布式Kmeans,提高计算速度和并行化能力。
Kmeans是大数据分析中的基础工具,虽然存在一些限制,但通过不断优化和与其他算法结合,仍能在各种实际问题中发挥重要作用。了解和掌握Kmeans算法及其变种,对于理解和应用大数据技术至关重要。
Kmeans
Kmeans
算法详解(
算法详解(
2
2
)
)
Min of three
due to the
EuclidDistance
步骤二:把每个点划分进相应的簇
剩余32页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-23 上传
2022-11-21 上传
2022-11-13 上传
2022-11-15 上传
2022-05-29 上传

abigwhiteshark
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
